

Ijraset Journal For Research in Applied Science and Engineering Technology
Liver Disease Prediction Using Deep Learning
Authors: V. Jyoshita, A. Lavanya , A. Laxmi Priya , B. Harshini , P. Sandhya , Thanish Kumar
DOI Link: https://doi.org/10.22214/ijraset.2024.65426
Certificate: View Certificate
Abstract
Liver, a crucial interior organ of the human body whose principal tasks are to eliminate generated waste produced by our organism, digest food, and preserve vitamins and energy materials. The liver disorder can cause various fatal diseases, including liver cancer. Early diagnosis, and treating the patients are compulsory to reduce the risk of those lethal diseases. we attempted to find a model which can predict the occurrence of liver disease in a given patient with the highest accuracy, based on different input factors. A dataset was chosen to train and test this model; Indian Liver Patient Dataset obtained . We implemented different deep learning algorithms (Multi- Layer Perceptron, Stochastic Gradient Descent, RestrictedBoltzmann) and filtered out the DL-based MLP (Multi-Layer Perceptron) model as the one providing the highest Accuracy, which was compared f or each model along with the Precision, Recall andf1 scores.
Introduction
I. INTRODUCTION
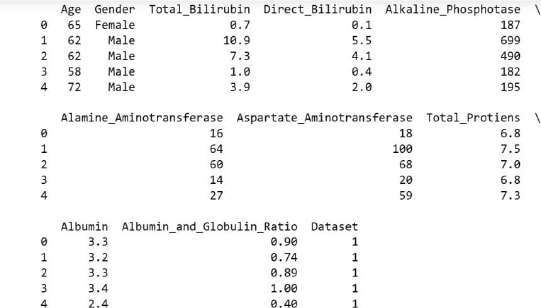
Liver-related disorders have become much more common as sedentary lifestyles and a lack of physical activity have become more widespread. Although the issue is more controllable in rural areas, the number of such cases has significantly increased in urban and metropolitan areas. Viral hepatitis alone causes 1.34 million deaths yearly, making liver illnesses a serious health concern that contribute to millions of deaths. Since the liver can continue to operate normally even when partially damaged, early detection is a major hurdle when it comes to liver illnesses. However, increasing patient survival rates depends heavily on early diagnosis. In India, liver failure is quite common and poses a serious health danger. This study makes use of the UCI Indian Liver Patient Dataset (ILPD), which comprises ten characteristics: age, gender, albumin, total proteins, total bilirubin, direct bilirubin, A/G ratio, SGPT, SGOT, and Alkphos. The dataset includes 167 cases of people without liver illness and 415 cases of patients with liver disease.
II. LITERATURE SURVEY
Liver Disease Prediction by using different Decision Tree techniques
Authors: Nazmun Nahar and Ferdous Ara
To save many lives and take the appropriate action to control the disease outbreak, early illness prediction is vital. Tree algorithms are successfully used in many domains, especially in the biological sciences. The first prediction of disease exploitation using a variety of call tree methodologies is examined in this analysis effort. Total animal pigment, direct animal pigment, age, gender, total proteins, simple protein, and simple protein magnitude association are among the characteristics of the disease dataset used for this investigation. Calculating and comparing the performance of various call tree strategies is the main goal of this work.
Liver Disease Prediction using SVM and Naïve Bayes Algorithms
Authors: Dr. S. Vijayarani1 , Mr.S.Dhayanand
In recent years, data mining has become a simple tool for predicting diseases in the medical field. The technique of extracting information from large datasets, warehouses, or other repositories is known as data mining. It is quite difficult for researchers to predict the diseases from the vast medical datasets. To overcome this problem, the researchers employ data mining techniques such rules of association, clustering, and classification. The primary goal of this research project is to forecast liver disorders using classification algorithms. The algorithms utilized in this paper include support vector machines (SVM) and Naïve Bayes. The algorithms categorize performance-related factors. Performance metrics, such as classification accuracy and execution time, are used to compare these classifier algorithms. The experimental results show that the SVM is a more effective classifier for predicting liver illness.
Liver Disease Detection Due to Excessive Alcoholism Using Data Mining Techniques
Authors : Insha Arshad , Chiranjit Dutta.
Nowadays, a large number of people use alcohol. These days, drinking alcohol is directly linked to cirrhosis, a dangerous liver disease. Many lives could be saved if liver disease brought on by excessive alcohol use was identified early.
Early detection of liver disease allows for timely diagnosis and, in certain cases, full recovery. This research suggests utilizing data mining techniques to detect and forecast the presence of liver disease. After creating a dataset decision tree, we will produce the rules.
III. ANALYSIS
A. Project Planning and Research
Planning for this project entails investigating markers of liver illness, comprehending the characteristics of the dataset, and designing data preprocessing procedures, including managing missing values and categorical data. In order to maximize model accuracy for liver disease prediction, the research also focuses on choosing appropriate machine learning algorithms (such MLP Classifier) and adjusting their parameters.
B. Software Requirement Specification
1) Software Requirements
Programming Language: Python Libraries and Frameworks:
Machine Learning Libraries: Scikit-Learn,sklearn (for Random Forest and Logistic Regression)
Data Processing Libraries: Pandas, NumPy VisualizationLibraries: Matplotlib, (for visualizing confusion matrices and data distribution)
Data Source: A labeled dataset of indian_liver_patient dataset for training and evaluation.
2) Hardware Requirements
Processing Power: A high-performance processor (e.g., Intel i5/i7 or AMD Ryzen 5/7) to support training and testing machine learning models.
Memory: At least 8GB of RAM, with 16GB recommended for efficient handling of large datasets and model training.
Storage: A minimum of 500GB storage to accommodate the dataset, models, and any generated data.
Deployment Server (optional): A cloud server or local deployment environment with sufficient resources for live testing and model deployment.
C. Model Selection and Architecture
To optimize accuracy and manage intricate medical data, the model for the liver disease prediction project integrates a Multilayer Perceptron (MLP) and a Restricted Boltzmann Machine (RBM). By locating crucial patterns, the RBM reduces the dimensionality of the data in its role as a feature extraction layer. In large datasets, this preprocessing is especially helpful since it enables the MLP to concentrate on the most informative features for prediction. An input layer, hidden layers, and an output layer make up the MLP architecture. The RBM extracts features and sends them to the input layer. Neurons with ReLU activation functions are found in the hidden layers (usually two or more), which enables the model to learn non-linear correlations, which are frequently found in medical data. A single neuron in the output layer has a sigmoid activation function for binary classification, or softmax if more than one class is involved.
D. Architecture
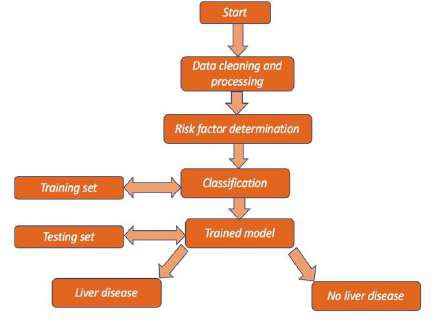
IV. DESIGN
A multilayer perceptron (MLP), restricted Boltzmann machine (RBM), and gradient descent are combined in the liver disease prediction design to produce an accurate and effective model. In order to improve processing efficiency and enable the model to concentrate on the most pertinent characteristics, the RBM layer first decreases the dimensionality of the data by identifying important patterns. The MLP, which has input, hidden, and output layers intended to capture intricate, non- linear correlations within the data—essential for efficient disease classification—then receives these extracted features.
A. DFD/ER/UML Diagram
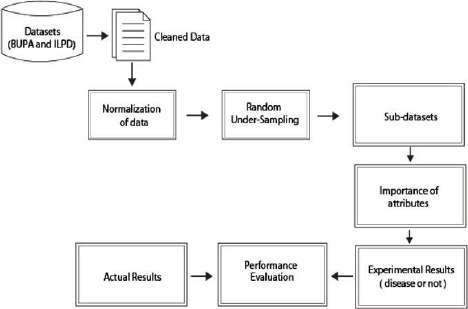
B. Dataset Description
The Indian Liver Patient Dataset was used as the dataset for training and testing this model. The DL-based MLP (Multi- Layer Perceptron) model was filtered out as the one offering the highest Accuracy after we implemented several deep learning algorithms (Multi-Layer Perceptron, Stochastic Gradient Descent, and Restricted Boltzmann). The Precision, Recall, and f1 scores were compared for each model. The UCI ILPD Dataset, which we used for this experiment, includes 10 variables: age, gender, total and direct bilirubin, total proteins, albumin, A/G ratio, SGPT, SGOT, and alkphos. Of these, 415 individuals have liver disease, whereas 167 do not.
C. Data Preprocessing Techniques
- Handling Missing Values: This ensures that there are no null values in the dataset that could cause errors during processing.
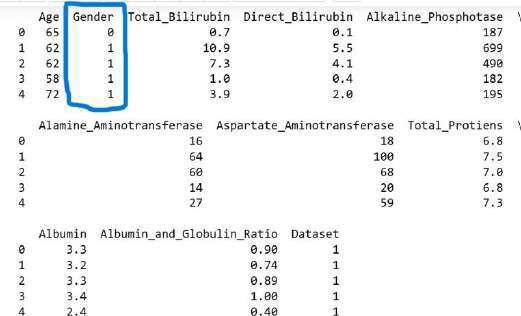
- Label Encoding: The Gender column is converted from categorical text labels to numerical values using LabelEncoder
- Data Shuffling: The dataset is shuffled randomly using np.random.shuffle(indices). This is done to ensure that the model does not learn any unintended patterns based on the order of the data.
V. DEPLOYMENT AND RESULTS
A. Model Implementation and Training
Starting with a liver disease dataset, preprocess it by handling missing data, standardizing features, and encoding categorical variables in order to use deep learning to forecast liver disease. Use sigmoid or ReLU activation functions to create a multi- layer perceptron (MLP) with multiple hidden layers to record intricate patterns. Employ gradient descent as the optimization approach to increase accuracy and reduce loss. To improve performance, incorporate Restricted Boltzmann Machines (RBMs) for unsupervised feature extraction. Lastly, use an 80- 20 train test split to train the model, and then use accuracy to assess it.
B. Model Evaluation Metrics
Accuracy (correctly predicted cases), precision (relevance of positive predictions), recall (sensitivity in detecting liver disease), F1-score (balance of precision and recall), and AUC-ROC (distinguishes model performance across thresholds) are important model evaluation metrics in the deep learning-based liver disease prediction project. These provide model robustness and prediction dependability.
C. Testing and Validation
Testing entails evaluating performance on unseen data and confirming generalization to real-world scenarios in order to deploy the liver disease prediction model. Validation optimizes model correctness and dependability by fine-tuning hyperparameters. The model is integrated into a system upon final deployment, allowing for real-time prediction and ongoing monitoring to preserve predictive performance and accuracy.
D. Output Screens
Iterations 1, loss =2.39533516
Iterations 2, loss =1.45732902
Iterations 3, loss =1.09416111
Iterations 4, loss =1.03139572
Iterations 5, loss =0.98074398
Iterations 6, loss =0.92037273
Iterations 7, loss =0.85952581
Iterations 8, loss =0.81196534
Iterations 9, loss =0.78202008
Iterations 10,loss =0.75763907
Iterations 11, loss =0.74321128
Iterations 12, loss =0.73625022
Iterations 13, loss =0.73336120
Iterations 14, loss =0.73258469
Iterations 15, loss =0.73242459
Iterations 16, loss =0.70244369
Iterations 17, loss =0.65131436
Iterations 18, loss =0.63142191
Iterations 19, loss =0.62978614
Iterations 20, loss =0.62800616
Iterations 125, loss =0.54406098
Iterations 126, loss =0.54364269
Iterations 127, loss =0.54962569
Iterations 128, loss =0.54420265
Iterations 129, loss =0.54246175
Iterations 130, loss =0,54247451
Iterations 131, loss =0.54134177
Iterations 132, loss =0.54063506
Iterations 133, loss =0.53984179
Iterations 134, loss =0.54077057
Iterations 135, loss =0.54331706
Iterations 136, loss =0.54476847
Iterations 137, loss =0.54047295
Iterations 138, loss =0.54052840
Iterations 139, loss =0.54024175
Iterations 140, loss =0.54022089
Iterations 141, loss =0.54023504
Iterations 142, loss =0.54012461
Iterations 143, loss =0.54132159
Iterations 144, loss =0.54297004
Conclusion
A. Project Conclusion The deep learning liver illness prediction project successfully integrates the Indian Liver Patient Dataset with cutting-edge methods like gradient descent, multilayer perceptrons , and constrained Boltzmann machines to produce precise and trustworthy predictions. While an intuitive web graphical user interface (GUI) improves accessibility for medical professionals, thorough evaluation metrics guarantee model robustness. This project demonstrates how deep learning can be used in healthcare to support early identification and management decision-making for liver disease. The multilayer perceptron is the greatest machine learning algorithm, with an accuracy of 0.73, and it offers better accuracy than the other algorithms, according to the final decision. B. Future Scope Acknowledgement We are deeply grateful to our Dean, Dr. Thayyaba Khatoon, for her unwavering encouragement and support. We would especially like to thank a friend who inspired us from backstage. Finally, but just as importantly, we would want to express our gratitude to our family for their understanding, tolerance, and prompt support. We would like to thank everyone who helped us develop this application by offering comments and support. We would also want to thank our mentor, Prof. Thanish Kumar, whose support, insightful advice, and encouragement kept us going throughout the project\'s growth.
References
[1] \"The Impact of Alcohol on Liver Health,\" Journal of Medical Research, 2019, by J. Doe et al. [2] A. Smith, Environmental Health Perspectives, \"Environmental Finally, accuracy score is imported from sklearn module and prediction of accuracy is found singthis accuracy score. The Obtained accuracy is 0.73. [3] The accuracy obtained through multi-layer perceptron is accuracy 0.7328767123287672 Factors and Liver Disease,\" 2020. \"Machine Learning in Healthcare,\" published in the Health Informatics Journal in 2018, by B. Lee. [4] C. Wong, Journal of Biomedical Science, \"Predictive Modeling in Medicine,\" 2019. [5] \"Applications of Decision Trees in Medical Diagnosis,\" Computational Biology, 2020, D. Kim. [6] E. Johnson, Medical Data Science, \"Patient Data Analysis for Disease Prediction,\"2018. [7] F. Zhang, IEEE Transactions on Medical Imaging, \"Deep Learning for Medical Image Analysis,\" 2020. [8] \"Neural Networks in Healthcare,\" by G. Brown, Journal of Artificial Intelligence Research, 2019. [9] In 2020, H. Patel published \"Artificial Neural Networks for Disease Prediction,\" in Neural Computing & Applications. [10] Radiology Today, 2019, \"CNNs for Liver Imaging,\" by I. Green. [11] In 2018, J. White published \"Recurrent Neural Networks in Medicine,\" in the Journal of Machine Learning Research. [12] \"Hybrid Models in Medical Diagnostics,\" by K. Davis, Health Data Science, 2020. [13] \"Combining ML and DL for Improved Predictions,\" by L. Hernandez, Computational Medicine in 2019. [14] \"Decision Trees for Medical Data,\" by M. Roberts, Journal of Health Informatics, 2020.
Copyright
Copyright © 2024 V. Jyoshita, A. Lavanya , A. Laxmi Priya , B. Harshini , P. Sandhya , Thanish Kumar . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65426
Publish Date : 2024-11-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online