

Ijraset Journal For Research in Applied Science and Engineering Technology
Comparative Analysis of Machine Learning Algorithms for Text-based Phishing Detection
Authors: Dr. Pundalik Chavan, Hassan Yakub Sait, Hemanth P, Jonathan S Paul, Justin A Deodhar
DOI Link: https://doi.org/10.22214/ijraset.2024.60366
Certificate: View Certificate
Abstract
Phishing is a major threat to personal and organizational security. The risks associated with phishing have increased as cyber criminals devise more convincing methods to deceive their targets. Deceptive emails can often result in the compromise of personal information, accounts, financial loss and reputational damage. This paper explores how certain commonly used machine learning algorithms perform in detecting malicious emails based on the text alone. The algorithms analyzed are Support Vector Machines (SVM), Naive Bayes (NB) and Logistic Regression (LR). The paper compares the performance of these algorithms based on various factors such as accuracy, precision and recall. It also compares the performance of a voting approach with the algorithms.
Introduction
I. INTRODUCTION
In the digital age, communication through email has become an integral part of our personal and professional lives. However, the convenience and efficiency offered by email also attract malicious actors seeking to exploit vulnerabilities for various purposes, easily catching unsuspecting users off-guard.
Phishing attacks have become a major threat with cyber criminals attempting to steal user data or credentials using either malicious software or social engineering [1]. As these threats continue to evolve in sophistication, traditional email security measures often struggle to keep pace. This has led to the exploration of advanced solutions, with machine learning emerging as a powerful tool in fortifying email security.
Phishing attacks, disguised as legitimate communications, exploit human psychology in order to breach security barriers. Whether through deceptive emails, fraudulent website links or malicious messages, attackers seek to compromise sensitive data, posing a significant risk to individuals and organizations alike. As these attacks evolve in intricacy, the need for advanced and adaptive defenses becomes increasingly apparent. With the evolution of machine learning and rise in popularity of Large Language Models (LLMs) [2], it has become a lot easier to generate personalized messages to targets in bulk.
The exploration of machine learning techniques, such as Support Vector Machines, Naive Bayes, and Logistic Regression, within the realm of Natural Language Processing (NLP), forms the core of this analysis. The paper aims to evaluate the performance of these algorithms in detecting commonly used language in phishing campaigns, providing a comprehensive understanding of their strengths and limitations. Through this analysis, we seek to contribute to the ongoing efforts to develop robust systems against phishing, thereby strengthening the resilience of individuals and organizations in the face of evolving cyber threats.
II. LITERATURE REVIEW
Here we provide a brief literature on the various machine learning algorithms that were used in comparisons or analyzed individually for the purpose of spam or phishing detection.
A. A comparison of Machine Learning Techniques for Phishing Detection
The paper [3] compared the predictive accuracy of machine learning techniques such as Logistic Regression (LR), Random Forests (RF), Bayesian Additive Regression Trees (BART) and Support Vector Machines (SVM). Each email in the dataset used was converted into a vector corresponding to 43 different features, all of which had continuous values. The preprocessing stage involved removing stopwords and stemming. The most common terms in the corpus were then chosen. For training and testing 10-fold cross-validation was used and averaged to attain the mean error rate for each of the classifiers. The paper concluded that RF performed the best in terms of having the lowest error rate of 7.72%, while also having the worst false positive rate of 8.29%. In comparison, the Neural Networks (NNet) classifier had an error rate of 10.73%, performing the worst among the classifiers.
B. Improved Email Spam Detection Model based on Support Vector Machines
In the paper [4], a model based on Support Vector Machines (SVM) was proposed and compared against other classifiers such as Bayesian Additive Regression Trees (BART), Particle Swarm Optimization (PSO) and Negative Selection Algorithm (NSA). It utilized a systematic parameter search algorithm to help achieve better accuracy in the classification. The dataset used had 57 features or attributes. The model’s implementation was carried out in a MATLAB 2012b environment. The proposed classifier was able to achieve an accuracy of 94.06%, outperforming the other classifiers by 3% or more. The paper concluded that a simpler standalone system could outperform a hybrid system through the use of systematic optimization.
C. Email Spam Detection using Machine Learning Algorithms
The paper [5] applied and compared the performance of classic classifiers such as Naive Bayes Classifier (NVC), Support Vector Classifier (SVC), Decision Tree (DT) and K-Nearest Neighbor neighbour (KNN), along with ensemble learning methods such as Random Forest Classifier (RFC), Bagging Classifier (BC) and AdaBoost Classifier (ABC). The data preprocessing stage of the research included eliminating stop words, tokenizing and generating a bag of words. The comparison was based on the accuracy of the classifier. The paper concluded that NVC performed the best but also pointed out that its class-conditional independence posed a limitation with regards to the possibility of misclassifying certain tuples. It also mentioned the usefulness of ensemble methods due to their use of various classifiers.
In one paper [6], two new model-based features were developed and analyzed that managed to outperform basic features proposed in previous approaches. They applied the Dynamic Markov chain compression to the phishing detection problem and proposed an adaptive training algorithm that reduced memory requirements by about two thirds. In another related work [7], researchers proposed a general approach to a new rule-based method to detect phishing attacks by trying to determine the relationship between the contents of a web page and the url of that page. The method relied on SVM to classify and detect phishing pages. In it, they also propose two novel feature sets to increase the accuracy of web page classification. These feature sets were extracted from the contents of the web page without having to rely on search engines, browser history and/or black/white lists which made them language-independent.
III. METHODOLOGY
A. Dataset
The dataset used for training the models used in the comparison was taken from Kaggle [8]. It consists of 18634 records, each containing the body of an email along with its label of “Safe Email” or “Phishing Email.”
B. Data Preprocessing
The data used for training contained entries that had email addresses, links and sometimes even styling in the form of css. The data preprocessing stage included the separation of email addresses and links from each record along with the removal of css through the use of regular expressions. The email addresses, links and styling were replaced with text to indicate that they were initially present. Then each verb in the record was lemmatized to end up with the root word, after which the words were transformed to lower case to normalize it.
C. Training
For the purpose of training, a vectorizer was fitted on the entire dataset before then being used to vectorize each record. The train-test split was 13000 records to 5634 records. Each of the models were then trained on the training set and validated against the testing set. As for parameters for the models, the LR model’s ‘max_iter’ parameter was set to 900 and the SVM model’s ‘C’ parameter was set to 100. These values were selected as they performed the best out of a few training rounds. Each model was also trained on records without the preprocessing stage to compare its effect on the performance of the models.
For the voting classifier, three pretrained models (SVM, NB and LR) were used to predict the labels of 6000 randomly selected records from the dataset. If at least two models predicted that a record was phishing, it would be labeled as such. If not, it would be labeled as safe.
IV. RESULTS
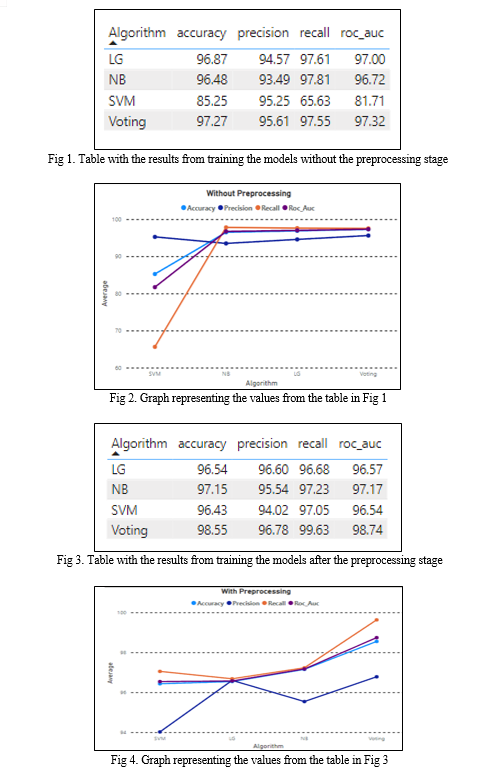
Here we provide the results of the analysis on the performance of the models based on their accuracy, precision, recall and area under the receiver operating characteristic curve (ROC AUC) [9]. The results are the average of 5 different training iterations. The train-test split was randomized for each iteration. In the case of the voting classifier, the 6000 selected records were randomized for each iteration. The three models used were, however, trained only once.
Conclusion
From our analysis, it is clear that the voting based classifier performed the best among the models used, achieving an accuracy of 98.55% when preprocessing was used before the predictions, beating the other models by 1.4% or more (when preprocessing was used). While the preprocessing stage didn’t make much of a difference in the LG and NB models, even decreasing the accuracy slightly in the case of the LG classifier, it seems to have played a big role in the performance of the SVM classifier, increasing its accuracy from 85.25% to 96.43% and its recall score from 65.63% to 97.05%. While the voting classifier performed well, it is important to note that its accuracy should be validated against other datasets as well. The models also don’t take into account other attributes present in emails such as addresses, links and attachments. Tools that tackle these should be used alongside the model to increase the robustness of the overall phishing detection system. LLMs, with some customization, would greatly improve such a system as they can have greater awareness regarding context, perform better text classification and can be used to analyze multiple emails from the same sender and not be limited to just one.
References
[1] Gupta, B.B., Tewari, A., Jain, A.K. et al. “Fighting against phishing attacks: state of the art and future challenges.” Neural Comput & Applic 28, 3629–3654, 2017. https://doi.org/10.1007/s00521-016-2275-y [2] Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Linyi Yang, Kaijie Zhu, Hao Chen, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, Wei Ye, Yue Zhang, Yi Chang, Philip S. Yu, Qiang Yang, and Xing Xie. 2024. “A Survey on Evaluation of Large Language Models,” ACM Trans. Intell. Syst. Technol, January 2024. https://doi.org/10.1145/3641289 [3] Saeed. Nimeh, Dario. Nappa, Xinlei. Wang and Suku. Nair, “A comparison of Machine Learning Techniques for Phishing Detection,” Proceedings of the anti-phishing working groups 2nd annual eCrime researchers summit (eCrime \'07). Association for Computing Machinery, New York, NY, USA, October 2007. https://doi.org/10.1145/1299015.1299021 [4] Sunday. Olatunji, “Improved email spam detection model based on support vector machines,” Neural Comput & Applic 31, 691–699, 2019. https://doi.org/10.1007/s00521-017-3100-y [5] N. Kumar, S. Sonowal and Nishant, \"Email Spam Detection Using Machine Learning Algorithms,\" Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2020. https://doi.org/10.1109/ICIRCA48905.2020.9183098 [6] Andr´e Bergholz, Gerhard Paaß, Frank Reichartz, Siehyun Strobel and Jeong-Ho Chang, “Improved Phishing Detection using Model-Based Features,” The Fifth Conference on Email and Anti-Spam, August 2008. [7] Mahmood Moghimi , Ali Yazdian Varjani, “New Rule-Based Phishing Detection Method,” Expert Systems With Applications, July 2016. https://doi.org/10.1016/j.eswa.2016.01.028 [8] Subhadeep Chakraborty. Phishing Email Detection [Data set]. Kaggle, 2023. https://doi.org/10.34740/KAGGLE/DSV/6090437 [9] Jin Huang and C. X. Ling, \"Using AUC and accuracy in evaluating learning algorithms,\" IEEE Transactions on Knowledge and Data Engineering, vol. 17, no. 3, pp. 299-310, March 2005, https://doi.org/10.1109/TKDE.2005.50
Copyright
Copyright © 2024 Dr. Pundalik Chavan, Hassan Yakub Sait, Hemanth P, Jonathan S Paul, Justin A Deodhar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60366
Publish Date : 2024-04-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online