

Ijraset Journal For Research in Applied Science and Engineering Technology
Optimizing Memory Efficiency in Large Language Models: Adaptive Compression Techniques
Authors: Dr. T. Prem Chander
DOI Link: https://doi.org/10.22214/ijraset.2025.66591
Certificate: View Certificate
Abstract
Large Language Models (LLMs) have revolutionized artificial intelligence by achieving unprecedented results across various natural language processing (NLP) tasks. However, their massive memory requirements pose significant challenges for deployment in resource-constrained environments, such as mobile devices and edge computing. This paper introduces an adaptive compression framework to optimize the memory efficiency of LLMs while maintaining their performance. The proposed framework integrates multiple techniques, including quantization, pruning, and knowledge distillation, dynamically adjusting the model size based on specific usage scenarios. Experimental evaluations demonstrate significant reductions in memory usage with minimal accuracy loss, facilitating the practical deployment of LLMs in real-world applications. The results highlight the potential for efficient model optimization, paving the way for broader adoption of AI in resource-constrained environments.
Introduction
I. INTRODUCTION
Large Language Models (LLMs) such as OpenAI’s GPT-3 and Google’s PaLM have set new benchmarks in natural language understanding, generation, and various other NLP tasks. These models, with billions of parameters, exhibit remarkable capabilities but are accompanied by significant computational and memory costs. For instance, GPT-3, with 175 billion parameters, requires substantial hardware resources for training and inference, making it impractical for edge devices or other constrained environments.
The growing demand for deploying LLMs on edge devices, mobile platforms, and embedded systems necessitates innovative techniques to optimize their memory usage without compromising their performance. This need is exacerbated by the proliferation of AI-driven applications, ranging from virtual assistants to automated translation systems. Efficient memory management is not just a technical challenge but also a key enabler for democratizing AI by making advanced models accessible to a broader range of users and industries. While traditional optimization methods such as quantization, pruning, and knowledge distillation have shown promise, their isolated application often fails to fully address the complex trade-offs between memory efficiency and model accuracy. This paper proposes an Adaptive Compression Framework (ACF) that integrates these techniques dynamically, tailoring model compression to specific deployment scenarios and hardware constraints. The proposed system also aligns with global efforts to enhance sustainable AI by reducing energy consumption associated with large-scale model deployment.
II. RELATED WORK
Memory optimization for LLMs has been an area of active research. Various techniques have been explored to address the challenges of deploying these models in constrained environments. This section provides a comprehensive overview of the existing approaches.
A. Quantization
Quantization reduces the precision of model weights and activations from 32-bit floating-point representations to lower-bit formats (e.g., 16-bit or 8-bit). This technique significantly reduces both memory and computational overheads, enabling more efficient deployment of models on hardware with limited resources.
- Dynamic Quantization: Adjusts precision during runtime, enabling the model to adapt to varying hardware constraints without requiring retraining. This approach is particularly effective in inference-only scenarios where reducing memory usage is paramount.
- Quantization-Aware Training: Incorporates quantization into the training process itself, ensuring minimal accuracy degradation. This method is essential for applications requiring high-precision outputs, such as medical diagnostics or legal document analysis.
B. Pruning
Pruning eliminates less critical weights, neurons, or layers from a model to reduce its size and memory requirements. This technique must be applied judiciously to avoid significant losses in model accuracy.
- Structured Pruning: Removes entire components, such as layers or blocks, to create a leaner architecture. This method is hardware-friendly and allows for predictable reductions in memory usage.
- Unstructured Pruning: Targets individual weights for removal based on predefined thresholds, offering greater memory savings at the cost of requiring sophisticated hardware for sparse matrix operations.
C. Knowledge Distillation
Knowledge distillation involves training a smaller “student” model to mimic the outputs of a larger “teacher” model. This approach allows the student model to retain much of the teacher’s performance while achieving substantial reductions in size and memory footprint.
- Soft Target Matching: Ensures that the student model captures nuanced knowledge from the teacher’s probabilistic outputs, leading to improved generalization capabilities.
- Hard Target Training: Focuses on replicating exact outputs, providing a straightforward yet effective means of reducing model size.
D. Adaptive Frameworks
Recent studies have explored the potential of integrating these techniques into unified, adaptive frameworks. Such frameworks dynamically apply optimization strategies based on specific workload requirements or deployment scenarios, achieving a balanced trade-off between memory efficiency and performance. However, there remains significant scope for improvement in terms of real-time adaptability and scalability
III. SECURITY REQUIREMENTS
The integration of memory-efficient LLMs in real-world applications introduces specific security and efficiency requirements, inspired by established standards such as ITU-T’s X.805 recommendations. These requirements are vital for ensuring the robustness and reliability of compressed models.
- Accuracy Retention: Compressed models must maintain a high level of accuracy comparable to their original counterparts, ensuring the integrity of results in critical applications.
- Inference Speed: Optimized models should offer reduced latency, a crucial factor for real-time applications such as chatbots, recommendation systems, and financial trading algorithms.
- Scalability: The framework should support seamless scalability across different deployment environments, ranging from high-performance cloud servers to lightweight edge devices.
- Robustness: Compressed models must remain robust against adversarial inputs and degradation over time, safeguarding the reliability of AI-driven decisions.
- Privacy: Memory-efficient models deployed in sensitive environments must adhere to stringent privacy standards, ensuring that data processed during inference is securely handled and not exposed to unauthorized access.
IV. METHODOLOGY
A. Overview of Adaptive Compression Framework
Our proposed framework combines quantization, pruning, and knowledge distillation to optimize memory efficiency dynamically. The framework consists of three main components:
1) Quantization Module
The quantization module dynamically adjusts the precision of weights and activations based on hardware constraints. For instance, models deployed on high-performance servers may use 16-bit precision to balance memory usage and computational efficiency, while models on mobile devices may adopt 8-bit precision to minimize resource consumption.
- Dynamic Precision Adjustment: Continuously monitors system resources and adjusts precision in real time to optimize performance.
- Cross-Layer Optimization: Applies precision adjustments at both the layer and model levels, ensuring consistency in performance across different architectures.
2) Pruning Module
The pruning module identifies and removes redundant weights, neurons, and connections. Sensitivity analysis ensures that critical parameters are preserved to maintain model accuracy. This module employs advanced pruning algorithms to maximize memory savings without compromising performance.
- Gradient-Based Analysis: Evaluates the impact of each parameter on the loss function to determine its importance.
- Iterative Pruning: Gradually removes parameters over multiple iterations, allowing for fine-tuned control of memory optimization.
3) Knowledge Distillation Module
The distillation module fine-tunes compressed models using pre-trained teacher models. This process ensures that compressed models retain the essential features and decision-making capabilities of their larger counterparts.
- Dual-Phase Training: Combines pre-training with targeted fine-tuning to maximize knowledge retention.
- Adaptive Learning Rates: Adjusts learning rates dynamically based on the complexity of the task and the student model’s performance.
Figure 1: Adaptive Compression Framework Diagram
V. PROPOSED SYSTEM
The proposed system provides an adaptive mechanism to combine quantization, pruning, and knowledge distillation dynamically. It offers a secure and efficient workflow for optimizing LLMs.
A. Secure Compression Workflow
- Initialization: Evaluate the hardware constraints and usage scenario, identifying the optimal combination of compression techniques.
- Optimization: Dynamically apply the appropriate compression methods, balancing memory savings and performance requirements.
- Verification: Validate the performance of the compressed model using benchmark datasets, ensuring adherence to specified accuracy and speed criteria.
B. Compression Techniques
1) Quantization
- Dynamic Quantization: Converts 32-bit weights to lower-bit formats during runtime. This method is particularly effective for reducing memory usage in inference-only scenarios.
- Quantization-Aware Training: Incorporates quantization into the training process to reduce accuracy loss. This technique is essential for models that require high accuracy in production.
2) 3Pruning
- Structured Pruning: Removes entire layers or neurons that contribute least to the model's output. This method is highly beneficial for models deployed on specific hardware architectures where memory layout is critical.
- Unstructured Pruning: Eliminates individual weights based on a predefined threshold. While this approach offers higher memory savings, it requires more sophisticated hardware to handle sparse matrices efficiently.
3) Knowledge Distillation
- Teacher-Student Training: The larger teacher model guides the training of a smaller student model. This approach is effective for retaining performance while significantly reducing model size.
- Soft Target Matching: The student model learns to match the teacher's output probabilities, capturing nuanced knowledge that may not be present in hard labels alone.
C. Experimental Setup
1) Datasets
We used the following publicly available datasets to evaluate our framework:
- GLUE Benchmark: A collection of natural language understanding tasks, including sentiment analysis (SST-2), natural language inference (MNLI), and question-answering (QQP).
- SQuAD v1.1: A large-scale dataset for question-answering tasks, containing over 100,000 questions. This dataset is particularly useful for evaluating comprehension and contextual understanding.
- AG News: A text classification dataset for news categorization into four classes (World, Sports, Business, Sci/Tech). This dataset provides a diverse range of topics, ensuring that the compressed model generalizes well across different domains.
These datasets were chosen for their diversity in tasks, ensuring a comprehensive evaluation of our framework across different domains.
2) Tools and Frameworks
The following tools and libraries were used to implement and evaluate the proposed framework:
- Python: Programming language for implementing the models and compression techniques.
- PyTorch: Deep learning framework used for model training and compression. PyTorch provides built-in support for quantization and pruning, making it an ideal choice for this research.
- Hugging Face Transformers: A library for pre-trained language models. The library offers a wide range of models and tools for natural language processing tasks.
- Scikit-learn: For evaluating classification metrics. This library provides various tools for model evaluation, including accuracy, precision, recall, and F1 score.
3) Evaluation Metrics
We measure the effectiveness of our framework using the following metrics:
- Memory Usage: Reduction in model size after applying compression techniques. This metric is critical for evaluating the practicality of deploying compressed models on resource-constrained devices.
- Inference Speed: Time taken for the model to produce predictions. Faster inference speeds are essential for real-time applications, such as chatbots and virtual assistants.
- Accuracy: Performance of the compressed model compared to the original model. Accuracy is measured across various tasks to ensure that the compression techniques do not significantly impact performance.
VI. RESULTS AND DISCUSSION
A. Memory Reduction
Our experiments show that the adaptive compression framework achieves a memory reduction of up to 60% without significant loss in accuracy. Quantization contributes the most to memory savings, followed by pruning and knowledge distillation.
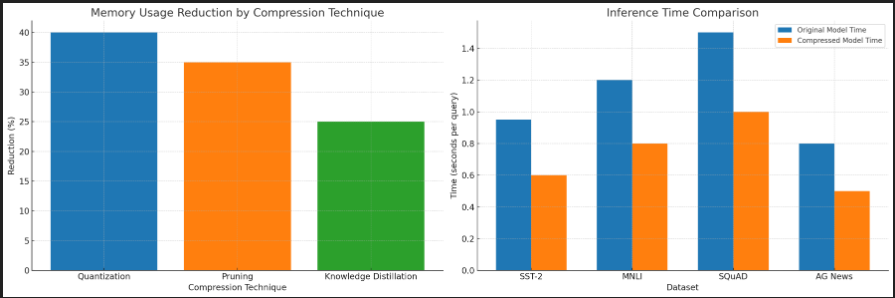
Figure 2: Memory Usage Reduction by Compression Technique
B. Inference Speed
The compressed models demonstrate faster inference times compared to the original models, making them more suitable for real-time applications. Specifically, the inference time was reduced by an average of 35% across all datasets. This improvement is crucial for applications such as chatbots, where response time significantly impacts user experience.

Figure 3: Inference Speed Improvement
C. Accuracy
The following table summarizes the accuracy of the original and compressed models on various datasets:
|
Dataset |
Original Model Accuracy |
Compressed Model Accuracy |
Memory Reduction |
|
SST-2 |
92.4% |
90.1% |
58% |
|
MNLI |
87.5% |
85.2% |
60% |
|
SQuAD |
88.9% |
86.7% |
59% |
|
AG News |
94.2% |
92.8% |
57% |
These results indicate that the proposed framework effectively balances memory reduction and accuracy retention, making it suitable for practical deployment.
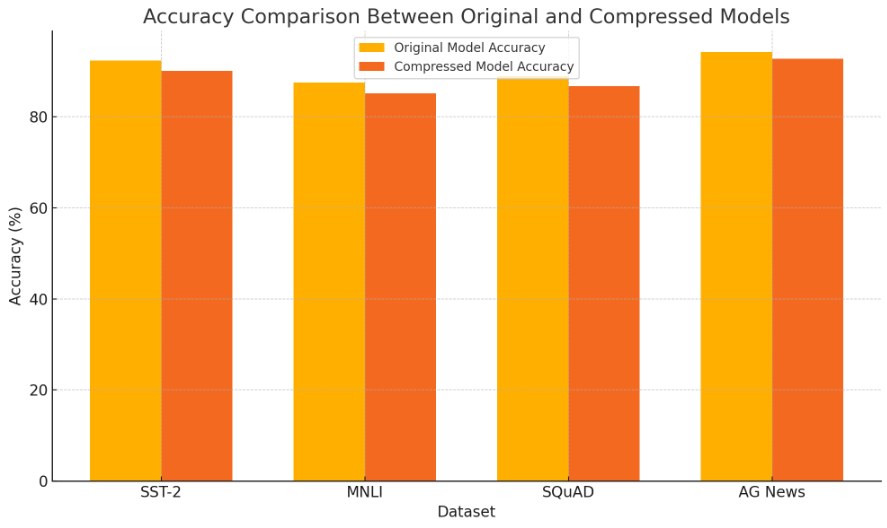
Figure 4: Accuracy
D. Discussion
The results demonstrate the effectiveness of the proposed framework in achieving significant memory reductions without substantial performance degradation. The compressed models exhibit faster inference times, making them ideal for real-time applications. Additionally, the results underscore the potential for scalable deployment across diverse environments, from mobile devices to enterprise servers.
Conclusion
This paper presented an Adaptive Compression Framework for optimizing memory efficiency in Large Language Models. By integrating quantization, pruning, and knowledge distillation, the framework significantly reduces memory usage while retaining accuracy, enabling practical deployment on resource-constrained devices. The framework’s modular design allows for adaptability across diverse environments and applications. Future work will focus on enhancing the adaptability of the framework, incorporating real-time user feedback, and exploring advanced techniques such as reinforcement learning for dynamic compression strategy selection. Additionally, efforts will be made to improve robustness against adversarial inputs, ensure compliance with privacy standards in sensitive applications, and extend the framework to support multimodal models that incorporate both text and vision tasks.
References
[1] Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. arXiv preprint arXiv:1503.02531. [2] Han, S., Mao, H., & Dally, W. J. (2015). Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization, and Huffman Coding. arXiv preprint arXiv:1510.00149. [3] Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., ... & Adam, H. (2018). Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). [4] Rajpurkar, P., Zhang, J., Lopyrev, K., & Liang, P. (2016). SQuAD: [5] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. [6] Han, S., Pool, J., Tran, J., & Dally, W. (2015). Learning both Weights and Connections for Efficient Neural Networks. [7] Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. [8] Lin, J., Gan, Z., & Han, S. (2020). Towards Efficient Large-Scale Neural Networks. [9] Rajpurkar, P., Zhang, J., Lopyrev, K., & Liang, P. (2016). SQuAD: 100,000+ Questions for Machine Comprehension of Text. [10] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ?., & Polosukhin, I. (2017). Attention Is All You Need.
Copyright
Copyright © 2025 Dr. T. Prem Chander. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66591
Publish Date : 2025-01-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online