

Ijraset Journal For Research in Applied Science and Engineering Technology
Object Detection Driven Precision Forecasting in Curved Terrains
Authors: Dr. U. Surendar , Nithishkannan K T, Jansi Rani REL, Harshitha Sai D
DOI Link: https://doi.org/10.22214/ijraset.2024.61669
Certificate: View Certificate
Abstract
This study introduces an inventive approach to avalanche forecast in fastener twist locales utilizing the You Simply See Once (YOLO) protest location system. Fastener twists, with their interesting geography, posture particular challenges for avalanche forecast, requiring a custom fitted arrangement that coordinating progressed computer vision strategies. The proposed technique combines high-resolution fawning symbolism information to make nitty gritty territory models of clip twist ranges. YOLO, known for its real-time question location capabilities, is adjusted to recognize potential avalanche triggers, counting slant flimsiness and changes in vegetation cover, inside these complex scenes. Real-time observing frameworks, counting ground-based sensors and climate stations, are deliberately put to ceaselessly capture natural conditions. Integration with the YOLO-based prescient demonstrate empowers the early recognizable proof of potential avalanche dangers, encouraging the usage of focused on early caution frameworks. Community engagement remains a pivotal perspective of this approach, including neighborhood inhabitants within the improvement of departure plans and readiness techniques. The cooperative energy between YOLO-based innovation and community association makes a comprehensive arrangement for proactively overseeing avalanche dangers in clip twists. Objective: The main objective of this study is to establish an accurate and efficient landslide prediction model adapted for hairpin regions using the You Only Look Once (YOLO) object recognition framework..
Introduction
I. INTRODUCTION
Clip twist districts, characterized by sharp turns in hilly landscapes, show one of a kind challenges in foreseeing and moderating avalanches. The vulnerability of these zones to slant insecurity and other geographical variables requires inventive approaches for precise and opportune avalanche forecast. This consider presents an progressed technique utilizing the You Simply See Once (YOLO) question discovery system, particularly custom fitted for avalanche forecast in clip twist locales. depending instep on high-resolution symbolism and geospatial data for point by point territory investigation. The YOLO question discovery system, known for its real-time capabilities and precision in recognizing objects inside pictures, is adjusted to address the complex challenges postured by the special geology of fastener twists. This adjustment includes a cautious adjustment of the YOLO design to upgrade its affectability to variables contributing to avalanches in these landscapes, such as soak slants, changes in vegetation cover, and geographical characteristics headway of cost-effective and productive strategies for geohazard evaluation. The consequent segments of this ponder will dive into the technique, comes about, and suggestions of our YOLO-based approach, shedding light on its potential for upgraded avalanche forecast precision in challenging landscapes .
II. LITERATURE SURVEY
"Real-time Pedestrian Detection with deep network cascades" [36]in a paper presented at BMVC 2021. Using the YOLO algorithm The research focuses on real-time pedestrian detection, using deep network cascades. However, despite YOLO's effectiveness in detecting objects based only on visual data such as images or video footage, it may miss important factors that influence phenomena such as landslides. These factors include soil composition, weather conditions, and historical landslides, which are outside its scope.
"SegNet: Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. PAMI" by Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla was published in 2022. Although the paper does not directly address the YOLO algorithm, it highlights an important aspect of image quality that affects object detection algorithms such as YOLO. The effectiveness of YOLO depends a lot on the quality of the input images. Factors such as poor lighting conditions, image blur or occlusion can significantly affect its performance, leading to inaccurate predictions. This highlights the importance of image preprocessing and enhancement techniques in improving the reliability and accuracy of object recognition systems such as YOLO.
In their paper titled "Chenyi Chen, Ming-Yu Liu, Oncel Tuzel, Jianxiong Xiao: R-CNN for Small Object Detection," published by Springer International Publishing AG in 2022, the authors focus on the challenges of small object detection using the YOLO algorithm. They highlight the limitation where YOLO models, when trained on a specific set of images, may struggle to generalize effectively across varying environmental or geological conditions. This issue underscores the importance of robustness and adaptability in object detection algorithms, especially when dealing with small and potentially diverse objects in real-world scenarios.
In their publication titled "A Synchronized Multipath Rebroadcasting Mechanism for Improving the Quality of Conversational Video Service" in Wirel Pers in 2023, authors Harold Robinson and Golden Julie E SMR introduced the application of the YOLO algorithm. The summary highlights the potential of adapting this algorithm to detect various features associated with landslides, such as cracks, soil displacement, or vegetation changes. However, such adaptation may necessitate additional training data and fine-tuning, potentially demanding significant resources.
In their 2023 publication titled "Review: using unmanned aerial vehicles (UAVs) as Mobile sensing platforms (MSPs) for disaster response”, Hanno Hildmann and Ernö Kovacs delve into the application of UAVs as Mobile Sensing Platforms (MSPs) during disaster scenarios. The authors highlight the utilization of the YOLO algorithm, emphasizing its significance in facilitating real-time object detection tasks. However, their review suggests a limitation in the YOLO models, noting that those trained on one set of images may not effectively generalize across various environments or geological conditions. This observation underscores the importance of refining algorithmic approaches to ensure robustness and adaptability in disaster response efforts employing UAV-based sensing platforms.
III. EXISTING SYSTEM
Inaccessible detecting advances, such as adj. symbolism and airborne photography, are commonly utilized to screen changes in arrive cover, recognize potential avalanche triggers, and evaluate slant steadiness.
A. LiDAR Framework
LiDAR (Light Discovery and Extending) frameworks speak to another imperative inaccessible detecting innovation utilized for avalanche observing and evaluation. LiDAR frameworks transmit laser beats from flying machine or ground-based stages and degree the time it takes for the beats to return after hitting the Earth's surface. This information is at that point utilized to make profoundly precise three-dimensional models of the landscape, known as Advanced Height Models (DEMs) or Advanced Territory Models (DTMs). LiDAR information can uncover nitty gritty data almost incline points, surface unpleasantness, and rise changes, giving important bits of knowledge into incline steadiness and avalanche defenselessness. The high-resolution and exactness of LiDAR information make it especially profitable for evaluating avalanche risks in complex landscape, such as precipitous locales or soak inclines.
B. Farther Detecting Advances
Ethereal photography complements fawning symbolism by advertising point by point, high-resolution pictures captured from airplane flying over particular regions of intrigued. These pictures give a closer see of the territory and can capture better points of interest which will not be unmistakable in adj. pictures. Airborne photography is especially valuable for distinguishing unpretentious changes in geography, soil composition, and vegetation cover, which can serve as early caution signs of looming avalanches.
IV. DISADVANTAGES
A. Exorbitant LiDAR Information Procurement
LiDAR (Light Location and Extending) innovation is regularly considered the gold standard for capturing high-resolution 3D information for different applications such as mapping, looking over, and independent driving. Be that as it may, one of the major disadvantages of LiDAR information securing is its tall fetched. LiDAR frameworks ordinarily include costly equipment components such as laser scanners, GPS recipients, and inertial estimation units (IMUs). Also, the method of collecting LiDAR information regularly requires specialized vehicles or airplane, gifted staff, and noteworthy time and assets. This tall taken a toll can be a obstruction for numerous organizations or ventures with restricted budgets, restricting their capacity to get to or utilize LiDAR information for their needs.
B. Need of Real-Time Checking
Another impediment of existing frameworks is the need of real-time observing capabilities. Conventional LiDAR information securing strategies regularly include post-processing of the collected information, which suggests that the produced 3D point clouds or maps are not accessible in real-time. This need of real-time observing can be tricky in applications where prompt input or decision-making is required, such as catastrophe reaction, foundation checking, or independent route. Without real-time get to to LiDAR information, it gets to be challenging to identify and react to changes or peculiarities as they happen, possibly driving to delays or missed openings for intercession.
C. Reliance on Chronicled Information
Numerous existing frameworks too endure from a reliance on verifiable information. Since LiDAR information securing is ordinarily performed irregularly or on a intermittent premise, the produced datasets may rapidly ended up obsolete as the environment experiences changes over time. This dependence on historical information can restrain the exactness and unwavering quality of applications that require up-to-date data, such as urban arranging, natural checking, or exactness agribusiness. Without get to to convenient and important information, decision-makers may battle to create educated choices or expectations almost future improvements or occasions.
D. Need of Real-Time Observing
Preventing convenient decision-making and responsiveness. Without real-time information experiences, organizations may battle to distinguish and react instantly to critical occasions or changes within the environment, possibly driving to increased dangers and delays in tending to crises. Moreover, the failure to monitor circumstances as they unfurl limits the capacity to preserve comprehensive situational mindfulness, preventing the viability of decision-making forms. This insufficiency moreover makes it challenging to distinguish irregularities or deviations from anticipated standards, expanding the probability of neglected issues which will raise into more critical issues over time. Eventually, the need of real-time checking undermines effectiveness, efficiency, and optimization potential, as organizations miss out on openings to use up-to-date data for moved forward asset assignment and execution upgrade. Tending to this crevice by coordination real-time checking capabilities is basic for relieving dangers, improving decision-making forms, and opening openings for advancement across various spaces.
V. PROPOSED SYSTEM
The proposed framework for avalanche expectation in clip twist districts presents the integration of the You Simply See Once (YOLO) question discovery system, pointing to address the impediments of the existing frameworks. The key highlights and focal points of the proposed framework are as takes after:
A. YOLO-based Protest Discovery
The presentation of the YOLO question location system empowers real-time recognizable proof and localization of potential avalanche triggers inside clip twist districts. YOLO's productivity in handling pictures and its capacity to identify numerous objects at the same time improve the system's responsiveness.
B. Adjustment to Fastener Twist Territory
The YOLO engineering is custom-made to successfully handle the one of a kind highlights of clip twist territories. This adjustment incorporates fine-tuning the demonstrate to recognize particular characteristics such as soak inclines, changes in vegetation cover, and topographical properties, guaranteeing precise discovery of potential avalanche occasions.
C. Preferences
- Real-Time Protest Location
Real-time protest location alludes to the capacity of a framework to distinguish and track objects immediately as they show up inside a given environment. This capability empowers quick decision-making and reaction in energetic scenarios such as independent driving, observation, or mechanical technology. By giving quick input on the nearness and developments of objects, real-time location improves situational mindfulness and reduces the chance of mishaps or collisions. It encourages applications where opportune acknowledgment of objects, such as people on foot, vehicles, or impediments, is pivotal for guaranteeing security and proficiency.
2. Concurrent Discovery of Numerous Objects
The capability to at the same time distinguish different objects is basic for frameworks working in complex and swarmed situations. Whether it's distinguishing a few people on foot on a active road or following different vehicles on a thruway, concurrent location improves the system's capacity to get it the encompassing environment comprehensively. This include is especially important in scenarios where various objects of intrigued coexist, empowering productive decision-making and asset assignment without relinquishing exactness or speed.
3. Versatility to Challenging Territories
Versatility to challenging territories is vital for guaranteeing the strength and unwavering quality of protest location frameworks over differing situations. Whether it's rough territory, antagonistic climate conditions, or changing lighting conditions, a able framework ought to keep up its execution and exactness notwithstanding of the challenges postured by the environment. By joining progressed calculations and sensor combination strategies, versatile frameworks can handle landscape varieties viably, guaranteeing steady and dependable question discovery in any situation.
4. Improved Accuracy in Location
Accuracy in protest discovery is essential for minimizing wrong positives and precisely recognizing objects of intrigue inside the environment. Frameworks that offer upgraded accuracy utilize advanced calculations and sensor innovations to distinguish between objects with tall precision and unwavering quality. This precision is crucial in safety-sensitive applications like therapeutic imaging, where accurate differentiation of evidence of abnormalities or oddities is essential for decision-making and treatment planning.
5. LiDAR-Free Approach
A LiDAR-free approach to protest detection signifies the capacity to attain exact discovery without depending on LiDAR (Light Discovery and Extending) innovation. Whereas LiDAR is famous for its exactness in capturing 3D spatial information, it can be exorbitant and complex to coordinated into certain frameworks. By receiving elective sensor advances or inventive calculations, LiDAR-free approaches offer a more available and cost-effective arrangement for question location applications. This approach extends the availabi lity of protest location innovation to a more extensive extend of applications and businesses, advancing its appropriation and sending in different settings.
6. Diminished Preparing Costs
Lessening handling costs related with question location is pivotal for optimizing asset utilization and improving the versatility of frameworks. By utilizing effective calculations and equipment optimizations, frameworks can accomplish real-time execution while minimizing computational overhead. Diminished preparing costs empower the arrangement of question location arrangements in resource-constrained situations, such as edge gadgets or inserted frameworks, without compromising performance or exactness. This cost-effectiveness makes question location innovation more available and reasonable for far reaching selection over businesses and applications.
VI. DIGITAL IMAGE PROCESSING
Extracting objects from an image and this preparation starts with image processing (eg denoising) which is done (with mooplane) includes extraction to find lines, areas and some surfaces. This collection of images is divided into questions such as a car on the street, a box on a conveyor belt or a tumor in a biopsy machine. One of the reasons for observations is that objects can look remarkably different when viewed from different angles or in different lights. Another thing is to decide which highlights are which objects, which are bases or shadows, etc. Information is produced within an image in many imaginable ways. An image is often characterized by two different brightness values, and is regularly referred to in models as a print, slide, television screen or roll of film. Images can be prepared optically or carefully on a computer.
A. Basics of Image Processing
Fundamentals Of Digital Image
1) Image
A portray may be a two-dimensional picture that takes after an question, as a rule a physical protest or individual. They can be captured by optical gadgets (cameras, glasses, focal points, telescopes, magnifying instruments, etc.) as well as normal marvels and wonders (such as the human eye or the water surface).
Works of craftsmanship such as maps, charts, line drawings, or theoretical craftsmanship. In a broader sense, pictures can too be made by hand; It can be made by, for case, drawing, portray, outlining, printing, cutting or computer illustrations, or a combination of these that are especially valuable in fake photos





To digitally process an image, the image must first be reduced to a sequence of numbers that can be processed by a computer. Each number representing the brightness value of the image at a certain location is called a picture element or pixel. A typical digitized image might be 512×512, or about 250,000 pixels, although much larger images are becoming common. Once an image is digitized, it can perform three main functions on the computer. In point mode, the pixel value of the output image depends on the value of one pixel of the input image. For local operations, the number of pixels in the input image determines the pixel value of the output image. In global usage, all pixels in the input image affect the pixel value of the output image.
Therefore, these combinations try to achieve a winning compromise: to be flexible and thus tolerant of within-class variation, while being discriminative enough to be robust to background confusion and inter-class similarity. An important feature of our contour-based detection method is that it gives us considerable flexibility to incorporate additional image information. In particular, we extend the contour-based recognition method and propose a new hybrid recognition method that uses shape identifiers and SIFT features as recognition features. Shape features and SIFT features are largely orthogonal, with the former corresponding to shape boundaries and the latter to sparsely visible image locations. Here, each learned combination can contain features that are either 1) purely shape features, 2) purely SIFT features, or 3) a mixture of shape features and SIFT features. The number and types of suitable features are automatically learned from the training images and represent the most characteristic features based on the training set. Thus, by giving the combination these two degrees of variety (both in terms of number and types of features), we give it even greater flexibility and differentiation potential...
VI. IMAGERY CLASSIFICATION
In digital image processing, three different kinds of images are used. They're
- Image in Binary
- Image in Gray Scale
- Image Color
A. Image In Binary
A binary image is a digital image where there are only two potential values for each pixel. Although two colors can be utilized, black and white are the typical color scheme for binary pictures. The foreground color in an image is the one used for its objects, while the background color is the color used throughout the image. This indicates that a bit (0 or 1) is saved for every pixel.
Binary pictures are typically produced in digital image processing using processes including segmentation, thresholding, and dithering. Certain input/output devices, such fax machines and laser printers,
B. Grayscale Images
Grayscale images are digital images that each have a price. A pixel is a model, meaning it only carries reference data. Such images (also called black and white images) consist solely of shades of gray (0-255), ranging from the most intense black (0) to the most intense white (255). Black and white images are different in the context of computer graphics; A black and white image is an image that has only two colors: black and white (also known as a double-layer or binary image). Grayscale images have many shades of gray. Grayscale images are also known as monochrome, meaning there are no distinct colors. Sometimes they are monochrome.
They can be considered full-color images; See convert to grayscale. Each pixel has a unique value that determines the color it displays. This value is limited to a three-digit number and gives the dash color of the three primary colors red, green and blue. Thus, every color visible to the human eye can be represented. A number between 0 and 255 contains a color divided into three primary colors. Black(R,G,B) = (0,0,0);
In other words, the image size is a binary color value, a matrix of pixels where each pixel is encoded with 3 bytes representing the three primary colors. This makes the image a total of 256x256x256 = 16.8 million different colors. This technique is also called RGB coding and is specific to human vision
.Therefore, we will make use of many concepts of geometric mathematics, such as patterns, scalar multiplications, projections, rotations or distance, to handle our colors.
A company called Ultralytics released it just a month after its predecessor, the YOLOv4, and claimed several major improvements over the current YOLO device. Since the YOLOv5 model is only released as a GitHub repository and the model has not been released for peer review, there are doubts/concerns about the correctness and validity of the recommendation. Another company Roboflow analysed the model in detail and found that the only significant change in YOLOv5 (aka YOLOv4) was the integration of the anchor system into the samples. Therefore, YOLOv5 does not need to store the dataset as input and can find the most suitable anchor boxes for the given data and use them during learning. Although there is no official document, the implementation of the YOLOv5 model after several applications and good results began to give the model credibility. Finally, it is worth noting that the latest version of the YOLOv5 model is YOLOv5-V6.0, which claims to be a (very) light model with an inference rate of 1666 fps (the original YOLOv5 claims 140 fps). A second development version of the YOLOv5 model was announced, where the core features of the Transformer model (Transformer details are covered in the next section) are integrated into the YOLOv5 model and presented in an object context. detect UAV interception. Identifying and locating objects in images is a computer vision task called "object detection," and several algorithms have been developed in recent years to address this problem. To date, one of the most popular time tracking goals is YOLO (You Only Look Alone), which was first proposed by Redmond et al
C. Dataset Creation
For this tutorial I generated my own penguins dataset






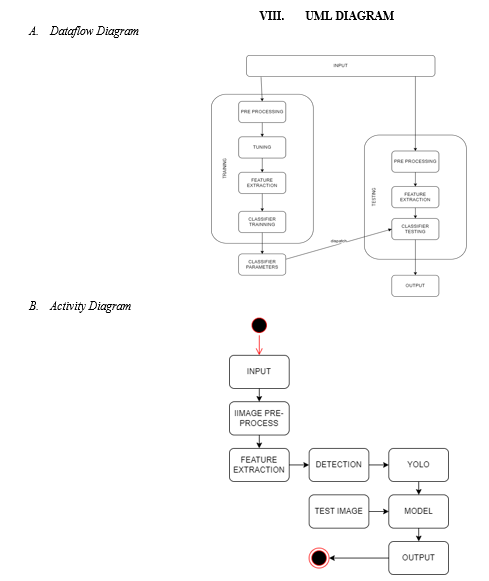
VII. BLOCK DIAGRAM (SOFTWARE)
A. Modules
- Input: In computing, "input" refers to data or commands given to the computer for processing. This input can come from many sources such as keyboard, mouse, touch screen, sensors or other devices. It works as a raw material for the computer to work or perform production tasks. Input can take many forms, including text, numbers, images, sounds, and gestures, depending on the application and the capabilities of the input device. In fact, the completeness and type of input data are important for the operation of the computer and the validity of the output. Ideas are often processed by software algorithms or hardware based on predefined rules or instructions to produce useful results. Functionality is essential for user interaction, data analysis, and automation tasks in fields ranging from personal computers to business automation to research studies.
- Pre-Processing: Preprocessing is an important stage in data analysis and signal processing that involves preparing raw data for further analysis or interpretation. It includes a variety of techniques designed to improve data quality, reduce noise, and eliminate distractions. Preprocessing steps include data cleaning (correcting or removing missing or incorrect results) and modeling (scaling data into different models to facilitate comparison). Filtering techniques can be used to remove noise or smooth the knowledge. Strategies for reducing dimensions, include feature selection or principal component analysis (PCA) can help reduce data complexity while preserving important information. Preprocessing is important to improve the performance of machine learning models by ensuring that input data is suitable for analysis. It plays an important role in many fields such as image processing, natural language processing and bioinformatics, where raw data often needs to be processed for analysis.
- Feature Extraction: The process of extracting pertinent information from raw data to produce a more condensed and representative representation is known as feature extraction in data analysis and pattern recognition. It entails determining and picking particular data traits or features that are most instructive for the task at hand. Reducing the dimensionality of the data while maintaining important discriminative features is the goal of feature extraction techniques. Frequently used techniques involve converting data into a new space where patterns are easier to identify, like principal component analysis (PCA) or linear discriminant analysis (LDA). Other approaches involve extracting statistical or structural features from the data, such as mean, variance, texture, or shape descriptors. Feature extraction is a critical step in machine learning and data mining tasks, as it helps improve model performance by focusing on relevant information and reducing computational complexity. It is widely used across various domains, including image processing, speech recognition, and bioinformatics, to extract meaningful insights from large datasets.
- Database Image: A database image refers to an image or set of images that are stored within a database for various purposes, such as retrieval, analysis, or reference. These images may represent a variety of visual data, including photographs, charts, diagnostics, satellite images, or other graphical data. In the context of computer vision or image processing, image databases are often used as data sources for tasks such as image classification, object detection or object recognition modelling. They work as a repository of visual information that can be queried or processed to obtain useful views or perform specific tasks. Database images are typically structured and scaled in a database system; It allows storing, retrieving and managing visual data for a variety of applications and analyses.
- YOLO: YOLOv5 (You Only See One 5) is a state-of-the-art pattern detection system known for its speed and accuracy in image processing time. It is built on the YOLO architecture, which allows for advancements such as simple design and innovative training methods. YOLOv5 provides improved performance across a wide range of data and scenarios, making it a popular choice for object detection applications. YOLOv5 uses a neural network (CNN) (usually based on popular models such as EfficientNet or CSPNet) to extract features and make predictions. This model allows YOLOv5 to achieve accurate detection while maintaining high speed, making it suitable for real-time use. YOLOv5 is versatile and can be adapted to many tasks, including object detection, instance classification, and even objects to be discovered through transformational learning. It supports CPU and GPU acceleration, enabling easy deployment on different hardware platforms. YOLOv5 is open source and actively maintained; A growing community contributes to its growth and development.
B. Models
- YOLO Object Detection
Is a cutting-edge, real-time technology for detecting objects. It's popular because it can detect objects in images or video frames quickly and accurately. YOLO processes images in a single pass, making it very efficient.
2. Landslide Prediction
Landslide prediction involves identifying areas prone to landslides based on various factors like terrain, weather, vegetation, and past occurrences. It typically relies on data analysis and modeling to predict where landslides are likely to occur.
3. Hairpin Bend Regions
Hairpin bend regions are areas along roads or trails where the road makes a sharp turn resembling a hairpin. These regions are often prone to landslides due to factors like steep slopes, erosion, and unstable soil.
4. Model Explanation
Your proposed model would use YOLO to detect specific features or indicators in images or video frames that suggest an increased risk of landslides in hairpin bend regions. These features could include signs of erosion, soil displacement, cracks in the terrain, or changes in vegetation patterns. The model would be trained on a dataset of images or videos containing examples of hairpin bend regions where landslides have occurred or are likely to occur. It would learn to identify patterns and features associated with landslide risk.
5. Advanced Prediction
By leveraging YOLO's real-time capabilities and the ability to detect subtle features indicative of landslide risk, your model could offer advanced prediction capabilities. It could potentially detect signs of an impending landslide before it occurs, allowing for timely evacuation or preventive measures to be taken.
IX. SOFTWARE REQUIREMENTS
- Python IDLE
- Programming: Python
- Library Package: TensorFlow, OpenCV, etc
A. Presentation TO OPEN CV
OpenCV was begun by Gary Bradsky at Intel in 1999, and its to begin with form was discharged in 2000. In 2005, OpenCV was utilized on Stanley, which won the 2005 DARPA Fantastic Challenge. Subsequently, the extension continued behind Willow Carport and under Gary Bradsky and Vadim Pisarevsky's course. OpenCV is a rapidly expanding library that now supports several forms relevant to computer vision and machine learning.. , Linux, OS X, Android, iOS etc. Moreover, CUDA and OpenCL-based interfacing are regularly created to empower high-speed GPU preparing. OpenCV gives the finest results of C++ API and Python dialect.
B. OpenCV-Python
ity.Python may be a general-purpose programming dialect begun by Guido van Rossum that rapidly got to be exceptionally well known due to its effortlessness and discernable code. It permits the software engineer to precise his thoughts in less lines without losing meaningfulness. In terms of dialects, Python is mediocre when compared to C/C++. In any event, Python's ease of coordination with C/C++ is another important feature. In order to use these wrappers as Python modules, it affects how we write the included C/C++ code and create a Python wrapper for it. This leaves us with two choices:
First off, because C++ code is running underneath, our code is just as fast as the original C/C++ code. Secondly, it is incredibly simple to code in Python. This is often how OpenCV-Python, a Python wrapper around the first C++ execution, works. Numpy is the finest library for arithmetic. Gives MATLAB-style sentence structure. All OpenCV cluster models are changed over to and from Numpy clusters. So anything you'll do in Numpy, you'll do with OpenCV, which has numerous weapons in your weapons store. Moreover, a few other libraries (such as SciPy and Matplotlib, which back Numpy) can be used with it.
C. OpenCV-Python Instructional exercises
OpenCV presents a unused set of apparatuses that will direct you through the numerous highlights accessible in OpenCV-Python. This direct centers essentially on OpenCV 3.x forms (but most instructional exercises moreover apply to OpenCV 2.x). Composing great code, particularly in OpenCV-Python, requires a great understanding of Numpy. You! The same goes for this preparing. This would be a incredible work for a amateur member. Fair fork OpenCV on github, make the essential fixes and yield the drag ask to OpenCV. OpenCV engineers will audit your drag ask, allow you imperative criticism, and once affirmed by analysts, it'll be included in OpenCV. At that point you ended up an open supporter. The same goes for other instructing, information, etc. Moreover substantial for . Subsequently, individuals who know a particular calculation can write instructions and yield them to OpenCV, containing the rationale of the algorithm and the code appearing how to utilize the calculation.
X. IMPLEMENTATION OF PACKAGES
import cv2i
mport matplotlib
import numpy
First of all, we require to understand some concepts and ideas related to picture and video examination. The data is precise, as is the way nearly all cameras record nowadays, outputting over 30-60 times per second. However, they are basically inactive outlines, similar to pictures. That's why picture recognition and video analysis frequently utilize the same strategy. A few things, like course following, got to be based on pictures (outlines), but things like confront location or protest acknowledgment can be done utilizing nearly the same number of pictures and recordings. Survey the sources to streamline them as much as conceivable. This nearly continuously begins with changing over to grayscale, but can moreover be a color channel, a angle, or a combination of these. From here we can make different checks and changes on the location. By and large talking, we change the process we need to return to the first, at that point analyze and utilize it; so you'll usually see the "wrapped up product" or confront of the item unmistakable from start to wrap up. put. Be that as it may, information is rarely processed in crude frame. Here are a few cases of what we are able do at the fledgling level. All typically done with a basic webcam, nothing extraordinary:
When an edge is identified, the black color compares to the pixel esteem (0,0,0) and the white line compares to the esteem (255,255,255). Each picture and video outline is separated into such pixels, and as with edge location, we can calculate where the edge is based on comparing white pixels with black pixels. Afterward, in case we need to see at the unique picture with stamped edges, we record all the coordinates of the white pixels and draw the first picture or movie.. Some time recently this we ought to stack the picture. So let's get begun! In this instructional exercise, I need you to work with your claim information. In the event that you have a webcam, be beyond any doubt to utilize it, stop looking for pictures that you simply think would be fun to utilize.
First of all, we consequence a few things, I would like you to install these three modes. Imag is thus described as cv2.read(image file, parms). IMREAD_COLOR, or color without an alpha channel, is the default.. In the event that you do not know, alpha is the murkiness level (distinction in straightforwardness). On the off chance that you want to protect the alpha channel you'll use IMREAD_UNCHANGED. Most of the time you'll perused the color version and after that blur to dim. On the off chance that you do not have a webcam, this will be your fundamental strategy for uploading pictures in this instructional exercise.
XI. FUTURE UPGRADE
A. Coordination Extra Sensor Data
Move forward the body's prescient capabilities by integrating data from extra sensors such as lidar, radar, or IoT devices. Coordination different data sources provides distantly superior, significantly superior, higher, stronger, and enhanced">an enhanced comprehension of soil and the environment, permitting for superior soil forecast. Increment proficiency and minimize drawback.
- This optimization may include model optimization, profound learning, or the utilize of learning methods. By always checking changes and overhauling chance evaluations in like manner, the system can give opportune notices and versatile methodologies to reduce arrive harm. Superior visualize and analyze spatial information with a GIS platform.
- GIS devices can encourage recognizable proof of high-risk areas, back decision-making, and encourage partner coordination in arrive hazard administration. Utilizing input from local communities, geologists and other partners. Crowdsourced data can improve the body's ability to anticipate by providing information on territory features, land utilize alter, and evidence of mudflow occasions.
- Meet the needs of numerous partners, counting crisis responders, urban planners, and foundation designers. These apparatuses ought to provide practical exhortation, recognize risk levels and give direction on preventive measures to decrease the impact of seismic tremor occasions. Viability and opportuneness. Persistently collect input from conclusion clients and partners, conduct validation ponders, and re-improve forms based on truly responsive perceptions and real-world experience.
Conclusion
In outline, the integration of the You\'re Only Looking at One (YOLO) look motor into our geological estimates within the Fastener Twist range represents a major development in geohazard appraisal. YOLO\'s current exactness, accomplished with cautious consideration, and its flexibility to particular highlights of the hair twist speak to a critical enhancement over existing strategies. YOLO operation makes a difference increase the proficiency of the framework, kill limitations and guarantee quality of care in difficult areas. Also, the YOLO association is based on community engagement procedures to provide timely referrals to increase risk administration and engagement. The flexibility of YOLO extends its applications past soil estimation, with the potential to be valuable in numerous geospatial studies. In rundown, the arranging prepare lays the foundation for more profitable, accurate and community-based gauges of soil and leads to nonstop enhancement of the strategy.
References
[1] L. Jiao, F. Zhang, F. Liu, S. Yang, L. Li, Z. Feng, et al., \"A Survey of Deep Learning-Based Object Detection\", IEEE Access, vol. 7, pp. 128837-128868, 2019. [2] M. J. Froude and D. N. Petley, \"Global fatal landslide occurrence from 2004 to 2016\", Natural Hazards Earth Syst. Sci., vol. 18, no. 8, pp. 2161-2181, Aug. 2018. [3] G. Herrera et al., \"Landslide databases in the geological surveys of Europe\", Landslides, vol. 15, no. 2, pp. 359-379, Feb. 2018. [4] P. Distefano, D. J. Peres, P. Scandura and A. Cancelliere, \"Brief communication: Rainfall thresholds based on Artificial neural networks can improve landslide early warning\", Natural Hazards Earth Syst. Sci. Discuss., vol. 2021, pp. 1-9, Jul. 2021.. [5] A. S. Santos, A. C. Corsi, I. C. Teixeira, V. L. Gava, F. A. M. Falcetta, E. S. D. Macedo, et al., \"Brazilian natural disasters integrated into cyber-physical systems: Computational challenges for landslides and floods in urban ecosystems\", Proc. IEEE Int. Smart Cities Conf. (ISC), pp. 1-8, Sep. 2020. [6] S. T. Palliyaguru, L. C. Liyanage, O. S. Weerakoon and G. D. S. P. Wimalaratne, \"Random forest as a novel machine learning approach to predict landslide susceptibility in Kalutara District Sri Lanka\"ICT Emerg. Regions (ICTer), pp. 262-267, Nov. 2020. [7] O. Korup and A. Stolle, \"Landslide prediction from machine learning\", Geol. Today, vol. 30, no. 1, pp. 26-33, Jan. 2020. [8] M. T. Abraham, N. Satyam, N. Shreyas, B. Pradhan, S. Segoni, K. N. A. Maulud, et al., \"Forecasting landslides using SIGMA model: A case study from Idukki India\", Geomatics Natural Hazards Risk, vol. 12, no. 1, pp. 540-559, Jan. 2021. [9] K. Nam and F. Wang, \"An extreme rainfall-induced landslide susceptibility assessment using autoencoder combined with random forest in Shimane Prefecture Japan\", Geoenvironmental Disasters, vol. 7, no. 1, pp. 1-6, Jan. 2020 [10] F. Huang, J. Zhang, C. Zhou, Y. Wang, J. Huang and L. Zhu, \"A deep learning algorithm using a fully connected sparse autoencoder neural network for landslide susceptibility prediction\", Landslides, vol. 17, no. 1, pp. 217-229, Jan. 2020. [11] J. E. Nichol, A. Shaker, and M.-S. Wong, “Application of high-resolution stereo satellite images to detailed landslide hazard assessment,” Geomorphology, vol. 76, no. 1/2, pp. 68–75, 2006. [12] X. X. Zhu et al., “Deep learning in remote sensing: A comprehensive review and list of resources,” IEEE Geosci. Remote Sens. Mag., vol. 5, no. 4, pp. 8–36, Dec. 2017. [13] F. Catani, “Landslide detection by deep learning of non-nadiral and crowdsourced optical images,” Landslides, vol. 18, no. 3, pp. 1025–1044, 2021. [14] Z. Li, W. Shi, P. Lu, L. Yan, Q. Wang, and Z. Miao, “Landslide mapping from aerial photographs using change detection-based Markov random field,” Remote Sens. Environ., vol. 187, pp. 76–90, 2016, doi: 10.1016/j.rse.2016.10.008. [15] J. G. Speight, “Landform pattern description from aerial photographs,” Photogrammetria, vol. 32, no. 5, pp. 161–182, 1977. 1016 IEEE JOURNAL OF SELECTED TOPICS IN APPLIED EARTH OBSERVATIONS AND REMOTE SENSING, VOL. 16, 2023 [16] H. Cai, T. Chen, R. Niu, and A. Plaza, “Landslide detection using densely connected convolutional networks and environmental conditions,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 14, pp. 5235–5247, May 2021. [17] G. Danneels, E. Pirard, and H.-B. Havenith, “Automatic landslide detection from remote sensing images using supervised classification methods,” in Proc. IEEE Int. Geosci. Remote Sens. Symp., 2007, pp. 3014–3017. [18] V. Moosavi, A. Talebi, and B. Shirmohammadi, “Producing a landslide inventory map using pixel-based and object-oriented approaches optimized by Taguchi method,” Geomorphology, vol. 204, pp. 646–656, 2014. [19] D. T. Bui et al., “Landslide detection and susceptibility mapping by airsar data using support vector machine and index of entropy models in Cameron highlands, Malaysia,” Remote Sens., vol. 10, no. 10, 2018, Art. no. 1527. [20] A. Stumpf and N. Kerle, “Object-oriented mapping of landslides using random forests,” Remote Sens. Environ., vol. 115, no. 10, pp. 2564–2577, 2011 [21] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “Mobilenetv2: Inverted residuals and linear bottlenecks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2018, pp. 4510–4520. [22] A. Odena, V. Dumoulin, and C. Olah, “Deconvolution and checkerboard artifacts,” 2016. [Online]. Available: https://distill.pub/2016/deconvcheckerboard/ [23] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in Proc. 4th Int. Conf. 3D Vis., 2016, pp. 565–571. [24] Y. Ho and S. Wookey, “The real-world-weight cross-entropy loss function: Modeling the costs of mislabeling,” IEEE Access, vol. 8, pp. 4806–4813, 2020. [25] E. W. Weisstein, “Moore neighborhood,” From MathWorld–A Wolfram Web Resource, 2005. [Online]. Available: http://mathworld.wolfram.com/MooreNeighborhood.html [26] E. E. Brabb, “Innovative approaches to landslide hazard and risk mapping,” in Proc. Int. Landslide Symp., 1985, pp. 17–22. [27] S. D. Pardeshi, S. E. Autade, and S. S. Pardeshi, “Landslide hazard assessment: Recent trends and techniques,” Springer Plus, vol. 2, no. 1, pp. 1–11, 2013. [28] Y. Wang, Z. Fang, and H. Hong, “Comparison of convolutional neural networks for landslide susceptibility mapping in Yanshan County, China,” Sci. Total Environ., vol. 666, pp. 975–993, 2019. [29] Z. Fang, Y. Wang, L. Peng, and H. Hong, “Integration of convolutional neural network and conventional machine learning classifiers for landslide susceptibility mapping,”Comput. Geosci., vol. 139, 2020, Art. no. 104470. [30] H. Wang, L. Zhang, H. Luo, J. He, and R. Cheung, “AI-powered landslide susceptibility assessment in Hong Kong,” Eng. Geol., vol. 288, 2021, Art. no. 106103. [31] P. Krähenbühl and V. Koltun, “Efficient inference in fully connected CRFs with Gaussian edge potentials,” Adv. Neural Inf. Process. Syst., vol. 24, pp. 109–117, 2011. [32] J. Shotton, J. Winn, C. Rother, and A. Criminisi, “Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context,” Int. J. Comput. Vis., vol. 81, no. 1, pp. 2–23, 2009. [33] P. Soille, Morphological Image Analysis: Principles and Applications. Berlin, Germany: Springer-Verlag, 1999. [34] Z. Li, W. Shi, S. W. Myint, P. Lu, and Q. Wang, “Semi-automated landslide inventory mapping from bitemporal aerial photographs using change detection and level set method,” Remote Sens. Environ., vol. 175, pp. 215–230, 2016. [35] Z. Y. Lv, W. Shi, X. Zhang, and J. A. Benediktsson, “Landslide inventory mapping from bitemporal high-resolution remote sensing images using change detection and multiscale segmentation,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 11, no. 5, pp. 1520–1532, May 2018. [36] Angelova, A, Krizhevsky, A, Vanhoucke, V, Ogale, A and Ferguson, D in a paper presented at BMVC 2021
Copyright
Copyright © 2024 Dr. U. Surendar , Nithishkannan K T, Jansi Rani REL, Harshitha Sai D. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61669
Publish Date : 2024-05-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online