

Ijraset Journal For Research in Applied Science and Engineering Technology
A Review on Object Detection for Autonomous Vehicles
Authors: Akshata Landge, Shreyash Marotkar , Rohan Shelar , Kshitij Kolte, Prof. Varsha Babar
DOI Link: https://doi.org/10.22214/ijraset.2025.66191
Certificate: View Certificate
Abstract
The automation industries have been developing since the first demonstration in the period 1980 to 2000 it is mainly used on automated driving vehicle. Now a day’s automotive companies, technology companies, government bodies, research institutions and academia, investors and venture capitalists are interested in autonomous vehicles. In this work, object detection on road is proposed, which uses deep learning (DL) algorithms. You only look once (YOLO V3, V4, V5). Object detection is an essential component of perception in autonomous vehicles, forming the basis for navigation, collision avoidance, and scene understanding. Additionally, recent fusion techniques combining LiDAR, radar, and visual data, such as MV3D and AVOD, offer improvements in occlusion handling and distance estimation, contributing to better performance in real-world scenarios. The challenges of object detection under adverse conditions, including low-light and inclement weather, are also addressed by techniques such as robust multi-sensor fusion and novel data augmentation methods.
Introduction
I. INTRODUCTION
Traditional computer vision techniques have made significant contributions to object detection. However, their limitations in handling complex scenarios with diverse objects and varying environmental conditions have led to the emergence of deep learning as a powerful solution [1]. Deep learning, especially convolutional neural networks (CNNs), has demonstrated remarkable capabilities in learning hierarchical representations, enabling the development of sophisticated object detection models. The field continues to face numerous challenges. Autonomous vehicles must detect objects accurately under varying lighting conditions, adverse weather, and in densely populated or high-speed environments. The development of robust object detection methods capable of overcoming these obstacles is crucial for achieving higher levels of autonomy. Datasets like KITTI, Open Dataset have been instrumental in pushing research forward, providing large-scale, annotated data for training and evaluation. Over the past decade, significant research has been dedicated to improving object detection accuracy and efficiency, with approaches ranging from traditional image processing techniques to deep learning models. Early object detection relied on hand-crafted features and classic computer vision techniques, but these methods often struggled in complex, dynamic driving environments. The advent of convolutional neural networks (CNNs) transformed the field by enabling more accurate and faster object detection in diverse conditions. Single-shot models, such as YOLO (You Only Look Once) and SSD (Single Shot Multibox Detector), demonstrated the feasibility of real-time detection, while two-stage models like Faster R-CNN provided high accuracy at the cost of increased computational resources.
II. METHODS FOR OBJECT DETECTION
Figure 1 Types of methods
1) YOLOv3: YOLOv3 marked a significant improvement in object detection for autonomous vehicles due to its enhanced architecture and focus on real-time performance. It introduced Darknet-53 as its backbone, replacing the previous Darknet-19 model, which allowed for better feature extraction without a major sacrifice in speed. This improvement is essential for autonomous vehicles, as they require high processing speeds to make split-second decisions in dynamic environments. YOLOv3 also utilized multi-scale detection by detecting objects at three different scales, which enhanced its ability to identify both large and small objects—an advantage for applications that need to recognize large objects like vehicles and smaller objects like traffic signs. Additionally, the introduction of anchor boxes allowed YOLOv3 to handle varying object shapes and sizes, providing better localization of pedestrians, cars, and road signs in complex, real-world scenarios. However, YOLOv3 faced challenges in scenarios with small, overlapping objects and situations with poor lighting, which sometimes affected its detection accuracy.
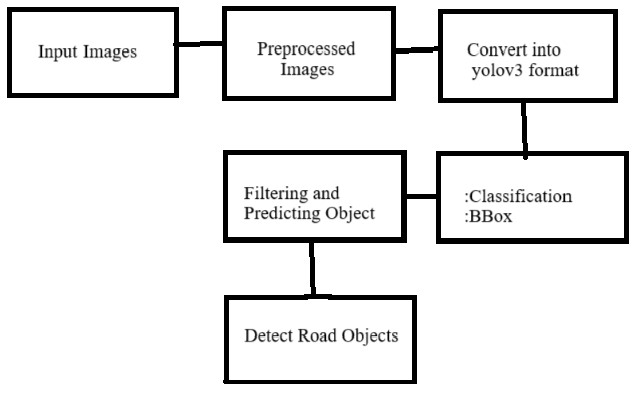
Figure 2 Yolov3
2) YOLOv4: YOLOv4 built upon YOLOv3’s foundation with a series of optimizations that further enhanced performance, making it even more suitable for autonomous vehicles. It introduced CSPDarknet53 as a more efficient backbone, which reduced computation while maintaining high detection accuracy, essential for real-time applications on resourceconstrained hardware often used in vehicles. YOLOv4 also leveraged a range of data augmentation techniques, like Mosaic data augmentation, which helped improve the model's robustness to environmental variations such as changes in lighting and weather conditions. The model also integrated the Spatial Pyramid Pooling (SPP) module to capture features at different scales, further improving detection accuracy. Additionally, YOLOv4's use of CIoU (Complete Intersection over Union) loss improved bounding box localization, which is critical for precise object detection in fast-moving autonomous vehicle environments. Overall, YOLOv4's improvements make it well-suited for handling the complex detection needs of autonomous driving, addressing limitations found in YOLOv3.
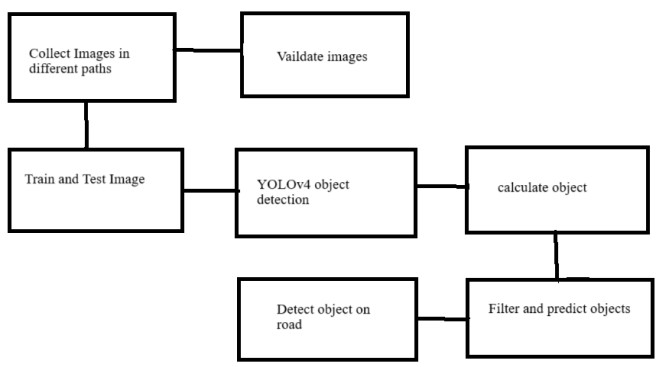
Figure 3 Yolov4
3) YOLOv5: YOLOv5 is a popular open-source object detection model within the YOLO (You Only Look Once) family, known for its balance of speed, accuracy, and efficiency. Developed by Ultralytics and released in 2020, it was built independently from the original YOLO models by Joseph Redmon. Implemented in PyTorch, YOLOv5 is designed to be lightweight, enabling quick training and deployment with lower memory requirements. Its architecture includes four main variants—YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x—allowing users to choose a model based on their specific need for speed or accuracy, which makes it adaptable to various applications, from edge devices to cloud environments. This design is complemented by its user-friendly interface, streamlined transfer learning capabilities, and integration features, making it suitable for custom object detection tasks even with smaller datasets. YOLOv5 achieves high accuracy and low inference latency, benefiting from techniques like mosaic augmentation and self-adversarial training to improve the detection of small or partially occluded objects. Its compatibility with various export formats, such as ONNX and Core ML, further simplifies integration across different platforms. Supported by an active open-source community, [4]YOLOv5 continuously benefits from updates and optimizations, ensuring it remains relevant and reliable for real-time applications in fields like security, retail, and autonomous driving.
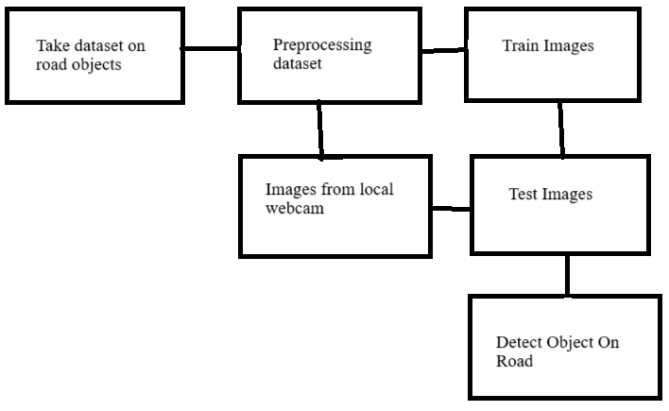
Figure 4 Yolov5
III. ARCHITECTUERE
The architecture begins with the Camera System, which captures raw images from the environment, initiating the process by providing visual data for analysis. This raw data is then sent to the Data Preprocessing module, where it undergoes enhancement and filtering to improve image quality and remove noise, optimizing it for accurate detection. The preprocessed data is forwarded to the Object Detection Module, which identifies objects within the image, such as obstacles or relevant entities in the camera's view. Detected objects are passed to the Threshold and Validation stage, where they are checked against specific criteria like size or distance to ensure they meet necessary standards. Only objects that pass this validation are considered valid and sent to Object PostProcessing, where further refinement or categorization may occur to prepare the data for decision-making. The processed objects are then utilized by the Vehicle Control System, enabling it to make informed decisions such as steering, braking, or adjusting speed based on the detected obstacles or objects. In cases where issues arise, such as a Camera Failure or Processing Failure, an Alert Message is generated to notify the system or operators, ensuring they are aware of the malfunction and can take corrective actions. This architecture ensures a structured flow from image capture to vehicle control, with validation and alert mechanisms enhancing system reliability.
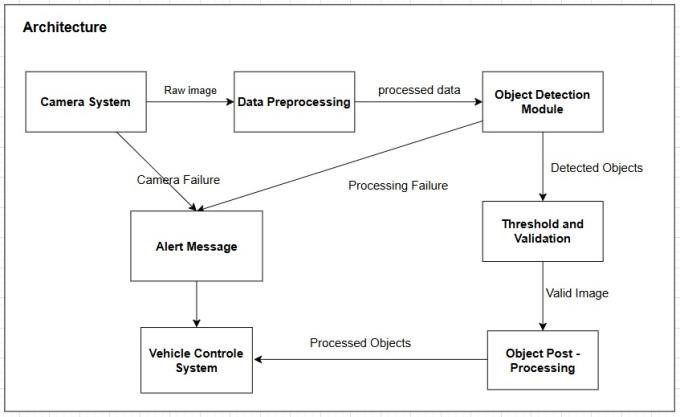
Figure 5 Architecture
Conclusion
In conclusion, so we conclude that all methods of object detection are satistifed .But the yolov5 contains more accuracy and precision. The advancement of object detection technologies has significantly impacted the field of autonomous vehicles, providing enhanced perception, safety, and decision-making capabilities. Through this survey, we have examined the state-of-the-art methodologies, frameworks, and models tailored to object detection for autonomous vehicles, including traditional computer vision techniques, deep learning models, and real-time processing innovations. While deep learning-based approaches, particularly convolutional neural networks and transformer-based models, have demonstrated remarkable accuracy, challenges remain in achieving robust performance in dynamic and diverse environments.
References
[1] Leandro Alexandrino, Hadi Z. Olyaei, André Albuquerque, Petia Georgieva, Miguel Drummond : \"3D Object Detection for Self-Driving Vehicles Enhanced by Object Velocity\", IEEE Article 2024. [2] V. Kukkala, et al. “Advanced Driver Assistance Systems: A Path Toward Autonomous Vehicles “, IEEE Consumer Electronics, Sept 2018. [3] P. Zhao, et al. \"Neural Pruning Search for Real-Time Object Detection of Autonomous Vehicles,\" ACM/IEEE DAC, 2021. [4] L. Jiao, et al. \"A Survey of Deep Learning-Based Object Detection,\" in IEEE Access, vol. 7, pp. 128837-128868, 2019. [5] J. Redmon and A. Farhadi, \"YOLO9000: Better, Faster, Stronger,\" IEEE CVPR, 2017. [6] M. Simon et al. \"Complexer-YOLO: Real-time 3D object detection and tracking on semantic point clouds\", Proc. IEEE CVPR Workshops, 2019. [7] L. H. Wen, et al., \"Fast and Accurate 3D Object Detection for LidarCamera-Based Autonomous Vehicles Using One Shared Voxel-Based Backbone,\" in IEEE Access, vol. 9, pp. 22080-22089, 2021. [8] D. Xuerui et. al. “TIRNet: Object detection in thermal infrared images for autonomous driving”, Applied Intelligence, 2021. [9] Y. Zhu et al. “Acceleration of pedestrian detection algorithm on novel C2RTL HW/SW co-design platform.” IEEE ICGCS, 2010. [10] Lu, Yantao, et al. \"RAANet: Range-Aware Attention Network for LiDAR-based 3D Object Detection with Auxiliary Density Level Estimation.\" arXivpreprintarXiv:2111.09515,2021.
Copyright
Copyright © 2025 Akshata Landge, Shreyash Marotkar , Rohan Shelar , Kshitij Kolte, Prof. Varsha Babar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66191
Publish Date : 2024-12-30
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online