

Ijraset Journal For Research in Applied Science and Engineering Technology
Music Representation System Using Live Face Detection
Authors: Shubham Bhagwat, Tushar Gadhave, Shrikant Gholap, Nishant Bhaskar, Ass. Prof. Bhondave S. D
DOI Link: https://doi.org/10.22214/ijraset.2024.59312
Certificate: View Certificate
Abstract
Music plays a significant role in improving and elevating one’s mood as it is one of the important source of entertainment and inspiration to move forward. Recent studies have shown that humans respond as well as react to music in a very positive manner and that music has a high impact on human’s brain activity. Now a days, people often prefer to listen to music based on their moods and interests. This work focuses on a system that suggests songs to the users, based on their state of mind. In this system, computer vision components are used to determine the user’s emotion through facial expressions. Once the emotion is recognized, the system suggests a song for that emotion, saving a lot of time for a user over selecting and playing songs manually. Conventional method of playing music depending upon the mood of a person requires human interaction. Migrating to the computer vision technology will enable automation of such system. To achieve this goal, an algorithm is used to classify the human expressions and play a music track as according to the present emotion detected. It reduces the effort and time required in manually searching a song from the list based on the present state of mind of a person. The expressions of a person are detected by extracting the facial features using the HaarCascade algorithm and CNN Algorithm. An inbuilt camera is used to capture the facial expressions of a person which reduces the designing cost of the system as compared to other methods
Introduction
I. INTRODUCTION
Facial expressions are one of the natural means to communicate the emotions and these emotions can be used in entertainment and Human Machine Interface (HMI) fields In today’s world, with the advancements in the areas of technology various music players are deployed with features like reversing the media, fast forwarding it, streaming playback with multicast streams. Although these features satisfy the basic requirements of the user, yet one has to manually surf for the song from a large set of songs, according to the current circumstance and mood. This is a time consuming task that needs some effort and patience. The main objective of this work is to develop an intelligent system that can easily recognize the facial expression and accordingly play a music track based on that particular expression/emotion recognized. The seven universally classified emotions are Happy, Sad, Anger, Disgust, Fear, Surprise and Neutral. The main objective of this work is to develop an intelligent system that can easily recognize the facial expression and accordingly play a music track based on that particular expression/emotion recognized. The seven universally classified emotions are Happy, Sad, Anger, Disgust, Fear, Surprise and Neutral. The algorithm that is used in developing the present system is Haar Cascade algorithm which utilizes faces to extract the facial features. The designed algorithm is very efficient due to less computational time taken hereby increasing the performance of the system.
II. LITERATURE SURVEY
Research on Automatic Music Recommendation Algorithm Based on Facial Micro-expression Recognition
Author: Ziyang Yu1 , Mengda Zhao1 , Yilin Wu1 , Peizhuo Liu1 , Hexu Chen1
Abstract: In recent years, with the development and application of big data, deep learning has received more and more attention. As a deep learning neural network, convolutional neural network plays an extremely important role in face image recognition. In this paper, a combination of micro-expression recognition technology of convolutional neural network and automatic music recommendation algorithm is developed to identify a model that recognizes facial micro-expressions and recommends music according to corresponding mood. The facial micro-expression recognition model established in this paper uses FER2013 with a recognition rate of 62.1content-based music recommendation algorithm is used to extract the feature vector of the song and a cosine similarity algorithm is used to make the music recommendation. This research helps to improve the practicality of the music recommendation system, and the related results will also serve as a reference for the application of the music recommendation system in areas such as emotion regulation.
III. METHODOLOGY

A. Explanation
Steps involved to design the system To design the system, training dataset and test images are considered for which the following procedures are applied to get the desired results. The training set is the raw data which has large amount of data stored in it and the test set is the input given for recognition purpose.
The whole system is designed in 5 steps:
- Image Acquisition: In any of the image processing techniques, the first task is to acquire the image from the source. These images can be acquired either through camera or through standard datasets that are available online. The images should be in .jpg format. The images considered here are user dependent i.e. dynamic images. The number of sample training images considered here.
- Pre-processing: Pre-processing is mainly done to eliminate the unwanted information from the image acquired and fix some values for it, so that the value remains same throughout. In the pre- processing phase, the images are converted from RGB to Gray-scale and are resized to 256*256 pixels. The images considered are in .jpg format, any other formats will not be considered for further processing. During pre-processing, eyes, nose and mouth are considered to be the region of interest. It is detected by the cascade object detector which utilizes Jones-Viola algorithm
- Facial Feature Extraction: After pre-processing, the next step is feature extraction. The extracted facial features are stored as the useful information in the form of vectors during training phase and testing phase. The following facial features can be considered “Mouth, forehead, eyes, complexion of skin, cheek and chin dimple, eyebrows, nose and wrinkles on the face”. In this work, eyes, nose, mouth and forehead are considered for feature extraction purpose for the reason that these depict the most appealing expressions. With the wrinkles on the forehead or the mouth being opened one can easily recognise that the person is either surprised or is fearful. But with a person’s complexion it can never be depicted. To extract the facial features PCA technique is used.
- Expression Recognition: To recognize and classify the expressions of a person Euclidean distance classifier is used. It gets the nearest match for the test data from the training data set and hence gives a better match for the current expression detected. Euclidean distance is basically the distance between two points and is given by “(3.1)”. It is calculated from the mean of the faces of the training dataset. The training images that correspond to various distances from the mean image are labeled with expressions like happy, sad, fear, surprise, anger, disgust and neutral. When the Euclidean distance between the faces of the test image and mean image matches the distance of the mean image and faces of the training dataset the expression is classified and named as per the labeled trained images. Smaller the distance value obtained, the closest match will be found. If the distance value is large enough for an image then the system has to be trained for that individual. The equation measure using Euclidean distance.
- Play Music: The last and the most important part of this system is the playing of music based on the current emotion detected of an individual. Once the facial expression of the user is classified, the user’s corresponding emotional state is recognized. A number of songs from various domains pertaining to a number of emotions is collected and put up in the list. Each emotion category has a number of songs listed in it. When the user’s expression is classified with the help of CNN algorithm, songs belonging to that category are then played.
IV. CLASS DIAGRAM
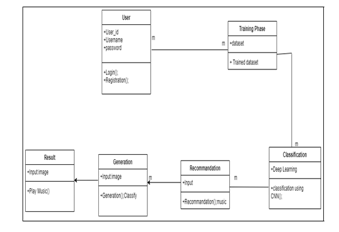
V. ALGORITHM
A. CNN Algorithm
A CNN is a kind of network architecture for deep learning algorithms and is specifically used for image recognition and tasks that involve the processing of pixel data. There are other types of neural networks in deep learning, but for identifying and recognizing objects, CNNs are the network architecture of choice. CNNs are used for image classification and recognition because of its high accuracy. It was proposed by computer scientist Yann LeCun in the late 90s, when he was inspired from the human visual perception of recognizing things The widely used algorithms in this context include denoising, region growing, edge detection, etc. The contrast equalization is often performed in image-processing and contrast limited adaptive histogram equalization
steps: Convolutional Layer. Pooling Layer. Fully Connected Layer. Dropout. Activation Function
Conclusion
The proposed work presents facial expression recognition system to play a song according to the expression detected and also classify music Type. It uses CNN approach to extract features, and Euclidean distance classifier classifies these expressions. In this work, real images i.e. user dependent images are captured utilizing the in-built camera
References
[1] S L Happy and Aurobinda Routray, “Automatic Facial Expression Recognition using Features of salient Facial Patches,” in IEEE Trans. On Affective Computing, January- March 2015, pp. 1-12. [2] Hafeez Kabani, Sharik Khan, Omar Khan and Shabana Tadvi, “Emotion based Music Player,” Int. J. of Eng. Research and General Sci., Vol. 3, Issue 1, pp. 750-756, January- February 2015. [3] Li Siquan, Zhang Xuanxiong. Research on Facial Expression Recognition Based on Convolutional Neural Networks [J]. Journal of Software, 2018, v.17; No.183 (01): 32-35. [4] Hou Yuqingyang, Quan Jicheng, Wang Hongwei. Overview of the development of deep learning [J]. Ship Electronic Engineering, 2017, 4: 5-9. [5] Liu Sijia, Chen Zhikun, Wang Fubin, et al. Multi-angle face recognition based on convolutional neural network [J]. Journal of North China University of Technology (Natural Science Edition), 2019, 41 (4): 103-108. [6] Li Huihui. Research on facial expression recognition based on cognitive machine learning [D]. Guangzhou: South China University of Technology, 2019. [7] Li Yong, Lin Xiaozhu, Jiang Mengying. Facial expression recognition based on cross- connection LeNet-5 network [J]. Journal of Automation, 2018,44 (1): 176-182 [8] Yao L S, Xu G M, Zhap F. Facial Expression Recognition Based on CNN Local Feature Fusion[J]. Laser and Optoelectronics Progress, 2020, 57(03): 032501. [9] Xie S, Hu H. Facial expression recognition with FRR-CNN [J]. Electronics Letters, 2017, 53 (4): 235-237. [10] Zou Jiancheng, Deng Hao. An automatic facial expression recognition method based on convolutional neural network [J]. Journal of North China University of Technology, 2019,31 (5): 51-56
Copyright
Copyright © 2024 Shubham Bhagwat, Tushar Gadhave, Shrikant Gholap, Nishant Bhaskar, Ass. Prof. Bhondave S. D. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59312
Publish Date : 2024-03-22
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online