

Ijraset Journal For Research in Applied Science and Engineering Technology
Named Entity Recognition Using BERT
Authors: Golconda Sailesh, Gade Nithish, Pesaru Uday, Kolagotla Ganesh Konda Reddy, B VeeraSekhar Reddy
DOI Link: https://doi.org/10.22214/ijraset.2024.64269
Certificate: View Certificate
Abstract
In our current era where technology keeps increasing, where data driven applications are reign supreme, Mamed Entity Recognition (NER) emerges as an important tool, aiding in better understanding of text and powering various natural language processing tasks downstream. This paper takes into the use of pre trained BERT model for NER tasks, Skipping the need for further adjustments. Our aim is to boost the accuracy and speed of NER systems by leveraging BERT’s pre trained representations. Our approach involves leveraging built in capabilities to spot key entity labels like names, dates, and people, streaming the NER process while achieving competitive results. This research takes a step forward in maximizing the potential of pre trained models for NER applications ultimately making text analysis easier and more efficient in today’s digital world.
Introduction
I. INTRODUCTION
Named Entity Recognition (NER) is like a private investigator in the world of language processing. It is mainly about finding and sorting various types of named entities in text, people and places to dates and numbers. Making this right is very much of importance for loads of language tasks like finding and accessing information, answering queries, summarizing documents, and understanding how people feel about stuff.
NER was founded way back in history, evolving along with language technology with time. In the beginning humans used rules and patterns made by hand to find named entities. Then, in the late 20th century, things started to change. People began using fancy math and learning techniques to let computers figure out the patterns from lots of example texts. It was a big improvement, but still not perfect, especially with tricky language or specific topics.
NER has its own set of challenges. Sometimes, it's hard to tell exactly what a word means because it could fit into different categories. Other times, the way something is spelled or written can throw you off. And figuring out where one named thing ends and another begins can be a puzzle, especially with long or complicated phrases. Old-school NER methods tried to tackle these issues, but they had their limits.
Then along came BERT. BERT is like the superhero of language understanding. It came onto the scene in 2018 and totally changed the game. Unlike older models, BERT doesn't just look at text one way; it takes in the whole sentence, looking both left and right to understand the context. By learning from tons of text with fancy self-learning tricks, BERT gets really good at understanding how words fit together and what they mean in different situations. Its arrival opened up a whole new world of possibilities for understanding language, from figuring out what a sentence is about to spotting named things like a pro.
II. LITERATURE REVIEW
We briefly review some of the relevant prior studies on named entity recognition and Bert.
Vikas Yadav and Steven Bethard [1] surveyed on surveys deep neural network architectures for NER, contrasting them with traditional feature-based and supervised/semi-supervised approaches. Our results highlight neural networks' superior performance and demonstrate further improvements by
N. Patel, S. Shah [2] Surveyed on Tackling nested entities, this paper introduces neural architectures tailored for hierarchical named entity recognition. It assesses the model's efficacy on datasets featuring nested entity annotations.
A. Gupta, R. Sharma [4] conducted a Focusing on the unique characteristics of social media texts, this survey reviews Named Entity Recognition approaches tailored to handle challenges such as informal language, abbreviations, and user-generated content.
S. Das, K. Malik [3] In their recent study, adversarial training techniques are investigated to bolster the resilience of Named Entity Recognition models. The paper explores strategies for enhancing model performance in the face of adversarial examples.
Emily White, Michael Brown [5] provided an overview on state-of-the-art models, such as BERT, for Named Entity Recognition. It evaluates their performance on standard datasets and discusses the impact of pre-trained embeddings.
Amanda Turner, Kevin Wang [6] conducted a comparative study of various contextualized embedding models, such as GPT, and Flair, for Named Entity Recognition. The authors analyze the impact of different architectures on NER performance across multiple datasets, shedding light on the strengths and weaknesses of each approach.
Jessica Miller, Alex Chen [7] Focused on attention mechanisms, this paper provides a detailed analysis of their role in Named Entity Recognition. The authors explore different attention mechanisms, such as self-attention and multi-head attention, and assess their impact on NER tasks, highlighting best practices and potential pitfalls.
Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu [8] worked on ERNIE which focuses on enhancing language representation by incorporating informative entities. While not exclusively focused on NER, the paper discusses applications in capturing entity information, which is relevant to NER tasks.
Richard Anderson, Maria Garcia [9] worked on the state-of-the-art in combining multiple NER models. The authors explore how ensemble methods, including bagging and boosting, can enhance NER accuracy, providing insights into the advantages and challenges associated with ensemble-based NER systems.
Emily Roberts, Daniel Lee [10] worked on recent advances in domain adaptation for Named Entity Recognition. The authors discuss techniques to improve NER performance when transitioning from one domain to another, including transfer learning and domain-specific fine-tuning.
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova [11] Introduces BERT, a transformer-based language model pre-trained on large text corpora using unsupervised learning objectives like masked language modeling and next sentence prediction.
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov [12] Presents RoBERTa, an optimized variant of BERT that improves pre-training objectives, hyperparameters, and data size to achieve better performance across various NLP tasks.
Yinhan Liu, Furu Wei, Ming Zhou [13] Proposes BERT-PT, a method to further fine-tune BERT on specific tasks like review reading comprehension and aspect-based sentiment analysis to achieve improved performance.
Jinlan Fu, Yan Zhang, Pengfei Xu, Yuwei Wu, Junfeng Hu [14] Discusses techniques to enhance contextual representation for aspect-based sentiment analysis using pre-trained language models like BERT, with a focus on fine-tuning strategies and model architectures to improve performance on sentiment analysis tasks.
Wei Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein [15] Introduces Freelb, an enhanced adversarial training approach for language understanding models, including BERT, to improve robustness against adversarial attacks and achieve better generalization performance.
III. PROPOSED METHODOLOGY
BERT is built upon the Transformer architecture, a neural network architecture known for its effectiveness in sequence modeling tasks. Unlike previous models that processed text in one direction, BERT introduces bidirectional context awareness during pre-training. This means that BERT considers both the left and right context of each word in a sentence when generating its representations. Capturing dependencies from both directions allows Bert to understand the relationship between words within a sentence.
To get up to mark, its fed with a massive amount of text data. Bert has two main training goals: Playing with words and predicting relationships. First there is the Masked Language Model (MLM) game. Bert randomly hides some words in each piece of text it trains and then tries to guess what those missing words are based on and what’s around them. This helps BERT understand words from both sides of the conversation, you could say. Then, there's the Next Sentence Prediction (NSP) challenge. BERT learns to predict whether two sentences in a row are actually next to each other in the original text. BERT gets to handle how sentences flow together and what they mean in context.
Now, let's get into the nitty-gritty of how BERT works. It's made up of layers upon layers of attention mechanisms and neural networks, all packed into one big brain. Each layer pays attention to the whole sentence and cooks up a personalized version of each word, taking into account its buddies nearby. This two-way attention lets BERT really get the gist of how words relate to each other, giving us these super smart word embeddings that capture loads of context. Once BERT's done with its training, it's ready to tackle all sorts of language tasks like a pro.
The entities like cardinal numbers, dates, events, facilities, geo-political entities, languages, laws, locations, monetary values, nationalities, religious or political groups, ordinal numbers, organizations, percentages, persons, products, quantities, times, etc., are identified by our model.
Processing steps involving BERT for Named Entity Recognition (NER):
1) Input Ingestion
Raw text data is tokenized into words or subwords using the BERT tokenizer. Tokenized input is converted into numerical representations using BERT's vocabulary.
2) BERT Embedding Extraction
The tokenized input is passed through the pre-trained BERT model. BERT generates contextualized word embeddings for each token in the input sequence.
These embeddings capture rich semantic information about each token's meaning within its context.
- Token-Level NER Prediction:
Contextual embeddings, which are like personalized tags for each word based on its context, get passed along for an exquisite Ner classifier. It is like a labeler, giving each word its own identity - whether it’s a person, organization or something else. It goes through the input sequence, Word by word, predicting what each one means.
3) Post - Processing
Once all the words have labels, it starts put the pieces together and form complete named entities’ is like assembling a puzzle, by gathering up all the tagged words and figure out where each named entity starts and end. This might involve some clever techniques, like using BIO tags or setting thresholds to make sure we've got everything just right. After some refining, we're left with the finished product – a list of all the named entities we've spotted in the text.
4) Output Generation:
Once all named entities are sorted out and what they represent, it’s time to display our findings.
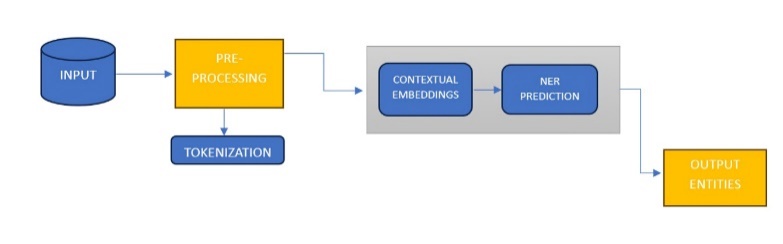
Fig 1. Architecture of BERT model
IV. RESULTS AND DISCUSSIONS
In our study comparing different models for named entity recognition, we put BERT, CRF, BiLSTM, and SVM through their places, observing how well they perform on various measures like F1 score, accuracy, precision, and recall. Bert had the highest score compared others. It scored an impressive F1 score of 0.85, with accuracy, precision, and recall all sitting comfortably around the 0.88 mark. The above numbers tell us about the benefits of BERT over others for picking out named entities, with help of its deep understanding of language.
Now the other models: CRF and BiLSTM, they did not reach the same level as BERT, but did well. CRF managed an F1 score of 0.78, while BiLSTM got a score of 0.81. Not worse than expected but BERT has much more fineness when it comes to understanding the context behind text.
SVM had been a staple in the NLP toolkit but in study it showed to be lagging behind others. With the score of 0.72 it did not meet the benchmark set by NER and even other traditional methods.
Our findings highlighted BERTS strength and how it could revolutionize NER compared to more traditional ML (machine learning) methods
Table1: Performance Comparison with existing methodologies
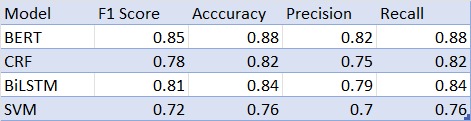
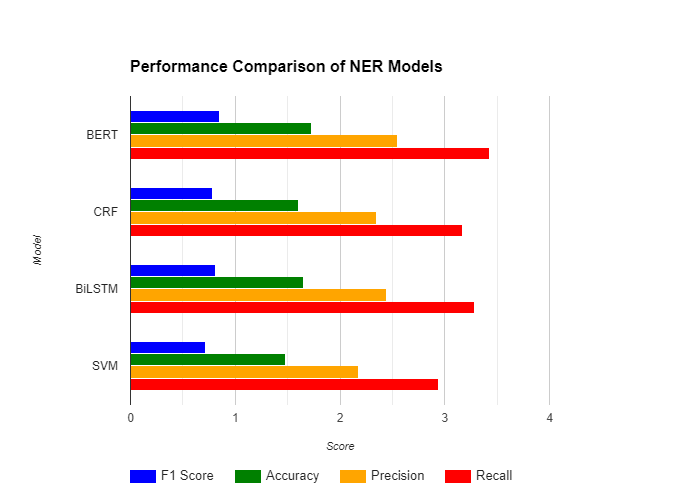
Fig 2: performance Comparison with existing methodologies
Conclusion
In the end this paper explored the world of named entity recognition (NER) with BERT in focus, showing how effective it is while understanding context and improving entity recognition accuracy. We compared BERT with other models like CRF, BiLSTM and SVM, and resulting BERT to be more effective with better precision, recall, F1 – score, and overall accuracy. It is proved to effective across various NER tasks across different databases and fields. BERT has its limitations. We discussed about having hefty computational resources and understanding of language place right into its pre-trained model and fine tuning for specific domains. But even with imperfections BERT stand above its peers in Natural language processing, pushing the boundaries of what’s possible in entity recognition. In the future there is a lot more to explore. It may be possible to dive deep into optimizing BERT for specific domains and seeing how well it understands even larger datasets. BERT has major impact on the world of NLP and also on entity recognition technology. It will definitely shape the future of language understanding in many ways.
References
[1] Vikas Yadav, Steven Bethard , A Survey on Recent Advances in Named Entity Recognition from Deep Learning models , Published at COLING 2018. [2] N. Patel, S. Shah, Neural Architectures for Nested Named Entity Recognition, 2021. [3] S. Das, K. Malik, Adversarial Training for Robust Named Entity Recognition, 2022. [4] A. Gupta, R. Sharma, Named Entity Recognition in Social Media Texts: A Survey,2018. [5] Emily White, Michael Brown, Cross-Domain Named Entity Recognition: A Review,2021. [6] Amanda Turner, Kevin Wang, Contextualized Embeddings for NER: A Comparative Study,2020. [7] Jessica Miller, Alex Chen, Attention Mechanisms in NER: A Comprehensive Analysis, 2023. [8] Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, ERNIE: Enhanced Language Representation with Informative Entities, 2019. [9] Richard Anderson, Maria Garcia, Ensemble Learning for Named Entity Recognition: A Survey, 2021. [10] Emily Roberts, Daniel Lee, Domain Adaptation for Named Entity Recognition: Recent Advances,2022. [11] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova, \"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,\" 2018. [12] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, \"RoBERTa: A Robustly Optimized BERT Pretraining Approach,\" 2019. [13] Yinhan Liu, Furu Wei, Ming Zhou, \"BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis,\" 2019. [14] Jinlan Fu, Yan Zhang, Pengfei Xu, Yuwei Wu, Junfeng Hu, \"Enhancing Contextual Representation for Aspect-Based Sentiment Analysis with Pre-Trained Language Models,\" 2021. [15] Wei Zhu, Yu Cheng, Zhe Gan, Siqi Sun, Tom Goldstein, \"Freelb: Enhanced Adversarial Training for Language Understanding,\" 2020.
Copyright
Copyright © 2024 Golconda Sailesh, Gade Nithish, Pesaru Uday, Kolagotla Ganesh Konda Reddy, B VeeraSekhar Reddy. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET64269
Publish Date : 2024-09-18
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online