

Ijraset Journal For Research in Applied Science and Engineering Technology
Object Detection in Real-time Video
Authors: Sahil Kanojia, Darshan Kaur, Ritviik Kumar, Gaganjyot Singh Sehgal
DOI Link: https://doi.org/10.22214/ijraset.2024.65219
Certificate: View Certificate
Abstract
Object detection in actual-time video is a important challenge in many programs, which includes autonomous driving, surveillance, and human-computer interplay. With the upward push of deep learning, models which include Convolutional Neural Networks (CNNs) have substantially stepped forward detection accuracy, however their excessive computational needs frequently restrict actual-time performance. This paper explores the evolution of item detection techniques, with a focus at the YOLO (You Only Look Once) framework, which addresses the want for both velocity and accuracy in real-time programs. YOLO transforms item detection right into a single regression problem, permitting high frame costs appropriate for actual-time video processing. We take a look at the performance of numerous YOLO variations (YOLOv3, YOLOv4, YOLOv5) in terms of detection accuracy, processing velocity, and computational performance, particularly in useful resource-restricted environments. Additionally, we examine the exchange-offs between speed and accuracy, especially in complicated environments regarding low lighting, occlusion, and ranging item sizes. Furthermore, we check out optimization techniques, such as model pruning, quantization, and hardware acceleration, to beautify YOLO’s actual- time performance. The effects demonstrate that YOLO, with proper optimization, can provide an effective answer for actual- time item detection, balancing pace and accuracy throughout various application situations. We finish by providing upgrades and destiny studies directions to conquer modern limitations and similarly increase the country of real-time item detection.
Introduction
I. INTRODUCTION
Object detection in actual-time video has emerged as a pivotal place of studies with widespread implications for numerous sensible packages, which include independent using, video surveillance, healthcare monitoring, and robotics. The goal of item detection is not simplest to identify objects inside video frames but also to localize and classify them correctly at the same time as tracking their actions through the years. Achieving actual-time overall performance introduces additional complexities, because the gadget must technique a continuous movement of data with minimum latency, ensuring that detection occurs rapidly sufficient for programs that Identify applicable funding agency here. If none, delete this. require on the spot selection-making. Recent improvements in deep studying, mainly via convolutional neural networks (CNNs), have brought about vast enhancements in the overall performance of item detection systems. One of the most incredible frameworks in this domain is the ”You Only Look Once” (YOLO) set of rules, which has received significant rep- utation for its stability between velocity and accuracy. Unlike traditional item detection techniques, which carry out detection in more than one ranges, YOLO reframes item detection as a unmarried regression trouble. This approach permits YOLO to process complete photos in actual-time, achieving detection fees that surpass many traditional strategies, making it in par- ticular suitable for packages that require high-velocity process- ing. Despite those advances, real-time item detection neverthe- less faces several challenges. The dynamic nature of real-world environments way that systems ought to deal with versions in lighting, occlusion, and item scales whilst preserving correct detection. Furthermore, the computational constraints of area gadgets and embedded structures, frequently used in actual- time programs, demand efficient algorithms that minimize resource usage with out sacrificing overall performance. This paper objectives to explore and evaluate present day tactics to real-time item detection, with a focal point on the YOLO own family of algorithms. It will cope with key considerations such as detection pace, accuracy, computational performance, and robustness under various conditions. Additionally, we can discuss capacity optimizations and diversifications of YOLO and similar fashions for deployment in limited environments in which processing power and memory are confined.
II. DEEP LEARNING ARCHITECTURES FOR OBJECT DETECTION
The discipline of item detection has skilled tremendous de- velopment due to improvements in deep learning, particularly the software of Convolutional Neural Networks (CNNs). These models have converted how item detection is finished with the aid of studying capabilities directly from facts, enabling surprisingly correct object localization and classification. The development of these architectures commonly revolves round improving detection pace, accuracy, and scalability. The fol- lowing section offers a top level view of the maximum out- standing deep learning architectures used for object detection in actual-time video applications.
A. Region-Based Convolutional Neural Networks (R-CNN)
Region-based totally Convolutional Neural Networks (R- CNN) have been one of the earliest CNN-based totally techniques for item detection. The original R-CNN model proposed by using Girshick et al. Extracts a huge number of region proposals from the input photo, each of that is processed independently through a CNN to come across items. This approach, whilst correct, turned into computationally expensive and slow, because it required running the CNN on every vicinity proposal, main to more than one redundant computations for overlapping areas.
To overcome the constraints of R-CNN, successive fashions had been delivered:
- Fast R-CNN: This version advanced upon R-CNN with the aid of introducing a shared characteristic extraction com- munity, in which a unmarried CNN bypass generates feature maps for the entire photograph. Region proposals are then mapped onto those feature maps, appreciably lowering the computational overhead.
- Faster R-CNN: Faster R-CNN delivered the Region Proposal Network (RPN), which eliminated the want for an outside area thought algorithm by way of producing location proposals as a part of the community itself. While this model is incredibly correct, its two-stage nature makes it much less appropriate for actual-time programs because of its slower inference speed.
B. Single Shot Multibox Detector (SSD)
The Single Shot Multibox Detector (SSD) was proposed as a quicker opportunity to the R-CNN circle of relatives. Unlike Faster R-CNN, which makes use of a two-level detection pipeline, SSD without delay predicts the class and bounding packing containers of gadgets in a single forward pass of the community. SSD discretizes the output area of bounding containers into a fixed of default packing containers over one of a kind thing ratios and scales for every characteristic map cellular, allowing green multi-scale item detection.
Key features of SSD:
- Multiscale function maps: SSD leverages more than one characteristic maps at one-of-a-kind resolutions to stumble on objects of varying sizes, improving its overall performance on each massive and small items.
- Speed and accuracy alternate-off: While SSD is faster than Faster R-CNN, its accuracy, specifically for small gad- gets, tends to be lower. Nonetheless, SSD strikes a great stability between speed and accuracy, making it a famous preference for actual-time item detection in video streams.
C. YOLO (You Only Look Once)
You Only Look Once (YOLO) is one of the maximum extensively used architectures for real-time item detection, acknowledged for its simplicity and velocity. Unlike R-CNN- based totally models, which first generate location proposals after which classify them, YOLO formulates object detection as a unmarried regression trouble. The community takes the whole photo as enter and divides it into a grid, predicting bounding packing containers and sophistication possibilities for each grid cellular in a unmarried ahead pass.
Key benefits of YOLO:
- Single-stage architecture: YOLO performs each object localization and type in a unmarried step, drastically improving its inference pace.
- High body charges: YOLO fashions, specially the more current versions inclusive of YOLOv4 and YOLOv5, can procedure as much as 45 frames in step with 2d (FPS) on modern hardware, making them ideal for actual-time packages like self sustaining using and surveillance.
- Global context: Since YOLO looks at the complete image right now, it captures worldwide statistics ap- proximately the image, reducing false positives in con- ditions wherein objects are detected in context. Despite those benefits, early variations of YOLO suffered from decrease accuracy when detecting small gadgets and gadgets in complicated backgrounds. However, more moderen versions like YOLOv4 and YOLOv5 have delivered numerous upgrades, which includes higher anchor container technology and use of attention mech- anisms, main to better accuracy at the same time as preserving pace.
D. Summary of Architectures
The evolution of object detection architectures reflects a shift toward fashions that stability velocity and accuracy to satisfy real-time overall performance demands. Single-stage detectors like YOLO and SSD have set the benchmark for real-time applications, providing rapid and relatively accurate detection in video streams.
On the alternative hand, two-stage detectors, while extra computationally expensive, continue to be valuable for tasks requiring high precision, specifically in situations in which small objects or complex backgrounds are commonplace. As hardware hastens and deep mastering techniques continue to adapt, hybrid strategies may also emerge that in addition optimize the exchange-off among accuracy and velocity
III. OPTIMIZATION TECHNIQUES
A. Model Compression
Model compression strategies purpose to reduce the scale and complexity of deep getting to know models even as preserving appropriate ranges of accuracy. Compression will become crucial while deploying fashions on useful resource- constrained devices or for actual-time video processing tasks, in which each memory and compute energy can be con- fined. There are 3 extensively used strategies for compressing deep studying models: pruning, quantization, and weight sharing.
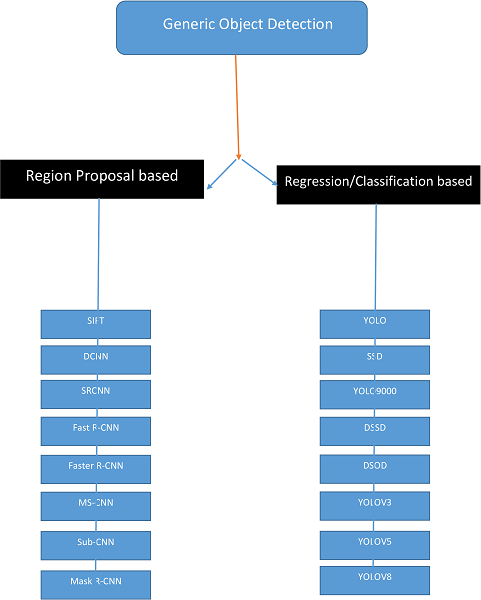
Fig. 1. Architecture of YOLO compared to traditional CNN-based detectors.
1) Pruning
Pruning refers back to the removal of pointless weights or neurons from a neural community, which reduces the range of parameters with out extensively degrading the model’s overall performance. There are numerous varieties of pruning:
- Weight pruning: Eliminates man or woman weights with small magnitude, beneath the belief that they make a contribution minimally to the version’s output.
- Neuron pruning: Removes entire neurons or filters, reg- ularly via evaluating their importance at some stage in schooling and discarding people with low activation.
Pruned models require fewer computational resources and memory, that can enhance inference time. Pruning is com- monly applied after a model has been pre-educated, followed by using fine-tuning to regain any misplaced accuracy. For example, making use of pruning techniques to Faster R-CNN or SSD can yield widespread performance profits at the same time as preserving almost the equal accuracy for item detection responsibilities.
2) Quantization
Quantization is a broadly used optimization technique that reduces the precision of the weights and activations in a neural community. Traditional models use 32-bit floating- factor numbers for computation, which may be resource-in depth. Quantization reduces the precision to decrease bit- widths (e.G., sixteen-bit floating-factor or eight-bit integer) to lower the memory and computational requirements of the version.
Quantization may be carried out in ways:
- Post-education quantization: After education a version, weights are quantized without any additional great- tuning. This is the only shape of quantization and gives instantaneous performance improvements.
- Quantization-conscious schooling (QAT): During the schooling method, the model is made privy to the quan- tization process, main to higher final accuracy while quantized weights are used.
Eight-bit integer quantization is particularly powerful for real- time programs, because it hastens inference with the aid of reducing each reminiscence bandwidth and compute load, in particular on hardware accelerators like GPUs and TPUs. Quantized versions of models like YOLO and SSD are fre- quently deployed on cell and aspect devices to gain actual-time item detection with minimum loss in accuracy.
3) Weight Sharing
Weight sharing includes sharing a not unusual set of param- eters among multiple layers or areas of a neural community, which reduces the quantity of independent parameters. This is particularly beneficial for convolutional layers where filters may be reused across exceptional layers. Weight sharing can cause a greater compact model with out big degradation in overall performance, making it a really perfect optimization approach for resource-restrained environments.
B. Knowledge Distillation
Knowledge distillation is a method wherein a smaller, greater efficient version (known as the pupil version) is edu- cated to imitate the behavior of a larger, extra correct version (referred to as the trainer model). The teacher version is normally a high-capacity network with excellent accuracy but is just too gradual or aid-intensive for actual-time applications. During the distillation procedure, the student model is trained now not best at the ground-reality labels however additionally on the tender predictions of the trainer model. These soft predictions comprise richer facts, permitting the student version to examine extra correctly and generalize higher.
The advantages of understanding distillation include:
Smaller version length: The student version is typically an awful lot smaller than the instructor model, making it extra appropriate for real-time inference.
Improved performance: Despite being smaller, the student version can retain much of the trainer model’s overall per- formance, in particular when compared to schooling a small version from scratch.
For instance, expertise distillation can be used to compress big fashions like Faster R-CNN into light-weight fashions which can carry out item detection in real-time. This technique is particularly useful for deploying detection fashions on facet gadgets where computational sources are limited.
IV. HARDWARE ACCELERATION AND EDGE COMPUTING
A. Hardware Acceleration
As item detection models become more complicated to enhance accuracy, the demand for computational assets has grown extensively. However, actual-time programs together with self sustaining automobiles, video surveillance, and aug- mented fact require both high-overall performance inference and occasional-latency processing. Hardware acceleration and aspect computing have emerged as crucial solutions to meet these requirements. This segment explores how specialised hardware and area computing paradigms are employed to boost up deep getting to know fashions for item detection in actual-time packages.
TABLE I
Comparison of Object Detection Models by Speed and
Accuracy
|
Model |
Speed (FPS) |
Accuracy (mAP) |
|
YOLOv4 |
45 |
43.5 |
|
SSD |
59 |
41.3 |
|
Faster R-CNN |
7 |
50.3 |
B. Graphics Processing Units (GPUs)
Graphics Processing Units (GPUs) are the most broadly used hardware accelerators for deep getting to know obliga- tions. Originally designed for rendering portraits, GPUs are rather green at parallel processing, making them best for the matrix operations that underpin convolutional neural networks (CNNs) utilized in item detection.
Key advantages of GPUs in item detection consist of: Massive parallelism: GPUs incorporate hundreds of cores, allowing them to method more than one operations concurrently, which hastens each training and inference.
Optimized libraries: Platforms like CUDA (Compute Unified Device Architecture) and cuDNN (CUDA Deep Neural Network) are especially designed to optimize neural network operations on NVIDIA GPUs, ensuring most performance for object detection fashions which includes Faster R-CNN, YOLO, and SSD.
GPUs are used notably in actual-time applications, specifically in eventualities that require excessive-resolution object detection, along with video streams from surveillance cameras or drones.
C. Tensor Processing Units (TPUs)
Tensor Processing Units (TPUs) are specialised hardware evolved with the aid of Google specifically for accelerating device learning responsibilities. TPUs are optimized for the operations required by deep gaining knowledge of models, to- gether with matrix multiplications, and they could outperform GPUs for positive obligations, in particular in the course of inference.
Low precision computation: TPUs use low-precision arithmetic (e.G., eight-bit integers), which allows them to perform extra operations in keeping with second compared to GPUs while ingesting less strength.
High throughput: TPUs are able to performing trillions of operations according to 2d, which makes them ideal for actual- time item detection in huge-scale applications inclusive of cloud-based totally video processing.
The Edge TPU variant, especially designed for aspect computing, is compact and energy-green, making it properly- ideal for real-time item detection on edge gadgets.
D. Field-Programmable Gate Arrays (FPGAs)
Field-Programmable Gate Arrays (FPGAs) are flexible hard- ware accelerators that may be customized for precise work- loads, which includes deep getting to know inference. FPGAs provide numerous advantages for object detection, specially in actual-time and embedded systems:
Customizability: Unlike GPUs and TPUs, which have con- stant architectures, FPGAs may be reprogrammed to optimize particular neural network operations, including convolutional layers or fully related layers.
Low strength consumption: FPGAs are extra energy-green than GPUs and are frequently used in embedded structures and IoT (Internet of Things) gadgets that require actual-time item detection.
FPGAs are generally used in scenarios in which power efficiency and latency are important, along with in drones, self reliant motors, or smart cameras for actual-time video analysis. They allow for noticeably green inference pipelines that meet the restrictions of edge computing environments.
E. Neural Processing Units (NPUs)
Neural Processing Units (NPUs) are specialized processors designed for accelerating synthetic intelligence obligations, specifically deep gaining knowledge of operations. NPUs are optimized for the computation styles visible in neural networks, consisting of matrix multiplications and activation features.
Mobile and area tool deployment: NPUs are an increas- ing number of included into cell processors, allowing real- time object detection on smartphones and different portable gadgets. For instance, Apple’s Neural Engine and Huawei’s Kirin NPU are designed to accelerate tasks like face reputation, augmented reality, and real-time video evaluation.
NPUs represent the subsequent era of hardware acceleration, especially for cell and area computing systems in which each performance and electricity performance are paramount.
F. Edge Computing
Edge computing is a allotted computing paradigm where statistics processing occurs toward the facts supply, in place of relying on centralized cloud servers. For actual-time object detection, aspect computing offers several key blessings:
Low latency: By processing information regionally, part computing reduces the latency related to sending records to and from far flung servers, that is essential for actual-time programs.
Reduced bandwidth utilization: Processing statistics at the threshold minimizes the want to transmit huge amounts of uncooked video or picture information over the network, thereby preserving bandwidth.
Enhanced privateness and safety: Since information is processed locally, area computing reduces the exposure of sensitive statistics, consisting of video footage, to capability breaches during transmission to cloud servers.
G. Edge Devices for Object Detection
Edge computing relies on powerful, strength-efficient de- vices which might be capable of going for walks item detection fashions regionally. These devices are frequently ready with hardware accelerators together with GPUs, FPGAs, or TPUs to make sure that object detection fashions can meet the real- time requirements of applications.
Smart Cameras: Smart cameras ready with embedded GPUs or FPGAs can run object detection models domestically, supplying instant insights with out the want to transmit video streams to far off servers. These cameras are widely used in video surveillance, site visitors tracking, and retail analytics.
Drones: In drone-primarily based programs, real-time object detection is important for navigation, obstacle avoidance, and item tracking. Edge computing allows drones to technique video information domestically with out the need for con- sistent communication with ground stations, permitting faster reaction instances and decreasing communique delays.
Autonomous Vehicles: Edge computing performs a impor- tant role in self sufficient cars, in which actual-time object detection is needed for pedestrian popularity, visitors signal de- tection, and collision avoidance. The capacity to method sensor statistics regionally ensures that automobiles can make split- 2nd decisions, improving protection and lowering reliance on cloud-based totally structures.
H. Edge Computing Frameworks
To facilitate item detection on part gadgets, numerous frameworks were advanced that optimize the deployment of deep mastering models in facet environments.
TensorFlow Lite: TensorFlow Lite is a light-weight model of the TensorFlow framework designed for mobile and em- bedded devices. It supports model quantization, decreasing the dimensions of object detection models for green deployment on side devices. TensorFlow Lite also integrates with hardware accelerators which include the Edge TPU for stepped forward inference velocity.
NVIDIA Jetson: NVIDIA’s Jetson platform affords a com- prehensive answer for side computing, offering excessive- overall performance GPUs and libraries like TensorRT for accelerating deep mastering fashions. The Jetson family of devices is extensively utilized in drones, robotics, and smart cameras for actual-time item detection.
AWS Greengrass: AWS Greengrass is an part computing service supplied by Amazon Web Services that lets in neigh- borhood execution of cloud-primarily based machine getting to know models. Greengrass integrates with facet devices to run inference responsibilities, allowing object detection fashions to function independently of the cloud whilst nevertheless cashing in on periodic updates.
I. Benefits of Hardware Acceleration and Edge Computing
The mixture of hardware acceleration and side computing gives several key blessings for actual-time object detection:
Improved Latency: Local processing at the brink removes the latency associated with transmitting records to centralized cloud servers, making it best for time-crucial applications like autonomous driving, actual-time surveillance, and interactive augmented truth.
Energy Efficiency: By utilizing specialized hardware ac- celerators including FPGAs, NPUs, and TPUs, side gadgets can carry out item detection effectively at the same time as retaining power. This is especially important for battery- operated gadgets like drones or IoT sensors.
Scalability: Edge computing allows for scalable deployment of item detection structures. Instead of overloading a primary server with more than one video streams, each aspect tool can independently process its information, allowing huge-scale, distributed applications.
Data Privacy: Processing touchy video records domestically at the edge enhances privacy and security with the aid of decreasing the want to transmit raw footage over networks, which can be at risk of interception or breaches.
V. CHALLENGES IN REAL-TIME OBJECT DETECTION
A. Computational Complexity
One of the most vast challenges in actual-time item detec- tion is the computational complexity of current deep mastering models. Advanced architectures like Faster R-CNN, YOLOv4, and EfficientDet require vast computational resources, as they contain thousands and thousands of parameters and operations for every inference. This complexity is similarly amplified while detecting objects in high-resolution video streams or coping with multiple objects concurrently.
Real-time item detection fashions should system every body within a strict time window to hold high frame fees (e.G., 30–60 frames in line with second). Achieving this performance frequently calls for specialized hardware accelerators like GPUs or TPUs, which may not be to be had in all deploy- ment environments, along with low-electricity side gadgets or mobile structures.
1) Network Depth and Latency
Deeper and greater complex networks typically acquire higher accuracy in object detection however introduce better latency due to the increased quantity of layers and parameters. For example, fashions like Faster R-CNN offer excessive precision however are computationally costly, making them flawed for actual-time processing with out optimization.
Finding the right stability among version depth, accuracy, and inference speed is a constant challenge in actual-time detection systems. Researchers need to layout architectures that may limit the latency without sacrificing an excessive amount of accuracy, regularly requiring huge version optimiza- tion strategies such as pruning, quantization, and knowledge distillation.
B. Trade-offs Between Accuracy and Speed
Real-time object detection regularly includes change-offs among speed and accuracy. Faster models, including YOLO (You Only Look Once) and SSD (Single Shot Multibox Detector), prioritize inference speed by the use of lightweight architectures and making layout alternatives that reduce com- putational demands. However, those models may additionally sacrifice some degree of detection accuracy or robustness compared to slower, extra complicated fashions like Faster R- CNN or RetinaNet.
- Precision in Challenging Scenarios Object detection models need to keep excessive accuracy across a extensive range of conditions, including:
Occlusion: Objects can be partially hidden via different objects, leading to incomplete or wrong detections.
Small Objects: Detecting small or remote gadgets is greater computationally high priced and errors-inclined, as models need to capture nice information.
Lighting Variations: Changes in lights, shadows, or re- flections can negatively effect version overall performance, specifically in outside environments.
These challenges frequently require additional computa- tional resources to enhance detection precision, which in flip can sluggish down the inference speed, complicating the purpose of real-time processing.
C. Handling Dynamic and Complex Environments
Real-time item detection structures are regularly deployed in dynamic environments where objects may pass unpredictably, lighting conditions can also alternate, and scenes may be cluttered with more than one objects. Ensuring robustness in such environments is a major challenge.
1) Real-Time Tracking
In video streams, gadgets may input and leave the body, alternate orientation, or pass at varying speeds. Maintaining consistent detection outcomes across frames is critical for applications together with self sufficient driving, wherein overlooked detections should result in important screw ups. Real-time item tracking algorithms are regularly included with detection structures to ensure continuity and accuracy, but this adds additional computational complexity.
2) Background Clutter
In complicated scenes with many overlapping gadgets or noisy backgrounds, distinguishing among gadgets of hobby and inappropriate heritage functions will become greater hard. The presence of clutter can lead to false positives or neglected detections, and models want to be robust enough to accurately section gadgets in such eventualities even as still processing each frame speedy
D. Limited Hardware Resources
Another tremendous project in actual-time item detection is the restrained hardware assets to be had in many deployment environments. While excessive-performance GPUs and TPUs can boost up inference times, they may be no longer always feasible in real-global scenarios due to fee, size, power intake, or availability constraints.
- Mobile and Edge Devices Edge computing structures, inclusive of IoT gadgets, drones, or mobile phones, frequently have strict useful resource barriers. They are commonly equipped with low-strength processors and limited reminis- cence, making it hard to set up complicated object detection fashions. Ensuring that fashions can run efficiently on these gadgets without sacrificing an excessive amount of accuracy is a main project.
Energy Efficiency Real-time applications, specifically those deployed in resource-constrained or faraway environ- ments, require strength-efficient object detection fashions. In applications such as drones or autonomous motors, energy performance at once affects battery lifestyles, restricting using energy-hungry hardware accelerators like GPUs. This con- straint makes it important to layout models that strike a stability between power intake and detection performance.
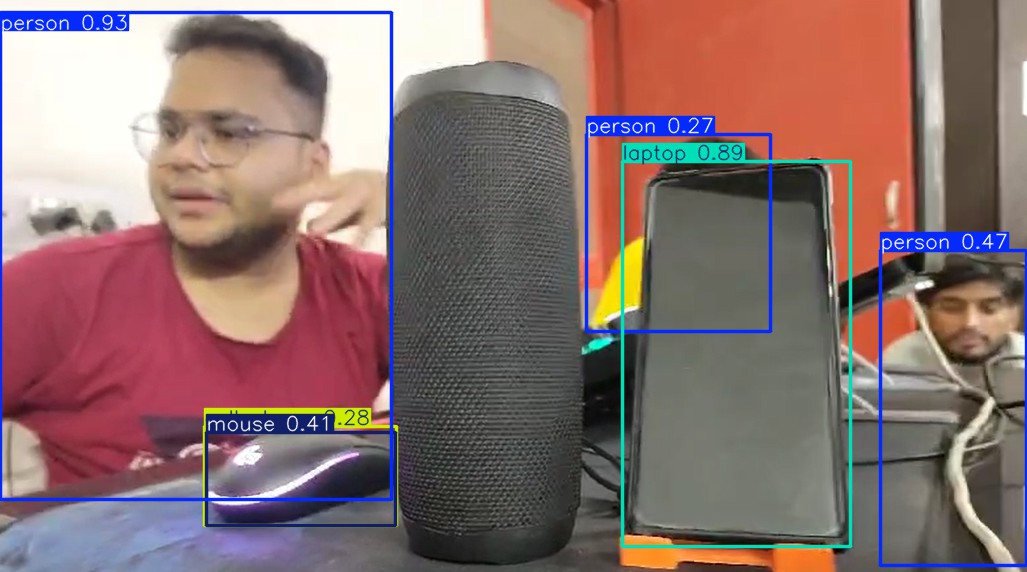
Fig. 2. Architecture of YOLO compared to traditional CNN-based detectors.
VI. FUTURE RESEARCH DIRECTIONS
As actual-time item detection era progresses, several key areas present promising avenues for destiny research. One vital course is the development of light-weight and efficient version architectures. Current state-of-the-art models regularly require substantial computational sources, restricting their deployment in aid-restricted environments including cell gadgets and edge computing situations. Future research ought to consciousness on optimizing architectures thru strategies like model pruning and quantization to reduce complexity while keeping detection accuracy. This will enable broader software of actual-time object detection systems throughout diverse systems. Another vital region is the exploration of Neural Architecture Search (NAS), that could automate the design of network architectures tailor-made for particular tasks and hardware configurations. By using NAS, researchers can find out optimized architec- tures that balance velocity and accuracy, taking into consider- ation greater effective actual-time programs in fields together with self sufficient riding and smart surveillance. Continual studying and on-line edition are vital for reinforcing object detection models in dynamic environments.
As conditions evolve and new object training seem, the ability for models to adapt without full-size retraining is vital. Advancements in domain version and transfer getting to know can enable models to leverage formerly discovered expertise, taking into consideration fast adaptation with minimal information. Additionally, integrating few-shot gaining knowledge of methodologies will help fashions apprehend new items with only some examples, enhancing their versatility. The integration of multi-modal facts is another promising direction. Current item detection structures typically depend upon visual records, but combining inputs from sensors including LiDAR and infrared can notably improve accuracy, especially in hard situations like low mild or detrimental weather. Future research have to attention on developing effective sensor fusion techniques that allow models to procedure and interpret data from multiple assets concurrently. Robustness and interpretability are important for deploying item detection structures in safety- essential applications. As these models grow to be greater complicated, knowledge their decision-making tactics is im- portant for constructing believe. Future studies must cope with adversarial robustness, making sure that fashions are resilient towards diffused attacks that could result in wrong detections. Additionally, enhancing version interpretability will assist users realise how and why choices are made, fostering extra trust in automated structures. Advancements in hardware- aware optimization strategies can also be important. Tailoring object detection fashions to leverage specific hardware talents, along with GPUs and specialized accelerators, can beautify overall performance and efficiency. Co-designing hardware and algorithms will optimize resource utilization, permitting real-time processing in various environments. With the growing significance of side computing, studies into federated mastering presents interesting possibilities for actual-time object detection. This approach lets in fashions to be taught across multiple gadgets with out centralizing touchy facts, addressing privacy concerns whilst enabling continuous development. Future investigations could attention on enforcing federated studying algorithms designed for real-time packages, ensuring low latency and high accuracy.
Finally, the development of privateness-keeping object de- tection methods is increasingly critical. Techniques consisting of differential privacy can assist ensure that touchy records is not compromised at some stage in processing. Explor- ing encrypted object detection methods, wherein information is processed in encrypted formats, can further safeguard privateness in packages like facial recognition and surveil- lance. In summary, the future of real-time object detection holds first-rate promise through ongoing studies in model performance, robustness, hardware optimization, and privacy- keeping strategies. Addressing these challenges and exploring progressive answers will enhance the scalability, accuracy, and applicability of item detection structures throughout numerous domain names, inclusive of independent vehicles and clever surveillance, making them integral to the wise structures of tomorrow.
Conclusion
In this paper, we’ve explored the improvements, demanding situations, and destiny instructions of actual-time item detection structures, that have become increasingly more essential in diverse applications, which includes independent vehicles, clever surveillance, and augmented truth. The fast improvement of deep mastering strategies, specially convolutional neural networks (CNNs), has substantially advanced the accuracy and performance of item detection models. However, demanding situations which includes computational complexity, environmental variability, and the need for real- time processing continue to be vital hurdles. We discussed the significance of light-weight architectures and optimization strategies, inclusive of model pruning and quantization, to permit the deployment of those models in resource-confined environments. Furthermore, we emphasized the capability of neural structure seek (NAS) and the integration of multi-modal statistics to beautify detection accuracy below numerous situations. Additionally, the need for persistent mastering and edition turned into highlighted as essential for maintaining model overall performance in dynamic environments. Looking in advance, the integration of aspect com- puting and federated learning affords exciting opportunities for growing privacy-retaining and green item detection structures. As researchers hold to cope with those challenges, the sector of real-time item detection is poised for transformative boom. By prioritizing robustness, interpretability, and flexibility, future studies can lead to the introduction of greater dependable and versatile detection systems that can effectively reply to real- international needs. In conclusion, the continued advancements in real-time object detection technologies promise to unlock new packages and beautify existing structures, ultimately contributing to the development of smart and autonomous systems which could enhance protection, performance, and consumer enjoy throughout various domain names. Continued collaboration among researchers, practitioners, and industry stakeholders will be important in overcoming cutting-edge limitations and using innovation on this hastily evolving discipline.
References
[1] J. Redmon and A. Farhadi, ”YOLOv3: An Incremental Improvement,” arXiv preprint arXiv:1804.02767, 2018. [2] W. Liu, D. Anguelov, D. Erhan, et al., ”SSD: Single Shot MultiBox Detector,” in Proceedings of the European Conference on Computer Vision (ECCV), 2016, pp. 21-37. [3] S. Ren, K. He, R. Girshick, and J. Sun, ”Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” in IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137-1149, 2017. [4] A. Howard, M. Zhu, B. Chen, et al., ”MobileNets: Efficient Convolu- tional Neural Networks for Mobile Vision Applications,” arXiv preprint arXiv:1704.04861, 2017. [5] T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dolla´r, “Focal Loss for Dense Object Detection” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2999–3007. [6] K. He, G. Gkioxari, P. Dolla´r, and R. Girshick, “Mask R-CNN,” in Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2961–2969. [7] W. Liu, A. Rabinovich, and A. C. Berg, “Ssd: Single Shot MultiBox Detector, in Proceedingsn European Conference on Computer Vision (ECCV), 2016, pp. 21–37. [8] A. K. Jain, “Data Clustering: 50 Years Beyond K-Means,” Pattern Recognition Letters, vol. 31, no. 8, pp. 651–666, 2010. [9] M. Abadi et al., “TensorFlow: A System for Large-Scale Machine Learning, 2th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2016, pp. 265–283. [10] Y. Zhu, Y. Li, and Y. Wang, “Real-Time Object Detection on Mobile Devices” in IEEE Access, vol. 8, pp. 32561–32570, 2020. [11] K. Simonyan and A. Zisserman, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” in Proceedings of the International Conference on Learning Representations (ICLR), 2015. [12] S. R. S. Ranjan, R. D. Gupta, and H. G. Wang, “Edge Computing and Real-Time Object Detection: Challenges and OpportunitiesPIEEE Internet of Things Journal, vol. 7, no. 10, pp. 10234–10245, 2020. [13] A. G. Scherer, S. F. R. L. Comin, and M. A. Schmidt, “Deep Learning for Object Detection: A Survey,” Journal of Visual Communication and Image Representation, vol. 71, pp. 102811, 2020. [14] H. Wang, Y. Zhang, Y. Liu, and W. Feng, “Real-time Video Object Detection Based on Deep Learning: A Survey,” IEEE Access, vol. 9, pp. 84961–84977, 2021. [15] R. J. Mooney and M. K. V. P. K. Raghavan, “Transfer Learning for Image Classification: A Survey,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 12, pp. 3663–3676, 2019. [16] H. G. J. Wang and M. C. Huang, “Multi-Task Learning for Real-Time Object Detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2224–2233. [17] Y. Chen, Y. Li, and H. Zhu, “Efficient Object Detection for Embedded Systems: A Review,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 30, no. 7, pp. 1947–1962, 2020. [18] H. F. G. V. H. D. S. Tran, S. Wang, and W. Zheng, “Federated Learning for Object Detection in Mobile Networks,” IEEE Internet of Things Journal, vol. 8, no. 1, pp. 599–610, 2021.+ [19] M. T. F. G. G. M. A. S. R. M. L. M. N. H. J. Zhang, “Privacy-Preserving Object Detection in Federated Learning Systems,” IEEE Transactions on Information Forensics and Security, vol. 15, pp. 981–994, 2020. [20] Z. D. Z. Y. L. S. M. Wu, “An Overview of Adversarial Attacks and Defense Mechanisms in Deep Learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 4, pp. 1451–1467, 2020.
Copyright
Copyright © 2024 Sahil Kanojia, Darshan Kaur, Ritviik Kumar, Gaganjyot Singh Sehgal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65219
Publish Date : 2024-11-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online