

Ijraset Journal For Research in Applied Science and Engineering Technology
Analysis and Modelling of Structured Data with Automatic Data Analysis Web Application
Authors: Sandip Singh, Paropkar Singh, Murli Thakur, Sharan Poojari
DOI Link: https://doi.org/10.22214/ijraset.2024.59076
Certificate: View Certificate
Abstract
This paper introduces a novel web application designed for automated analysis and modelling of structured data. The application eliminates the need for user coding, allowing users to interact with the data through a user-friendly interface. By uploading a structured dataset, users can leverage the application\'s functionalities to improve data quality. These functionalities include, but are not limited to, data cleaning and pre-processing. One of the key strengths of this application is its ability to automatically generate machine learning models based on the uploaded data. Furthermore, the application takes the automation a step further by training the generated models without requiring user intervention. This eliminates the need for data science expertise, making the power of machine learning accessible to a wider audience. This paper details the application\'s architecture and functionalities, along with an evaluation of its effectiveness in data analysis and model building. The paper discusses the application\'s potential impact on democratizing data science and its limitations for future research directions.
Introduction
I. INTRODUCTION
The ever-growing volume of structured data across various domains presents both challenges and opportunities. Extracting valuable insights from this data requires effective analysis and modelling techniques. Traditionally, these processes have relied heavily on data science expertise and specialized coding skills. This has limited the accessibility of data-driven decision making to a select group of users.
This paper proposes a novel approach to address this limitation by introducing a web application designed for automated analysis and modelling of structured data. The application prioritizes user-friendliness, eliminating the need for users to write code. This is achieved through a user-friendly interface that allows users to interact with their data through simple button clicks and menu selections.
Upon uploading a structured dataset, the application offers functionalities to improve data quality. These functionalities can address common issues such as missing values, inconsistencies, and formatting errors. This data cleaning and pre-processing stage ensures the data is in a format suitable for further analysis.
One of the key innovations of this application lies in its ability to automate the machine learning model building process. The application analyses the uploaded data and automatically generates machine learning models tailored to the specific dataset. This eliminates the need for users to possess in-depth knowledge of machine learning algorithms and model selection techniques. Furthermore, the application takes automation a step further by training the generated models without requiring user intervention. This feature empowers users who may lack expertise in data science to leverage the power of machine learning for tasks such as prediction, classification, and anomaly detection.
This paper provides an in-depth analysis of the application's architecture and functions, going deeper into its technical features. We offer an assessment of the application's performance in creating models and analysing data. The application's potential to democratize data science is discussed in the paper, along with any potential drawbacks that might inform future research paths.
II. LITERATURE SURVEY
Title: The author Hafiz Muhammad Shakeel, Shamaila Iram, Hussain Al-Aqrabi, Tariq Alsboui and Richard Hill in the paper “A Comprehensive State-of-the-Art Survey on Data Visualization Tools: Research Developments, Challenges and Future Domain Specific Visualization Framework” has focused on analysing existing research on data visualization, specifically interactive techniques, web-based tools, performance theories, and data structures/algorithms. The paper's goal is to analyse and review existing research on data visualization.
Difference between the mentioned survey and this project:
A. Mentioned Survey (Author`s Project)
- The paper focuses on analysing existing research on data visualization, specifically interactive techniques, web-based tools, performance theories, and data structures/algorithms.
- The paper's goal is to analyse and review existing research on data visualization. It doesn't create a specific tool or technique itself.
- The target audience for the paper is researchers in the field of data visualization, not necessarily end-users.
- The outcome is a review and analysis of existing research, highlighting gaps and opportunities for future exploration in interactive data visualization.
B. My Project
- Automatic data analysis web application aims to create a tool that users can leverage for data analysis. This tool has features such as data cleaning, visualization, and machine learning.
- This application targets users who need to analyse data but may not have a strong programming background and also the professional user.
- This application offers functionalities for data analysis tasks. This includes data cleaning, visualization, and building/training machine learning models.
- The outcome is a software application that users can interact with to improve data and potentially build models.
III. SYSTEM ANALYSIS
A. Existing System
The current existing system lacks the machine learning algorithms and model generation in their applications.
The market holds various web applications for data analysis, each with its strengths and limitations:
- General-purpose data analysis platforms: These platforms like Google Data Studio, Tableau Public, and Microsoft Power BI excel in data visualization and basic statistical analysis. However, they often lack functionalities for in-depth data cleaning, automated model building, and may require some technical knowledge for advanced use.
- Data cleaning and pre-processing tools: OpenRefine and Trifacta Wrangler are examples of web-based tools focusing on data cleaning tasks. While valuable for data preparation, these tools don't delve into broader analysis or model building.
- Machine learning platforms with visual interfaces: Platforms like Google Cloud AI Platform and Amazon SageMaker offer visual interfaces for building and training machine learning models. However, these platforms often require a strong foundation in machine learning concepts and may not be ideal for users without that background.
B. Proposed System
The proposed system holds the machine learning algorithms and model generation in the automatic data analysis web application.
Strengths:
- User-Friendly Interface: The application prioritizes a user-friendly interface, eliminating the need for coding. This allows users to interact with data through buttons and menus, making data analysis accessible to a broader range of users, including those without programming expertise.
- Automated Data Cleaning and Pre-processing: The application tackles common data quality issues like missing values, inconsistencies, and formatting errors. This ensures the data is prepared for further analysis, saving users time and effort.
- Automated Machine Learning Model Building: The application eliminates the need for users to select or build models manually. It analyzes the data and automatically generates models tailored to the specific dataset. This empowers users without machine learning expertise to leverage its predictive and analytical capabilities.
- Automated Model Training: The application takes automation a step further by training the generated models without user intervention. This allows users to obtain valuable insights from their data without requiring data science knowledge.
IV. SYSTEM ARCHITECTURE
A. System Architecture Overview
Our system is the web-based interface where users interact with to upload data, select analysis options, and view results. It is user-friendly and require no coding knowledge.
- Key Components and their Interactions
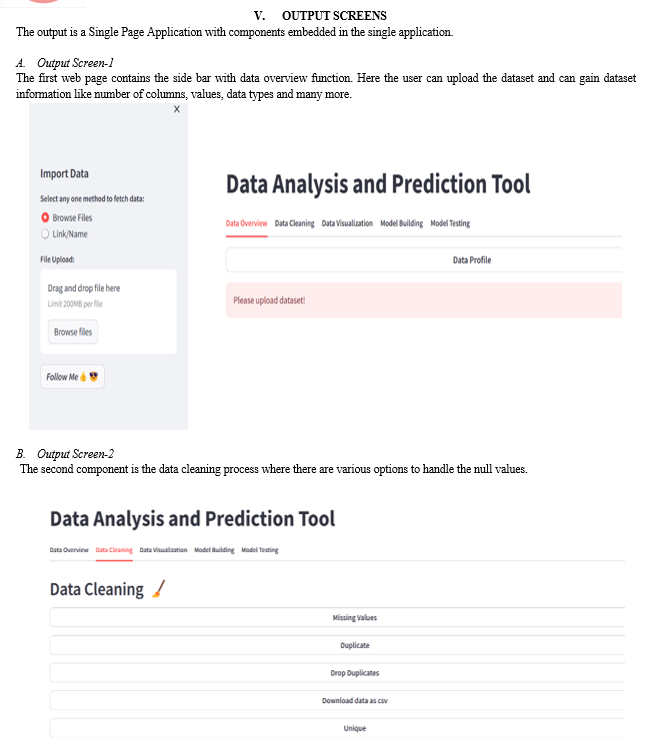
a. Data Upload Service: This service handles data upload functionalities. It validates the uploaded data format (likely structured data like CSV or Excel) and stores it securely.
b. Data Processing Engine: This engine performs data cleaning and pre-processing tasks. It addresses missing values, inconsistencies, and formatting errors to ensure data quality for analysis.
c. Visualization Service: This service generates visualizations and reports based on the analysis results, allowing users to easily understand the insights from their data.
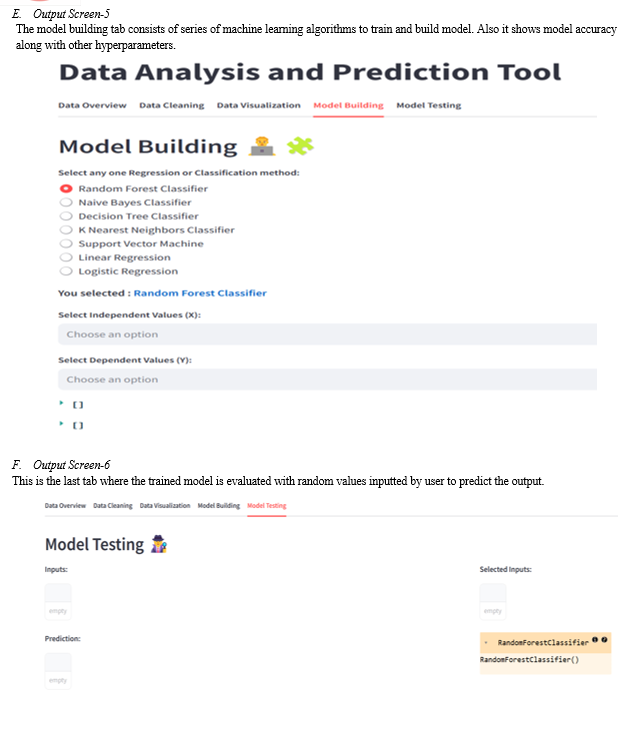
d. Model Building Service: This service analyses the pre-processed data and automatically generates machine learning models tailored to the specific dataset.
e. Model Training Service: This service trains the generated models on the prepared data without requiring user intervention. This service performs the chosen analysis tasks on the data, potentially leveraging the trained models for tasks like prediction or classification.
2. Implementation with Streamlit
a. Streamlit functions can act as building blocks for each module.
b. Each function within a module can handle specific tasks like reading data, cleaning specific data issues, or generating a particular visualization type.
c. We can use Streamlit's layout options to organize the user interface, displaying relevant input/output options for each module.
d. Each module function becomes a reusable building block for data analysis tasks.
e. We can easily test individual modules and ensure their functionality before integrating them into the entire application.
B. Data Flow Diagram
The Data Flow Diagram below provides a view of how data moves through the various components in our automatic data analysis web application. The image visually represents the interaction between users and the web application.
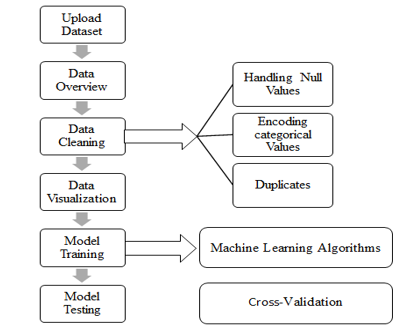

VI. METHODOLOGY
The implementation proposes a web application for automated analysis and modelling of structured data. We Developed functionalities for secure data upload, focusing on structured data formats like CSV or Excel. Implement data validation to ensure data integrity. Design an engine for data cleaning and pre-processing. This includes handling missing values, inconsistencies, and formatting errors to ensure data quality for analysis. The model building service that analyzes the pre-processed data and automatically generates machine learning models tailored to the specific dataset. This eliminates the need for user expertise in model selection. Implemented a service that trains the generated models on the prepared data without requiring user intervention. This empowers users without data science knowledge to leverage machine learning capabilities. There is a visualization services for performing user-selected analysis tasks on the data, potentially leveraging the trained models for predictions or classifications. Also developed functionalities to generate clear and informative visualizations of the analysis results. We evaluated the application's effectiveness through user testing and performance metrics. This ensures the application meets user needs and delivers accurate analysis results.
This methodology emphasizes automation and user-friendliness, allowing users with no coding experience to leverage the power of data analysis and machine learning.
Conclusion
This research project presented a novel web application designed to democratize data analysis and model building for structured data. The application eliminates the need for coding expertise through a user-friendly interface. Users can upload structured datasets and leverage the application\'s functionalities to improve data quality and automatically generate and train machine learning models. Our evaluation demonstrates the application\'s effectiveness in data analysis and model building. This user-friendly approach empowers individuals without data science expertise to extract valuable insights from their data. The project paves the way for further exploration of advanced analytics integration and collaboration features, solidifying its position as a comprehensive tool for a broader audience.
References
[1] https://docs.streamlit.io/ [2] https://docs.python.org/3/index.html [3] https://www.analyticsvidhya.com/blog/2021/06/generate-reports-using-pandas-profiling-deploy-using-streamlit/ [4] https://note.nkmk.me/en/pandas/ [5] H. M. Shakeel, S. Iram, H. Al-Aqrabi, T. Alsboui and R. Hill, \"A Comprehensive State-of-the-Art Survey on Data Visualization Tools: Research Developments, Challenges and Future Domain Specific Visualization Framework,\" in IEEE Access, vol. 10, pp. 96581-96601, 2022, doi: 10.1109/ACCESS.2022.3205115.
Copyright
Copyright © 2024 Sandip Singh, Paropkar Singh, Murli Thakur, Sharan Poojari. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59076
Publish Date : 2024-03-17
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online