

Ijraset Journal For Research in Applied Science and Engineering Technology
Machine Learning Approach for Spectral Signature Based Chemical Composition Analysis using Hyperspectral Data
Authors: Pravin V. Dhole, Vijay D. Dhangar, Sulochana D. Shejul, Prof. Bharti W. Gawali
DOI Link: https://doi.org/10.22214/ijraset.2023.55922
Certificate: View Certificate
Abstract
Number of techniques to identify falsified medications, including thin layer chromatography (TLC), analytical methods, eye examination, and the use of sophisticated labs with strong equipment and technical specialists. Such techniques take more time and call for sophisticated labs, specialized specialists in that field, and sample preparation. This research uses hyperspectral data to develop a spectral pattern for identifying falsified medications. Near infrared spectroscopic techniques are commonly used for this task because of their many advantages. For this research, we used the wide spectral range ASD Field Spec4 Spectroradiometer (350-2500 nm). We chose 43 solid pharmaceutical medicines from various brands for our task. The tablet powder has been altered by adding various amounts of calcium carbonate (CaCO3) to imitate falsified medicines. Then, we gather the spectral signature throughout all stages of contamination and use machine learning categorization methods to assess it. Partial least squares regression has a remarkable accuracy rate of 98.9% for hyperspectral data with NIR spectroscopy, while logistic regression, support vector machines, and random forests all provide accuracy of 75%. This hyperspectral data coupled with a database of pharmaceutical spectra creates a practical field-testing method to identify fake medications that is quick, simple to use, and requires no technological expertise.
Introduction
I. INTRODUCTION
Globally, technology and science are progressing rapidly in a variety of fields. There is an increase in the number of pharmaceutical medicinal products. Today’s life we are dealing with fake medicines in pharmaceutical tablets. The World Health Organization (WHO) has categorized fake medications as substandard and falsified medicinal items. Substandard medicines are low-quality products, commonly referred to as out-of-specification licensed medical products that do not meet their quality or specification criteria or both and falsified medicines is an illegally or incorrectly described as the actual product [1]. Falsified pharmaceutical medicine tablets may include no active component, the incorrect active component, or an insufficient amount of the proper active component. Tablets also often include maize starches, corn starch, or chalk. Many inferior and faked medical tablets were harmful to the body, including either deadly quantities of the incorrect active component or additional harmful substances. Poorly made and fake medical products are frequently manufactured in filthy and unsanitary settings by unlicensed individuals, include unidentified contaminants, and are occasionally infected with germs [2].
In India Central Drugs Standard Control Organization (CDSCO), the drug regulatory authority of India conducted the national survey in 2009 and collected 20,000 samples over the nation and tested them. It was found 11 samples or 0.046 % were spurious medicines and in 2017 again conducted that type of survey and he found that 0.0245% fake pharmaceuticals [3]. In 2013, the world health organization collected 1500 allegations of defective or fraudulent medicinal tablets. Antimalarials and antibiotics will be the most frequently mentioned. The WHO African Region generates the majority of the findings (42%), followed by the WHO Americas Region (21%), and the WHO European Region (21%) [4]. Medicines that passed their date expiry are sometimes remarked with a false date or relabelled the package inside and outside the package. So, it’s hard to find its original or fake medicines. Identifying fake medical tablets is often difficult. It is detectable by a technical specialist utilizing visual inspection of medication packaging or other procedures such as thin layer chromatography (TLC), analytical techniques, or spectroscopic techniques. Spectroscopy can provide information on pharmaceutical tablets and capsules, such as tablets and granules. It may be used to calculate the quantity of a product and its pollutants, to identify related substances, to identify molecules, and so on. Several approaches for identifying fraudulent medicine pills are employed in spectroscopic techniques.
Raman spectroscopy is an ideal screening method for the quick characterization of pharmaceuticals or treatments since it is easy, non-destructive, and information-rich [5]. Such methods take more time and need sample preparation and technical experts in that domain with advanced laboratories. Those methods are still impractical or cannot be scaled up for use by ordinary people in the field. In comparison with analytical or chromatographic technologies, Hyperspectral is a suitable technique. The purpose of hyperspectral sensing is to acquire the unique spectral signature of every material, that acquire every spectral signature has representing unique value. Hyperspectral sensors examine objects using a wide range of electromagnetic spectrums. Entities generate different signatures in the electromagnetic spectrum. These signatures are called ‘spectral signatures’ and identify the components that make up the scanned object. It’s called imaging spectroscopy; it is a relatively new technique for scientists and professionals and used for the identification and detection of, food adulterations, and artificial substances [6].
In this study, we cantered our experiments on hyperspectral sensors for the detection or identification of chemical composition in solid medicinal tablets. Reflectance data of medicinal tablets were collected in the visible-near infrared range (750-2500 nm) and created a spectral signature of pure paracetamol and adulated paracetamol in various class. It is observed that the hyperspectral detection method is easier and faster to identify fake medicines because it provides spectral information that can be used to distinguish genuine medicines from fake medicines. Machine learning classification algorithms were used to the analysed collected spectral database. The use of hyperspectral data and NIR spectroscopy has emerged as promising technologies for detecting fraudulent medicines. These non-destructive analytical techniques have demonstrated high classification accuracy in identifying counterfeit medicines. The use of these technologies can provide a quick, simple, and effective field-level test for identifying fake medications. With the continuing advancement of these technologies, they hold great potential to address the global challenge of counterfeit and substandard medicines.
II. LITERATURE REVIEW
Numerous studies examine the use of hyperspectral sensing data to quickly and readily detect counterfeit medicines. With no need for direct contact, near infrared spectroscopy (NIRS) has been found to be a useful field level test method for spotting counterfeit drugs. The NIRS is a helpful tool for both the quick identification of a large assortment of pharmaceutical medication and the detection of fraudulent medicines. Hyperspectral sensing data was used to detect and classify adulterated medication tablets with high accuracy. Near infrared (NIR) spectroscopy was also utilized for quick identification and classification of pharmaceutical tablets, with machine learnings analysis methods such as PCA, KNN, SVM, and DA yielding excellent categorization scores and also NIR spectroscopy and image analysis techniques to locate natural medications that have been illicitly tainted alongside manufactured pharmaceuticals. Finally, hyperspectral data was utilized to compare the spectral properties of genuine and fake medications, demonstrating the utility of spectroscopy in distinguishing between chemically identical tablets. These studies suggest that NIR spectroscopy and hyperspectral data techniques have great potential for identifying fake medications and ensuring public health and safety [1, 7-10].
III. MATERIALS AND METHODS
A. Materials
Antimalarial and antibiotics are two of the most often recognized fake medications. We tested a total of 43 paracetamol tablets of various brands. Paracetamol is used to relieve discomfort. These drugs were chosen for the study because they are given regularly. These drugs continue to be among the most easily counterfeited. Falsification medication was difficult to comprehend due to the large number of substances it contained. Getting adulterated medicine was difficult, and it was equally challenging to know the ingredient percentages in it. Hence, in this experiment, we are trying to imitate the counterfeit medicines with spectral signatures of chemical compositions present in that tablet. As a result, to simulate bogus pharmaceuticals, we employed the finest type of calcium carbonate, that is, chalk powder, as a contamination element in our research. In addition, according to the WHO, fake medicines may contain unidentified components such as corn flour, starch, or chalk (CaCo3)[11] .
B. Methodology
In this study, our goal is to distinguish fake medicine tablets by measuring spectral information from of the spectral signature of the medicine powder samples using near infrared spectroscopy. In the figure 1 showing the workflow methodology for experimental work.
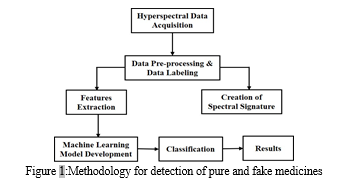
- Hyperspectral Data Acquisition
For the experiment work we have used ASD FieldSpec4 Hi-Res Spectroradiometer (Analytical Spectral Devices). The device wavelength range 350-2500 nm was employed for collect spectra. The spectral resolution was 3 nm for the visible and near-infrared region (350 ~ 1000 146 nm) and 8 nm for the shortwave-infrared region (1000 ~ 2500 nm). Measurement was carried out using a Paracetamol clip, which provides a calibrated light source. Before taking spectra collection, reflectance calibration was performed with standard white reference. Data pre-processing and analysis are performed using the ViewSpec Pro software. It is equipped with the same tools, including parabolic corrections, first and second derivatives, reflectance, absolute reflectance, log 1/ T and log 1/ R. It displays the latitude and longitude of the field position and can export .asd files into ASCII code (text files). The device specification shown in table 1 [12] .
Table 1:Device Specification and Wavelength, Range
|
Device Specifications |
Wavelength Name and Range |
||
|
Spectroradiometer |
ASD FieldSpec 4 Hi-Res |
VNIR-SWIR1 SWIR2 |
350 2500 nm |
|
Spectral Range(nm) |
350-2500 nm |
VNIR only |
350 1050 nm |
|
Spectral Resolution |
3 nm @ 700 |
VNIR-SWIR1 |
350 - 1800 nm |
The original tablets are first weighted and transformed into powder form for use in the hyperspectral data collection. The chalk powder as impurity is mixed in at percentages of 25%, 50%, and 75% to gather spectrum data. 50 reading were recorded to every sample during each of the aforementioned stages. 10 of the 50 readings were obtained from different angles. This has been done to equalize out the impact of unwanted disturbance. 250 readings were therefore gathered for the pure tablet and adult tablet combined.
2. Pre-processing Spectra
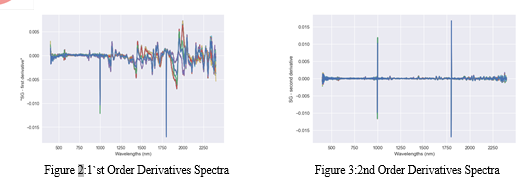
The ASDFieldSpec4 Spectroradiometer was used to analyses the paracetamol and adult paracetamol, and RS3 software was employed to obtain every material's spectral signature. 50 scans were obtained for each material and assembled into one average file, and it was utilized for computation. Proceeding with the preparation as well as statistical methods, paracetamol has been obtained. As well as preparations all the collected sample respectively. To decrease and remove unexpected variance and enhance the model's capacity for prediction and adaptability, an array of common spectral pre-processing techniques and their combinations have been utilized. The spectra between the wavelengths of 430 and 2500 nm were retained after the head of spectra with high noise levels was removed, and they were used for further experiment. The ViewSpecPro programmed is used to combine all of the Spectral signature files into a single file, which is equivalent to 25 scan files, before viewing it once more. After converting it mean file then we calculate the 1st order derivative and 2nd order derivatives as shown figure 2 and figure3. Additionally, by computing the neighbouring the slope wavelengths, the equation is frequently employed to enhance spectral accurateness. In order to decrease the impact of derivation on the ratio of signal to noise, filtering is typically applied before derivation. Savitzky-Golay averaging has been used in this study before carrying out the first order derivative pre-process [13].
3. Creation of Spectral Signature
Spectral signature of Paracetamol after the first and second derivative as a pre-processing phase. This has been completed after data pre - processing methods were created spectral signature of pure paracetamol and adulated paracetamol. ViewSpecPro software is used to generate each and every spectral signature. The main goal of this collection is to provide spectral information about the samples that were used to recognizing all the samples. In figure 4 and figure 5, the green color shows the spectral signature of a pure paracetamol tablet with the highest reflectance value of 1.09. The spectral signature of chalk powder in red with the lowest reflectance value is 0.79. In the highest adulteration, 75% of chalk powder and 25% paracetamol spectral signature paracetamol tablet with the highest reflectance value of 1.09 in blue color. The medium adulteration in paracetamol has a 50 % paracetamol and 50 % chalk powder spectral signature in a purple color, and its reflectance value is 0.98. The low adulterated paracetamol spectral signature in aqua color is 25% chalk powder and 75% pure paracetamol powder, and its reflectance value is 1.03. Between the paracetamol and chalk powder very high difference in its reflectance value. So, with the help of reflectance value and absorption bands we can easily find out the fake medicine tablets and pure medicine tablets.

4. Feature Extraction
The process of turning raw data into the inputs that a specific machine learning algorithms needs is known as feature extraction, and it's fairly complicated. Features should reflect the data's contents in a way that effectively satisfies the requirements of the method that will be used to solve the issue. We take the wavelength range from 400 to 2400 as a feature that is total 2000 features are extracted from our huge number of datasets showing in table 2 the same of features.
Table 2:Extracted Features with class wise
|
Samples |
Features |
||
|
Feature1 |
Feature2 |
Feature2000 |
|
|
Pure_para |
1.08 |
1.08 |
0.38 |
|
Chalk_powder |
0.77 |
0.77 |
0.40 |
|
Pure_para25_Chalk_75 |
0.88 |
0.88 |
0.40 |
|
Pure_para50_Chalk_50 |
0.99 |
0.99 |
0.40 |
|
Pure_para75_Chalk_25 |
1.03 |
1.03 |
0.38 |
IV. CLASSIFICATIONS
Each of the computational models built from prepared spectra performed better than the corresponding models created using unprocessed spectra.
A. Classification with the KNN
For the purpose of to create five distinct categories, the KNN algorithm was applied with the database's unadulterated and adulterated paracetamol samples. The K parameter, which represents the total number of closest neighbours, must be optimized in order to make use of this method. 3 was selected as the value of K to deliver the greatest amount of precise categorization upon modification. Outcomes to identify bands using hyperspectral data and combined with a second derivative are 62.5%. The testing as well as validation set spectra were all correctly identified by the KNN algorithms when calculated utilizing the hyperspectral data with a second order derivative. Therefore, the KNN algorithm is also appropriate for the detection of any pharmaceutical medication under consideration. The KNN method compels categorization, frequently assigning a class to unidentified samples, similar to how the Support Vector Machine (SVM) does. Following this, in order to differentiate the real data from those that are fakes and make it simple to identify pure or imitation data for the study of unidentified samples, a second test, such as correlation, must be utilized.
B. Classification with the Logistic Regression (LR)
To identify five distinct categories, the Logistic Regression (LR) method was employed with both pure and adulterated paracetamol in the database. The LR algorithm predicts a return value by using a linear equation with independent or explanatory factors. When the dependent (target) variables are classified, which allows the information to be classified split into different results (0, 1, k -1), the approach known as classification is applied. LR models must be utilized for transferring percentages to expected categories of the data as we are working via classification factors. Algorithms for classifier action put outcomes' chances into class numbers. The Softmax is a Function, a specific instance of the Softmax Function, will be discussed, as well as the Sigmoid Function quickly. When attempting to predict a single label from several groups in multi-class classification tasks, the Softmax function can be employ. Five groups were created as a consequence of the categorization, with LR accurately classifying 75% of the unadulterated and adulterated paracetamol.
C. Classification with the RF
Random forest is a supervised learning algorithm. It occurs in two distinct forms; among is employed to solve categorization challenges, the other to solve issues with regression. One of the most adaptable and user-friendly algorithms is this one. On the basis of the provided data examples, it constructs decision trees, obtains predictions from each one, and votes for the top answer. It additionally functions as a fairly accurate measure of feature significance. The Random Forest method creates a grove of trees by combining various decision-trees, therefore the degree of accuracy is increasing. Lin and Jeon identified the relationship between random forests and the k-nearest neighbour technique in 2002 [14].
These models, which are constructed to a set of training data, make predicts for brand-new points by examining their surroundings, which are defined by a weight function. having 10 decision trees, the model accuracy score was 62.5, instead alongside 100 decision trees, it rises to 75.0. As a result, the algorithm's anticipated accuracy rises as the number of decision trees grows.
D. Classification with the SVM
Depending upon the Principal component analysis results the SVM algorithm has been assessed with the objective to compare the ingredients of pure paracetamol and adulterated paracetamol. One Vs One Classifier and One Vs Rest Classifier were utilized in this research. The SVC polynomial kernel and the RBF had been both kernel functions that were attempted. Certain Svc function factors had to be adjusted to allow to get accurate results: The C and gamma factors for the RBF, as well as the C value for the SVC polynomial kernel. A grid search was used to improve the options on the test group. In the present paper, only the selected results are given. A total of five categories were created after categorizing pure and contaminated paracetamol. The calibration spectra of the five classes were used to calculate the SVM techniques, which were then evaluated using the training and test sets. For the One vs. One classifier and the One vs. Rest classifier, which correctly classified accuracy is 75%, the results of the SVC polynomial kernel and RBF are 62.5% and 75%, respectively. The Support Vector Machine (SVM) techniques can be used to distinguish between pure and fake paracetamol using either the SVC polynomial linear or the RBF. The proper recognition of the spectra depends on the tuning of the parameter values. Since the SVM uses forced categorization, it is inevitable that undetermined spectra will be allocated a class name. Additional parameters, such as a distance or a correlation, should be used to determine the boundary between legitimate and incorrect samples so as to use SVM techniques in the method for the detection of expected fake samples [15].
E. Classification with the Partial Least Squares Regression (PLSR)
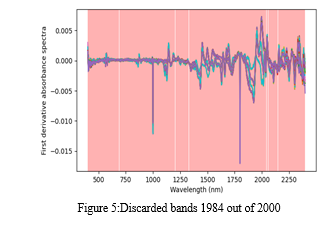
Partial Least Squares (PLS), a popular regression method, has been employed for analyzing information collected via near-infrared spectroscopy. As an additional technique, NIR spectroscopy requires that NIR data be calibrated against main reference data for the parameter being measured. The NIR data can be utilized for predicting the value of the measure that is important once the calibration is complete and reliable. Calibration must be done only one time. Since the sklearn already includes an PLS module, we don't need to create it from scratch. Therefore, we start by deciding how many components to include within the PLS analysis. For the purposes of this instance, we decided on keeping 8 components, but we'll eventually use that as a free option to be improved. We fit the regression to the data X (the predictor) and y after the PLS object is specified and y (the known response). The final step is to perform a cross-validation test with a 10-fold cross-validation using the model that that we just developed. We evaluate the common parameters to determine how accurate our calibration has become. By contrasting the cross-validation outcome with the predetermined answers, we assess these metrics. We're going to just monitor those measures, most frequently the MSE, to maximize the PLS regression's parameters (such as the number of components and pre-processing stages). That compared to excluding 1984 frequencies from the available 2000, or identifying the calibration's most important bands. On top of the absorbance spectra in figure 5 is a depiction of eliminated bands. The rejected bands are shown in red on this depiction of the first derivative spectra. Actually, the major paracetamol peaks are eliminated. The categorization was done for both adulterated and unadulterated paracetamol, yielding 5 groups with a 98.9% success rate according to PLSR.

Conclusion
The experiment attempts to analyses the spectral signature for the chemical compositions in solid medicines. It is observed that the potential of hyperspectral ASD spectroradiometer can be find out the impurities in solid medicines. Machine learning makes it easier to learn about spectral characteristics while spectral pre-processing helps to reduce the disparity within wavelengths. This paper presents the spectral bands of different inactive substances and paracetamol, an active pharmaceutical ingredient frequently found in painkiller medications, as well as the spectral collection in ViewSpecPro software. The classification included a number of difficulties. Identify fake tablets first; they will have multiple excipients based on the dose. Then the composition of the excipients might be very near among two distinct tablets. Therefore, the heterogeneity of the groups and the closeness of spectra among various tablets were caused by the intricacy of the categorization. The supervised techniques used by all of the machine learning algorithms enabled for accurate calibration and confirmation of the spectra. While KNN and SVM (One vs One) correctly categorized with 62.5%, LR, RF, and SVM (One vs Rest) correctly classified with 75%. The PLSR are excellent rate precision for the NIR spectroscopy and hyperspectral data, with 98.9% accuracy. The technique based on numerous genuine medicine tablets and fake medication tablets of different brands was explored in this research with the aid of spectral signatures.
References
[1] S. R. Shinde, K. Bhavsar, S. Kimbahune, S. Khandelwal, A. Ghose and A. Pal, \"Detection of Counterfeit Medicines Using Hyperspectral Sensing,\" 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), Montreal, QC, Canada, 2020, pp. 6155-6158, doi: 10.1109/EMBC44109.2020.9176419. [2] https://www.who.int/news-room/fact-sheets/detail/substandard-and-falsified-medical-products [3] Central Medicines Standard Control Organization: report on countrywide survey for spurious medicines 2009 access on jule 2021 [4] https://www.who.int/news/item/28-11-2017-1-in-10-medical-products-in-developing countries-is substandard or-falsified. [5] Neuberger S, Neusüß C. Determination of counterfeit medicines by Raman spectroscopy: Systematic study based on a large set of model tablets. J Pharm Biomed Anal. 2015 Aug 10;112:70-8. doi: 10.1016/j.jpba.2015.04.001. Epub 2015 Apr 17. PMID: 25956227. [6] Khan, Muhammad Hussain, Zainab Saleem, Muhammad Ahmad, Ahmed Sohaib, Hamail Ayaz, and Manuel Mazzara. 2020. \"Hyperspectral Imaging for Color Adulteration Detection in Red Chili\" Applied Sciences 10, no. 17: 5955. https://doi.org/10.3390/app10175955 [7] Arnold, Thomas & De Biasio, Martin & Leitner, Raimund. (2011). Near-Infrared Imaging Spectroscopy for Counterfeit Drug Detection. Proceedings of SPIE - The International Society for Optical Engineering. 8032. 27-. 10.1117/12.884732. [8] Dégardin K, Guillemain A, Guerreiro NV, Roggo Y. Near infrared spectroscopy for counterfeit detection using a large database of pharmaceutical tablets. J Pharm Biomed Anal. 2016 Sep 5;128:89-97. doi: 10.1016/j.jpba.2016.05.004. Epub 2016 May 6. PMID: 27236101. [9] Feng Y, Lei D, Hu C. Rapid identification of illegal synthetic adulterants in herbal anti-diabetic medicines using near infrared spectroscopy. Spectrochim Acta A Mol Biomol Spectrosc. 2014 May 5;125:363-74. doi: 10.1016/j.saa.2014.01.117. Epub 2014 Feb 8. PMID: 24566115. [10] Wilczy?ski S, Koprowski R, Marmion M, Duda P, B?o?ska-Fajfrowska B. The use of hyperspectral imaging in the VNIR (400-1000nm) and SWIR range (1000-2500nm) for detecting counterfeit drugs with identical API composition. Talanta. 2016 Nov 1;160:1-8. doi: 10.1016/j.talanta.2016.06.057. Epub 2016 Jun 28. PMID: 27591580. [11] https://www.who.int/news-room/fact-sheets/detail/substandard-andfalsified-medical-products accessed on 25-12-2022 [12] Gore, Ramdas & Chaudhari, Reena & Gawali, Bharti. (2016). Creation of Soil Spectral Library for Marathwada Region. International Journal of Advanced Remote Sensing and GIS. 5. 1787-1794. 10.23953/cloud.ijarsg.60. [13] Begum, Nafisa & Maiti, Abhik & Chakravarty, Debashish & Das, Sankar. (2020). Reflectance spectroscopy based rapid determination of coal quality parameters. Fuel. 280. 10.1016/j.fuel.2020.118676. [14] Lin, Y., & Jeon, Y. (2006). Random Forests and Adaptive Nearest Neighbors. Journal of the American Statistical Association, 101, 578 - 590. [15] Roggo Y, Degardin K, Margot P. Identification of pharmaceutical tablets by Raman spectroscopy and chemometrics. Talanta. 2010 May 15;81(3):988-95. doi: 10.1016/j.talanta.2010.01.046. Epub 2010 Feb 1. PMID: 20298883. [16] ViewSpecPro User Manual, ASD Incl, Accessed on 01/02/2023: Available on: http://geoinfo.amu. edu.pl/geoinf/m/spektr/viewspecpro.pdf [17] RS3 User Manual, ASD Incl, Accessed on 20/01/2023: Available on: http://www2.fct.unesp.br/docentes/carto/enner/PPGCC/Hiperespectral/Espectrorradiometro%20-%20Manuais%20-%20 Campo/RS3%20User%20Guide.pdf
Copyright
Copyright © 2023 Pravin V. Dhole, Vijay D. Dhangar, Sulochana D. Shejul, Prof. Bharti W. Gawali. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55922
Publish Date : 2023-09-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online