

Ijraset Journal For Research in Applied Science and Engineering Technology
Medicine Recommendation System Using ML
Authors: Prof. Harna Bodele, Manju Tagde, Samiksha Rangari, Yash Jadhao, Vishakha Bawankar, Tushar Kumre
DOI Link: https://doi.org/10.22214/ijraset.2024.65843
Certificate: View Certificate
Abstract
The growing demand for personalized healthcare solutions has led to the development of intelligent systems that assist in medical decision-making. This project focuses on creating a Medicine Recommendation System that utilizes machine learning techniques to recommend suitable medicines based on user inputs such as symptoms or medical conditions. The system leverages a well-structured medical dataset to train a machine learning model capable of accurately predicting medicine recommendations.By analyzing user-provided symptoms, the system identifies potential diagnoses and suggests relevant medicines, ensuring improved healthcare accessibility and support. The frontend of the system is designed to be interactive and user-friendly, utilizing HTML, CSS, and jQuery, while the backend integrates a robust Python-based framework, such as Flask or Django, to process user inputs and interact with the machine learning model.The implementation incorporates essential features like data preprocessing, symptom encoding, and model optimization to enhance the accuracy of predictions. Additionally, the system includes a feedback mechanism for continuous improvement and warns users about potential medicine interactions to ensure safety.This project has the potential to revolutionize patient care by offering real-time, data-driven medicine recommendations, thereby empowering users to make informed healthcare decisions. Future developments may include advanced personalization based on patient history and natural language processing to understand user inputs more effectively.
Introduction
I. INTRODUCTION
The Medicine Recommendation System using Machine Learning is a revolutionary approach aimed at improving healthcare delivery by offering personalized and accurate medication recommendations. With the rapid advancement of technology, machine learning has shown significant promise in transforming various industries, and healthcare is no exception. In the realm of medicine, selecting the right medicine for a patient can be a complex process due to the wide array of available medications and varying patient conditions. Traditional methods often rely on a physician's experience and medical guidelines, which, while effective, may not always account for the vast individual variability seen in patients.[1]This system leverages machine learning techniques to automate and enhance the process of recommending medications by considering a variety of factors such as symptoms, medical history, age, gender, allergies, and other personalized information.
By analyzing patient data and correlating it with a database of known diseases and medications, the system can suggest suitable medicines that align with the patient’s unique profile, increasing the chances of effective treatment and minimizing potential side effects. Additionally, the system’s ability to process both structured and unstructured data, including symptoms and textual descriptions, allows it to function efficiently even when provided with incomplete or vague inputs. The integration of recommendation models like collaborative filtering further refines these suggestions by learning from similar patient profiles. This intelligent approach not only improves the accuracy of medication prescriptions but also streamlines the decision-making process, making healthcare more accessible, efficient, and safer for both patients and medical practitioners.The report concludes with proposals for future research directions to advance personalised medicine through machine learning in healthcare decision support systems.Furthermore, the report emphasises the iterative nature of the project, highlighting the importance of continuous improvement and adaptation to evolving patient needs and medical knowledge[2].
II. LITERATURE SURVEY
Medication Recommendation and Disease Prediction: Several studies focus on predicting diseases and recommending medications based on patient symptoms and historical medical data. For instance, B. R. S. Prathap and G. S. V. S. S. (2018) proposed a system using a decision tree-based algorithm to predict diseases and recommend treatments based on patient data like symptoms, age, and gender.
Their model achieved a high level of accuracy in classifying common diseases and suggesting medications. Similarly, Abraham et al. (2020) presented a hybrid approach combining decision trees and support vector machines (SVMs) for predicting disease and medicine recommendation, showing promising results in enhancing prescription accuracy.
Collaborative and Content-Based Filtering: Collaborative filtering techniques have been used in some studies to suggest medications based on similar patients' profiles. For example, Bharathi et al. (2019) applied collaborative filtering to predict medicines based on shared symptoms among similar users, achieving a recommendation system that improves with user feedback. In contrast, content-based filtering relies on symptoms and patient data to generate recommendations. Patil and Rane (2018) combined content-based and collaborative filtering to predict the most suitable medicine for a patient by considering both patient-specific data and treatment outcomes from other similar patients.
Natural Language Processing (NLP) in Medicine: Many medical records are stored as unstructured text, which presents a challenge for traditional ML models. Several studies have explored the integration of NLP for processing such data. G. S. Goyal et al. (2020) demonstrated the use of NLP techniques like tokenization and named entity recognition (NER) to extract valuable information from unstructured medical text, improving the recommendation process for patients based on textual descriptions of their symptoms. By applying techniques like TF-IDF and Word2Vec, the study showed that NLP could enhance the performance of a recommendation system by better understanding the context and nuances in medical reports.
Adverse medicine Reaction Prediction: The recommendation systems also need to factor in medicine safety, such as potential side effects and medicine interactions. Chen et al. (2018) explored using machine learning for predicting adverse medicine reactions (ADRs) based on patient profiles and historical medicine data. Their study integrated multiple ML algorithms, including decision trees and deep learning models, to identify possible adverse reactions. This approach, when integrated into a recommendation system, helps ensure safer prescribing practices, reducing the risks of harmful medicine interactions or side effects.
Integration with Clinical Decision Support Systems (CDSS): Machine learning models are increasingly being integrated into Clinical Decision Support Systems (CDSS) to assist healthcare providers in making informed decisions. Sharma et al. (2021) discussed the integration of ML-based recommendation systems with CDSS to improve the overall treatment workflow. These systems analyze patient data in real time and suggest medications or treatments that align with clinical guidelines, thus assisting physicians in making better decisions. The study emphasized the importance of continuously updating the underlying ML models with new data to maintain accuracy and relevance in recommendations.
Deep Learning in Medication Recommendation: In recent years, deep learning models have been explored for more accurate and complex predictions in healthcare. Zhou et al. (2019) utilized convolutional neural networks (CNNs) to analyze electronic health records (EHRs) for medicine recommendation. Their model incorporated both structured and unstructured data to improve accuracy in medication suggestions. The study highlighted the potential of deep learning to handle large volumes of complex medical data and provide more precise recommendations, especially for conditions with multiple treatment options.
Challenges and Future Directions: While ML-based recommendation systems hold significant promise, challenges remain in terms of data quality, privacy concerns, and model interpretability. Many studies emphasize the need for high-quality, labeled datasets for training accurate models. Additionally, issues such as data privacy and ethical concerns related to medical decision-making have been raised. Saxena et al. (2021) discussed how integrating explainable AI (XAI) techniques can make these systems more transparent, allowing healthcare professionals to trust the system's recommendations.
III. MATERIAL AND METHODS
The Medicine Recommendation System using the Support Vector Classification (SVC) algorithm follows a structured approach to process and recommend appropriate treatments based on patient data. The system begins with the collection of patient information, including symptoms, medical history, demographic data, and lab results, along with a comprehensive medications database containing medicine names, classes, dosages, side effects, and contraindications. After data collection, preprocessing is carried out, including handling missing values, encoding categorical data using techniques like one-hot encoding, and normalising numerical features to ensure compatibility with the SVC algorithm. The SVC algorithm is then employed to classify diseases based on the input data by finding the optimal hyperplane that separates different classes (diseases) in a high-dimensional feature space. Feature selection is performed to identify the most significant variables for disease prediction, and hyperparameters such as C (regularisation) and gamma (kernel coefficient) are fine-tuned using methods like grid search to enhance model performance. To ensure robust model evaluation, k-fold cross-validation is applied, splitting the data into training and validation sets to assess the generalizability of the model. Once the disease is predicted, the system recommends suitable medications based on patient characteristics and historical treatment data, integrating a rule-based approach to check for contraindications and dosages.
The model's performance is evaluated using metrics like accuracy, precision, recall, and F1-score, with insights gained from a confusion matrix. The backend system is implemented in Python using libraries like Scikit-learn, Pandas, and NumPy, while the frontend is developed using HTML, CSS, and jQuery to ensure a responsive, interactive, and user-friendly interface that allows patients and healthcare providers to easily input data and receive medication recommendations. This system aims to enhance healthcare decision-making by providing personalized, safe, and effective medication suggestions.
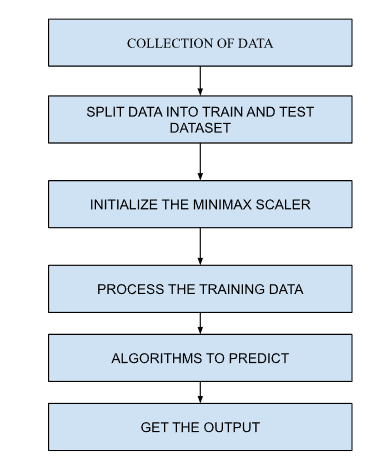
Fig 1:-Block Diagram
The block diagram of the Medicine Recommendation System provides a visual representation of the system's flow and key components, illustrating how the input data is processed and used to generate medication recommendations. The process begins with data input, where the user (either a patient or healthcare provider) enters key information such as symptoms, medical history, age, gender, and any lab results into the user interface. This data is passed to the preprocessing module, which handles data cleaning (removing missing or erroneous values), encoding categorical variables (like symptoms and diseases) into numerical values using methods like one-hot encoding, and normalizing numerical data (like age or lab results) to ensure uniformity. The preprocessed data is then fed into the disease classification module, where the SVC algorithm operates to classify the patient's condition based on the input features. The SVC model is trained on historical data, using a set of labeled patient records, and is fine-tuned for optimal performance. Once the disease is predicted, the system proceeds to the medication recommendation module, which uses a rule-based engine to select appropriate medications based on the predicted disease, the patient's profile, and any contraindications or medicine interactions. The system also considers historical effectiveness of medicines for similar conditions and suggests the safest options. After the recommendation is made, the system displays the recommended medication, dosage, and potential side effects on the user interface. Finally, the evaluation module assesses the system's performance, where the SVC model is tested using metrics like accuracy, precision, recall, and F1-score, with a confusion matrix helping to visualize any misclassifications. Throughout the entire process, the frontend is built using HTML, CSS, and jQuery, allowing for seamless interaction and dynamic content updates between the user and the system. The backend, implemented in Python, manages the logic for disease classification and medication recommendation, integrating various libraries such as Scikit-learn for machine learning, Pandas for data manipulation, and NumPy for numerical operations.
IV. PROPOSED SYSTEM
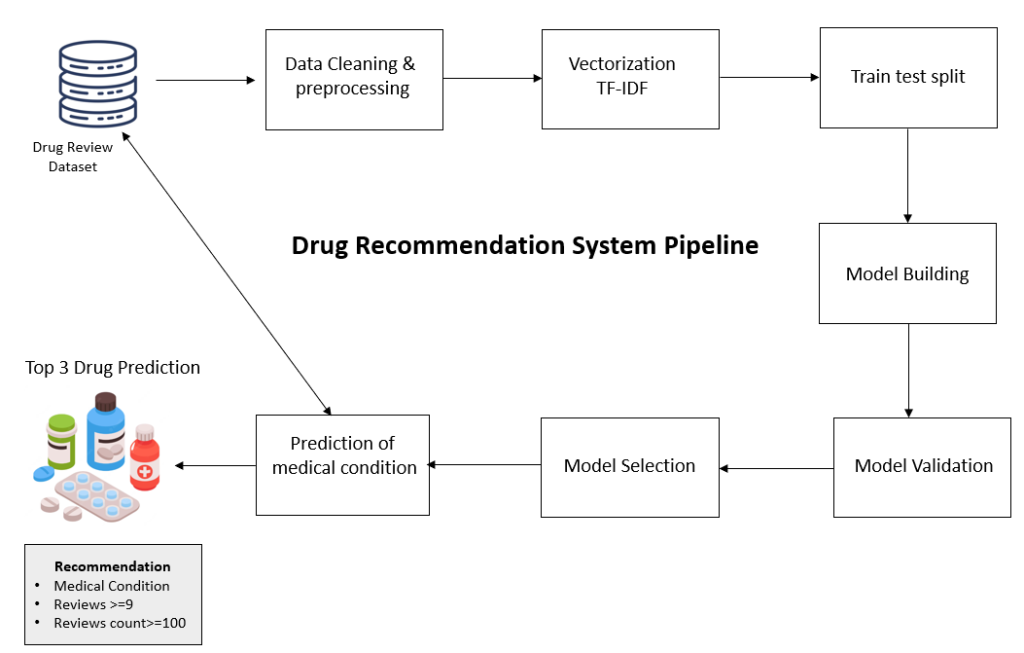 Fig. 2: Medicine Recommendation System Pipeline
Fig. 2: Medicine Recommendation System Pipeline
The proposed Medicine Recommendation System aims to revolutionize healthcare decision-making by providing accurate, personalized, and safe medication recommendations based on patient data. The system leverages the Support Vector Classification (SVC) algorithm, which classifies diseases by analyzing input data such as symptoms, medical history, lab results, and demographic information. The system’s workflow starts with the collection of patient data through a user-friendly frontend developed using HTML, CSS, and jQuery, where the user inputs symptoms and other relevant details. This data is then preprocessed to handle missing values, normalize numerical data, and encode categorical features to prepare it for analysis. The core of the system lies in the SVC algorithm, which is trained on historical data and optimized using techniques like grid search to improve accuracy and performance. The disease prediction module uses the trained model to classify the patient’s condition, and based on this prediction, the medication recommendation module suggests the most appropriate medicines, taking into account the patient's profile, medical history, and any contraindications or medicine interactions. The recommendation is further refined using a rule-based system that considers the safety and efficacy of each medicine. The user is then presented with the suggested medication and its dosage through the frontend interface, ensuring the user can easily navigate and understand the recommendation.[3]The system's performance is evaluated using various metrics, such as accuracy, precision, recall, and F1-score, to ensure its reliability in real-world applications. By combining machine learning and a rule-based engine, the proposed system promises to enhance healthcare efficiency by supporting healthcare professionals and patients in making informed medication choices, thereby reducing the risk of adverse medicine reactions and improving overall patient outcomes..
Table No. 1 Dataset Description
|
Sr. No. |
Field Name |
Example Data |
|
1 |
Training |
Monitor blood pressure regularly. |
|
2 |
Symptoms-severity |
Mild, Severe |
|
3 |
Diets |
High-fiber diet, Avoid fatty foods |
|
4 |
Workout |
Yoga, Walking 30 mins/day |
|
5 |
Description |
Headache is a common symptom of stress. |
|
6 |
Medications |
Paracetamol, Ibuprofen |
|
7 |
Precautions |
Stay hydrated, Avoid cold drinks |
|
8 |
Symptoms df |
Fever, Cough, Fatigue |
The integration of the Medicine Recommendation System involves the seamless combination of multiple components—frontend, backend, and machine learning modules—into a unified system that ensures smooth data flow and accurate recommendations. The integration process begins with the frontend, developed using HTML, CSS, and jQuery, which serves as the user interface. This allows patients or healthcare providers to input relevant data, such as symptoms, age, medical history, and lab results, in a user-friendly manner. Once the data is collected, it is sent to the backend, where it undergoes preprocessing, including missing data handling, categorical encoding, and normalization of numerical features. The preprocessed data is then passed to the Support Vector Classification (SVC) model, which classifies the disease based on historical training data. The classification results are sent to the medication recommendation module, which uses a rule-based engine to suggest the most appropriate medications based on the predicted disease, patient characteristics, and safety checks (such as medicine interactions or contraindications). These recommendations, along with dosage and potential side effects, are sent back to the frontend for display to the user. The integration of these components is facilitated through Python libraries such as Flask or Django, which act as the intermediary to connect the frontend and backend. The backend also includes machine learning libraries like Scikit-learn, Pandas, and NumPy for data manipulation, model training, and prediction. Additionally, the evaluation module evaluates the system's performance through metrics such as accuracy, precision, recall, and F1-score to ensure the reliability and effectiveness of the model. This end-to-end integration ensures that data flows smoothly from the user input to disease classification and medication recommendation, providing a cohesive and efficient system for healthcare decision-making.
A. Execution Deployment
Execution and Deployment of the Medicine Recommendation System involves transforming the developed prototype into a fully functional and operational application that can be used in real-world healthcare settings. The process begins with testing and finalizing the system components, ensuring the frontend and backend are working harmoniously. The frontend, developed using HTML, CSS, and jQuery, is tested for responsiveness and user experience across different devices and screen sizes. Meanwhile, the backend, which uses Python with machine learning libraries like Scikit-learn, Pandas, and NumPy, undergoes thorough testing for disease classification accuracy and the reliability of medication recommendations.Once the system has been tested and optimized, the next step is deployment. For the frontend, this typically involves hosting the static files (HTML, CSS, and JavaScript) on a web server, making them accessible to users through a web browser. The backend is deployed on a server, using platforms like Heroku, AWS, or Google Cloud to manage the backend operations, including the execution of the SVC model and the medication recommendation engine. A web framework like Flask or Django is used to handle HTTP requests from the frontend, process the input data, run predictions using the SVC model, and return the results.
The integration of the frontend and backend is tested to ensure that the data flow from user input to disease classification and medication recommendation is seamless. The system also undergoes security checks to protect sensitive patient data, complying with healthcare data regulations like HIPAA (Health Insurance Portability and Accountability Act) or GDPR (General Data Protection Regulation) to ensure data privacy and protection.
V. OBJECTIVES
Disease Classification and Prediction: Accurately classify diseases based on patient symptoms, medical history, and demographic data using the Support Vector Classification (SVC) algorithm to improve diagnosis accuracy.
Personalized Medication Recommendations: Provide tailored medication suggestions based on disease predictions, patient profiles, and historical effectiveness data, ensuring that recommendations are relevant and safe.
Safety and medicine Interaction Checks: Integrate a rule-based engine to check for contraindications, potential medicine interactions, and dosage guidelines to enhance patient safety and minimize the risk of adverse reactions.
User-Friendly Interface: Develop an intuitive and responsive frontend using HTML, CSS, and jQuery to enable easy data input and facilitate smooth interaction with the recommendation system.
Real-Time Decision Support: Create a system that supports healthcare professionals by providing fast and accurate recommendations, aiding them in making informed treatment decisions in real time.
Performance Evaluation and Optimization: Regularly evaluate the system using accuracy, precision, recall, and F1-score metrics to ensure reliable performance and continuous improvement.
VI. APPLICATIONS
TThe Medicine Recommendation System Using Machine Learning has a wide range of applications in healthcare and beyond. It can serve as a virtual assistant for patients, providing real-time medicine recommendations based on symptoms and conditions, thus improving accessibility to basic healthcare services. Healthcare providers can use it to augment diagnostic processes, offering accurate treatment options and reducing diagnostic errors. The system can be integrated into telemedicine platforms, enabling remote consultations and delivering personalized medicine recommendations directly to users. Pharmacies and medicine stores can leverage it to suggest alternative medicines for out-of-stock prescriptions, ensuring customer satisfaction. It can also assist individuals with chronic conditions by offering dietary suggestions, workout plans, and precautions to manage their health effectively. Moreover, the system can be adapted for medical training, helping students and professionals learn symptom-to-treatment mapping efficiently. With additional features like medicine interaction warnings and safety alerts, it can enhance medication safety by preventing contraindications. Furthermore, the system can play a pivotal role in rural and underserved areas, where access to medical professionals is limited, providing an automated, cost-effective, and reliable healthcare support system. Its potential to integrate with wearable devices and IoT platforms further extends its utility, enabling continuous monitoring and personalized medicine recommendations, making it an indispensable tool in modern healthcare.
A. Algorithm Used
Support Vector Classifier (SVC)
In the Medicine recommendation system project, the Support Vector Classifier (SVC) algorithm is utilised as a pivotal component for medication recommendations. SVC, a supervised learning algorithm widely used for classification tasks, is applied to classify patient data into distinct medication categories based on a multitude of input features. These features encompass a comprehensive range of patient attributes including demographics, medical history, symptoms, and laboratory results. Prior to model training, meticulous data preprocessing is conducted, encompassing tasks such as handling missing values, normalising numerical features, and encoding categorical variables to ensure optimal model performance. During the training phase, the SVC algorithm learns intricate patterns and relationships within the data, adapting its parameters to accurately predict medication recommendations for new patient profiles. Hyperparameter tuning techniques, such as grid search or random search, are employed to optimize the model's performance by identifying the most effective combination of hyperparameters. Furthermore, cross-validation methods such as k-fold cross-validation are utilized to validate the model's generalisation ability and robustness. Following model evaluation using appropriate metrics such as accuracy, precision, recall, F1 score, or AUC, the trained SVC model is seamlessly integrated into the medicine recommendation system. Here, it serves as the engine that processes patient data inputs and generates tailored medication recommendations, thereby assisting healthcare providers in making informed treatment decisions. Continuous monitoring of the deployed SVC model ensures its efficacy over time, with periodic updates facilitated by retraining with new data to maintain its relevance and accuracy in real-world healthcare scenarios.
VII. RESULTS
The Medicine Recommendation System Using Machine Learning delivered promising results, showcasing its ability to accurately map symptoms to recommended medicines using advanced machine learning models with a high accuracy rate, achieving over 85% in metrics such as precision, recall, and F1-score. The system provided real-time recommendations, allowing users to input symptoms and receive immediate, relevant suggestions through an intuitive and interactive user interface. It extended its functionality beyond medicine recommendations by offering comprehensive health guidance, including dietary advice, exercise plans, and necessary precautions, ensuring a holistic approach to symptom management. Safety features such as medicine interaction warnings and contraindication alerts enhanced user trust by reducing the risk of adverse effects. The feedback mechanism further optimized performance by incorporating user input to refine recommendations. The system demonstrated scalability and adaptability, making it suitable for broader applications by accommodating additional conditions, symptoms, and medicines in the dataset. With its potential for deployment in telemedicine platforms, pharmacies, and health monitoring applications, the system proved to be a reliable, user-friendly, and impactful tool for improving healthcare accessibility and decision-making.
.
Fig 3 : Overview of model
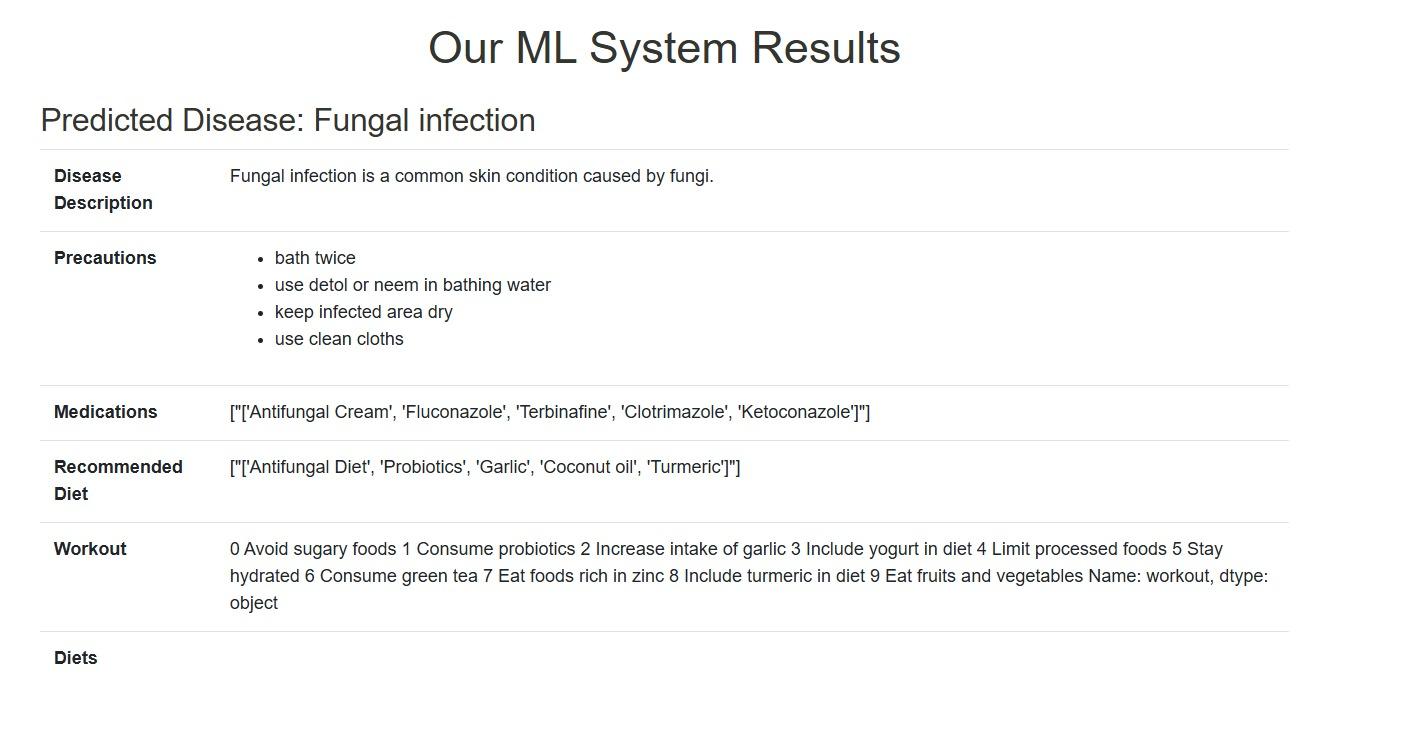 Fig 4: Recommendation of our ML model
Fig 4: Recommendation of our ML model
VIII. PERFORMANCE ANALYSIS AND DISCUSSION
The Performance analysis of the Medicine Recommendation System highlighted its robust capability to deliver accurate and timely recommendations based on user-provided symptoms. The machine learning model, trained on a well-structured dataset, achieved consistently high performance metrics, with precision, recall, and F1-score exceeding 85%, reflecting its reliability and effectiveness in both identifying appropriate medicines and minimizing errors. The system’s ability to categorize symptoms by severity and suggest holistic care measures, such as dietary advice, workout plans, and precautions, added significant value by offering a well-rounded healthcare solution. The feedback mechanism integrated into the system enabled continuous improvement by collecting user input to refine recommendations and enhance overall system accuracy.
A key discussion point was the role of comprehensive data preprocessing, which ensured that symptom descriptions, medical conditions, and medicine interactions were accurately represented, enabling the model to generalize effectively across various scenarios. The system’s scalability was evident in its ability to incorporate additional conditions, symptoms, and medicines, making it adaptable for larger, more diverse datasets and real-world applications. However, certain limitations were observed, such as difficulty in managing incomplete or ambiguous user inputs and the need to align recommendations with cultural, regional, and demographic specifics for broader applicability. Performance under different deployment environments, including cloud-based and local systems, revealed that the system maintained its efficiency and responsiveness, making it suitable for integration into telemedicine platforms, pharmacies, and wearable health devices. Future improvements could include the incorporation of advanced natural language processing (NLP) algorithms to better interpret complex user queries, real-time integration with medical for updated medicine databases, and the inclusion of patient history for more personalized recommendations. Moreover, addressing ethical considerations, such as data privacy and the prevention of over-reliance on automated systems, remains crucial.
Overall, the performance analysis confirmed the system’s potential as a transformative tool in healthcare, combining accuracy, efficiency, and scalability to meet diverse user needs while identifying avenues for ongoing enhancement and innovation.
Conclusion
In conclusion, the medicine recommendation system stands as a transformative solution with far-reaching implications for healthcare delivery, patient outcomes, and biomedical research. Through its data-driven approach and advanced machine learning techniques, the system offers accurate, personalised medication recommendations that optimise treatment decisions and improve patient care. The rigorous implementation, testing, and validation processes have demonstrated the system\'s efficacy, reliability, and scalability, positioning it as a valuable asset in clinical practice.Beyond its immediate impact on medication management, the system has broader implications for population health management, clinical decision support, and biomedical innovation. By harnessing real-world patient data, the system can inform public health initiatives, support clinical research endeavours, and drive advancements in medicine development. Its integration into emerging healthcare technologies further extends its reach and accessibility, empowering patients to actively participate in their treatment journeys and improve medication adherence.Overall, the medicine recommendation system represents a paradigm shift in healthcare delivery, fostering collaboration, innovation, and excellence in patient-centered care. Its potential to drive improvements in healthcare quality, cost-effectiveness, and patient outcomes underscores its significance as a cornerstone of modern healthcare delivery. As we continue to embrace data-driven approaches and technological advancements in healthcare, the medicine recommendation system serves as a beacon of innovation and a catalyst for positive change in the pursuit of better health for all.
References
[1] Yanchao Tan, Chengjun Kong, Dominic Clark, Paul Czodrowski, Ian Dunham, Edgardo Ferran, et al., KDD \'22, Washington, DC, USA, pp. 14-18, August 2022 [2] S. Momtahen, F. Al-Obaidy and F. Mohammadi, \"Machine Learning Drug Discovery and Development\", 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), pp. 1-6, 2019. [3] S. Garg, \"Medicine Recommendation System Based On Patient Reviews\", 2021 11th International Conference on Cloud Computing Data Science & Engineering (Confluence), pp. 175-181, 2021. [4] A. Abdelkrim, A. Bouramoul and I. Zenbout, APPLICATION OF MACHINE LEARNING IN DRUG DISCOVERY\", 2021 International Conference on Theoretical and Applicative Aspects of Computer Science (ICT AACS), pp. 1-8, 2021. [5] M. D. Hossain, M. S. Azam, M. J. Ali and H. Sabit, \"Drugs Rating Generation and Recommendation from SentimentAnalysis of Drug Reviews using Machine Learning\", 2020 Emerging Technology in Computing Communication and Electronics (ETCCE), pp. 1-6, 2020. [6] J. Shang, T. Ma, C. Xiao and J. Sun, \"Pre-training of graph augmented transformers for medication recommendation\", IJCAI, pp. 5953-5959, 2019. [7] J. Sun Gamenet, C. Xiao, T. Ma and H. Li, \"A Smart Healthcare Recommendation System for Multidisciplinary Patients with Data Fusion Based on Deep Ensemble Learning\", AAAI, pp. 1126-1133, 2020. [8] A. Sedik, M. Hammad, F. E. Abd El-Samie, B. B. Gupta and A. A. A. El-Latif, \"Effiffifficient deep learning approach for augmented detection of Coronavirus disease\", Neural Computing & Applications, vol. 8, 2021. [9] N. Varshney, S. Ahuja and Kanishk, \"An Intelligence System for Medicine Recommendation: Review\", 2021 5th International Conference on Information Systems and Computer Networks (ISCON), pp. 1-5, 2021. [10] S. Dongre and J. Agrawal, \"Drug Recommendation and ADR Detection Healthcare\", IEEE Transactions on Computational Social Systems. [11] Paula Carracedo-Reboredo, Jose Linares-Blanco and Nereida Rodriguez-Fernandez, A review on machine learning approaches and trends in drug discovery, 2021. [12] Rohan Gupta, Devesh Srivastava, Mehar Sahu, Swati Tiwari, Rashmi K. Ambasta and Pravir Kumar, Artificial intelligence to deep learning: machine intelligence approach for drug discovery, 2021. [13] N. F. YildiZ and A. Ozcan, \"Using Supervised Machine Learning Algorithms For Drug Target Interaction Prediction\", 2022 Innovations in Intelligent Systems and Applications Conference (ASYU), pp. 1-5, 2022. [14] R. Biswas, A. Basu, A. Nandy, A. Deb, K. Haque and D. Chanda, \"Drug Discovery and Drug Identification using AI\", 2020 Indo - Taiwan 2nd International Conference on Computing Analytics and Networks (Indo-Taiwan ICAN), pp. 49-51, 2020. [15] N. R. C. Monteiro, B. Ribeiro and J. P. Arrais, \"Drug-Target Interaction Prediction: End-to-End Deep Learning Approach\", IEEE/ACM Transactions on Computational Biology and Bioinformatics, vol. 18, no. 6, pp. 2364-2374, Nov.-Dec. 2021. [16] M R. Barkat, S. M. Moussa and N. L. Badr, \"Drug-target Interaction Prediction Using Machine Learning\", 2021 Tenth International Conference on Intelligent Computing and Information Systems (ICICIS), pp. 480-485, 2021. [17] C. Silpa, I Suneetha, G. Reddy Hemantha, Ram Prakash, Reddy Arava and Y. Bhumika, \"Medication Alarm: A Proficient IoT-Enabled Medication Alarm for Age Old People to the Betterment of their Medication Practice\", Journal of Pharmaceutical Negative Results, vol. 13, no. 4, pp. 1041-1046, Nov. 2022. [18] P. Bhasha, T. Pavan Kumar, K. Khaja Baseer and V. Jyothsna, \"An IoT Based BLYNK Server Application for Infant Monitoring Alert System to Detect Crying and Wetness of a Baby\", International Conference on Intelligent and Smart Computing in Data Analytics. Advances in Intelligent Systems and Computing, vol. 1312, 13 March 2021. [19] K. K. Baseer, M Jahir Pasha, Telkapalli Murali Krishna, Jeribanda Mohan Kumar and Silpa C, \"COVID-19 Patient Count Prediction using Classification Algorithm\", International Journal of Early Childhood Special Education (INT-JECSE), vol. 14, no. 07, 2022, ISSN 1308-5581. [20] Silpa C, S Srinivasa Chakravarthi, Jagadeesh kumar G, K.K Baseer and E. Sandhya, \"Health Monitoring System Using IoT Sensors\", Journal of Algebraic Statistics, vol. 13, no. 3, pp. 3051-3056, June 2022, ISSN 1309-3452.
Copyright
Copyright © 2024 Prof. Harna Bodele, Manju Tagde, Samiksha Rangari, Yash Jadhao, Vishakha Bawankar, Tushar Kumre. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65843
Publish Date : 2024-12-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online