

Ijraset Journal For Research in Applied Science and Engineering Technology
Pattern Play: Advanced API Integration for Cutting-Edge Applications
Authors: Dhruv Kumar Seth, Karan Kumar Ratra, Rangarajan Lakshminarayanachar, Swamy Athamakuri, Aneeshkumar Sundareswaran
DOI Link: https://doi.org/10.22214/ijraset.2024.63786
Certificate: View Certificate
Abstract
API integration can be regarded as the foundation of the construction of modern software systems with a high level of interaction. In this article, the author goes further into the specifics of complex and sophisticated API integration while at the same time outlining patterns, architectural models, and methods that allow developers to build new-generation solutions. It starts with the fundamentals of APIs; this will look at RESTful and GraphQL, security measures adopted, and how data is managed. The discourse continues to explain design patterns such as Facade, Adapter, proxy, observer, and strategy while explaining how they help create strong and sustainable API integration. In addition, the article presents and discusses the architectural solutions, including microservices, serverless architectures, event-driven architectures, and the API gateway pattern, stressing their roles in defining the scale and performance of systems. Webhooks, real-time data feeds, batch processing, caching techniques, idempotency, and retries are explained in detail to demonstrate the effectiveness of API integrations. It stresses the processes of API versioning, input validation, encryption, and the management of keys that help to strengthen API integrations against threats. Thus, the article concludes with a discussion on performance optimization, testing, and documentation, emphasizing their importance in making and supporting the APIs to operate properly and be used willingly. Thus, this article can be viewed as a practical developer\'s reference to the critical issues of advanced API integration, which provides the requisite understanding and materials to build highly stable, efficient, and scalable applications.
Introduction
I. INTRODUCTION
Application Programming Interface (API) management can now be considered the fundamental pillar of contemporary software development as it bridges different applications and services [1]. API integration involves linking many software suites via APIs, whereby multiple parties can communicate and share data, services, and operations. That interconnection is not a luxury but a requirement in today's integrated environment, where applications must mesh to provide end-to-end solutions.
APIs are central to constructing robust, performant, and functional applications in software development. It enables a developer to build upon already existing services, which in turn accelerates the development of processes and diminishes the overall cost of the services while at the same time increasing their functionality [2]. From social applications, which compile information from various sources to vast corporate applications linked within departments, API integration is the unseen power behind good ideas. Solutions are viewed as applications that break new ground in information technologies. These are AI analytical tools, IoT systems, fin-tech services based on blockchain, and augmented reality tours. What distinguishes these applications is their ability to come up with unique ideas and their enticing and effective employment of API connections to develop multi-level, multi-functional, and highly optimized systems [3]. This article focuses on the detailed patterns and advanced methods that drive these state-of-the-art applications. We will describe how modern architectural visions, design, and integration solutions are used to address problems in the fields of scalability, security, and performance. In this way, developers can define solid, versatile, innovative applications corresponding to the highest tech level.
II. FUNDAMENTALS OF ADVANCED API INTEGRATION
Fundamental knowledge is essential in the highly sophisticated Application Programming Interface integration area. This section analyzes the basic building blocks of complex APIs, which are the focus of today's complex and large-scale systems.
A. RESTful vs GraphQL APIs
RESTful (Representational State Transfer) APIs have been used in web service architecture for quite some time. They work based on the notion of resources and use HTTP methods to accomplish various activities. RESTful APIs are stateless and cacheable and follow the client-server model, making them easily scalable and commonly used worldwide [4]. However, due to some shortcomings, relational databases, such as GraphQL, started facing competition. GraphQL, created by Facebook for internal usage, lets the client define the query so that the server returns only the requested and no more. This flexibility eradicates the previous issues of over-fetching and under-fetching that have characterized the functionalities of REST APIs. GraphQL is based on a single endpoint and works with the query language that defines data requirements [4]. They can coexist since it all depends on the project scope that needs to be developed, the functional requirements, the quality of the data, the performance and speed, and the developers' knowledge and skills.
Table 1. A significant difference between GraphQL and REST API
|
Feature |
GraphQL |
REST |
|
Type |
Query language for APIs |
Architectural style |
|
Complex data sources |
Simple data sources |
|
|
Resource definition |
Single URL |
Multiple URLs |
|
Data structure |
Flexible |
Fixed |
|
Data typing |
Strongly typed |
Weakly typed |
|
Data validation |
Schema-based |
Client-side |
B. Authentication methods (OAuth, JWT, API Keys)
Regarding API integration, security is paramount, and different types of authentication will fit different purposes. OAuth, which stands for Open Authorization, is an open protocol that seeks to control access to applications and services. Users extend their authorization to third parties without using their credentials [5]. JSON Web Tokens (JWT) refer to passing data between parties in the claimed searchable JSON object form while being compact and self-contained [5]. API keys are essential but helpful in authorizing requests for an API. Usually, a long string in every request indicates the project or user making the request.
C. Rate-limiting and throttling
Rating and throttling are critical since they control the number of accesses that various users can make to the API while simultaneously avoiding congestion. This technique keeps any client or application from making too many requests in a given period, thus overloading the server or taking too many resources [6]. Throttling is a way of regulating the frequency of the API request. Contrary to rate limiting, which can lead to rejecting requests, throttling mainly assigns additional requests to the queue for further processing.
D. Pagination and data handling
Data management is critical in the functioning of APIs, mainly when the amounts of data to process are large. Pagination splits large data sets with some characteristics into smaller, more manageable sets or 'pages.' Page sizes are usually small enough to be manageable and large enough to be useful or relevant to the client [7]. People have come up with two main types of pagination: offset-based and cursor-based. Cursor-based pagination is usually faster for large numbers of records and is better when concurrent updates exist. Some considerations include partial response, where clients can define which fields they require; bulk operation, which allows clients to conduct various operations in one request; and data compression to minimize the files' size transmitted [7]. As a result, controlling these aspects makes it possible to develop sound, optimal, and secure APIs for integrating with applications.
While progressing deeper into more sophisticated patterns and techniques, these essentials provide the basis for more complex developments, and one can build state-of-the-art applications that work in today's environments.
III. DESIGN PATTERNS FOR API INTEGRATION
When it comes to integrating APIs, design patterns represent strongly recommended solutions for creating robust, easy-to-maintain, scalable, and efficient systems. These patterns, which solve particular issues in software architecture, have essential roles in implementing strong API integration. Next, let us look at five exciting patterns that are most noticeable in enhanced API integration scenarios.
A. Facade Pattern
The Facade pattern defines a new level of abstraction by offering a simple interface to realize a complicated subsystem [9]. This pattern is highly beneficial in API integration, mainly if you use many complex APIs or have to offer an API-familiar interface for multiple BE services. They contain the requirement of interacting with multiple APIs by providing a single, logical interface known as the Facade. This simplification improves the style and maintainability of clients' code and decreases the dependency between the client and the subsystems. For example, in a travel booking application, a Facade could be one method for booking a trip in which, internally, there might be several calls to the flight API, hotel API, and car rental API. This pattern is most useful when running data migration from legacy systems or when you have to expose a simple API to third parties with lots of complexity on the inside, as presented by the C# code below,
// Complex subsystem classes
class SubsystemA
{
public void MethodA()
{
Console.WriteLine("Subsystem A - Method A");
}
}
class SubsystemB
{
public void MethodB()
{
Console.WriteLine("Subsystem B - Method B");
}
}
class SubsystemC
{
public void MethodC()
{
Console.WriteLine("Subsystem C - Method C");
}
}
// Facade class
class Facade
{
private SubsystemA subsystemA;
private SubsystemB subsystemB;
private SubsystemC subsystemC;
public Facade()
{
subsystemA = new SubsystemA();
subsystemB = new SubsystemB();
subsystemC = new SubsystemC();
}
public void Operation()
{
Console.WriteLine("Facade - Operation");
subsystemA.MethodA();
subsystemB.MethodB();
subsystemC.MethodC();
}
}
// Client code
class Client
{
static void Main(string[] args)
{
Facade facade = new Facade();
facade.Operation();
}
}
SubsystemA, SubsystemB, and SubsystemC are the three classes that comprise the complicated subsystem in this code example. These classes stand for various subsystem functionalities or parts. The subsystem's complexity is contained within the Facade class, which serves as an oversimplified interface. The clients can communicate with the subsystem through a single interface by utilizing the operation function in the Facade class. The client code can perform the desired activities without directly interacting with the intricate subsystem classes by invoking the Operation method on the Facade object [9]. The complex details are concealed from the client through internal communication between the Facade class and each subsystem class.
B. Adapter Pattern
Adapter patterns are crucial in ensuring that incompatible interfaces coexist and work together. This pattern is fundamental in API integration cases with different interfaces or data formats. In more detail, the Adapter transforms the request made by one system into a form that is understandable to the second system. This is especially important when external systems are included in formats different from the system being worked on [10]. For example, take a look at Figure 1. If an application employs JSON for data transfer but requires interfacing with an XML-based API, an XML-to-JSON adapter can convert it without any problem. A developer can make XML-to-JSON adapters for each class of the analytics library that the code directly interacts with in order to get around the problem of incompatible formats. Next, modify the code only to connect with the library with these adapters. An adapter route calls to the relevant methods of a wrapped analytics object after translating incoming XML data into a JSON structure. In addition to facilitating integration, this pattern improves maintainability and flexibility by making it more straightforward to update or replace individual components without affecting the system as a whole.
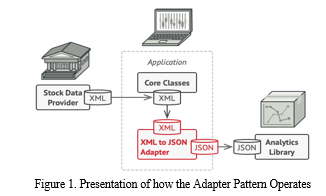
C. Proxy Pattern
In its simplest form, the proxy pattern also gives a surrogate or placeholder for other facets to manage access to it. This pattern plays a significant role in API integration in caching, logging, access controls, and lazy loading. Indeed, a proxy can forward calls to the actual API and incorporate further behaviors without changing it [12]. For example, the proxy might store the return values of an API to avoid using network bandwidth in responding to calls, use attempts if the original API request fails, or use access control measures before allowing the actual API call to occur. This pattern is particularly suitable for microservices architectures, which can be used to model API gateways that cover request filtering, authorization, rate-limiting, etc.
D. Observer Pattern
The observer pattern works so that one object depends on many others; any time this object is changed, the others are informed and updated. This pattern helps define the event-oriented approach and the real-time change in API integration. It allows systems to listen for changes or events in other systems without polling frequently [13]. For instance, the Observer pattern could be applied in a stock trading application to notify a wide range of subcomponents or external structures or inform them about stock price changes. This pattern provides loose coupling for the components. It becomes essential in cases where it is necessary to maintain data consistency with other systems or to notify users of the system status.
E. Strategy Pattern
The Strategy pattern identifies a group of algorithms, encapsulates them, and puts them in a position where there is interchangeability [14]. In API integration, this pattern is proper when one can distinguish between different integration cases or when several algorithms have to be used at the stage of data processing. By means of it, you can have two and even more variants of some definite operation and work with it in various ways simultaneously. For instance, in a payment processor application, the developers can have different approaches for every gateway where the required code for the interaction with the specific gateway API is enclosed. One evaluates that through the Strategy pattern, it is rather easy to implement new integration methods or modify the existing ones that are already in the system without causing a major disruption in the general system. This sort of flexibility is particularly beneficial for systems that interact with a number of external applications or change based on business demands.
With regard to the matter in question, reviewing these structures will be helpful in enhancing the structure of API integration in the right proportions and correct methods of usage. They prefer modularity, flexibility, and scalability, and because of these ideas, one can create strong systems, which should be expandable if necessary, further. As such, the existence of such patterns presupposes the skills of differentiating their benefits and applying them where correct implementation implies real merits. Understanding such patterns is important due to growing API compoundity, so one has to adhere to them when developing the interfaces of the next generation applications to let them seamlessly integrate with a vast amount of services and data sources.
IV. ARCHITECTURAL APPROACHES
One of the key aspects of complex API integration is identifying the architectural style because it affects the system’s extensibility, modularity and results most significantly. When it comes to further innovative applications of complex APIs, it is essential to distinguish the intricacies of various architectural paradigms and how they enable advanced integration. Hence, it is essential to identify four essential architectural strategies that underpin the current trends in software development.
A. Microservices Architecture
Microservices have transformed how complex applications are designed and deployed. This approach involves breaking an application into several loosely coupled, lightweight, self-contained services that can be independently deployed, reflecting that each is designed to handle a given business capability. Concerning API integration, microservices are more versatile and adaptable solutions. In general, each microservice would provide its capabilities in the form of one or more APIs, which can be RESTful or utilize GraphQL [8].
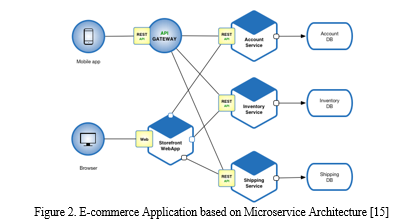
In Figure 2 above, customers place orders through the e-commerce application, which ships them after confirming inventory and credit availability. The application comprises multiple parts, such as the StoreFrontUI, which implements the user interface, and certain back-end services for shipping orders, credit checks, and inventory management. Several services are included in the application.
This level of approach to the work of service design enables precise integration of diverse chinks of an application and enables them to grow separately. In an e-commerce application, different microservices would operate with various capabilities, like user sign-in, product listing, and order management, all of which would have their unique API (refer to Figure 2). There are several advantages to using microservices in API integration, including the following: They allow teams to build, run, and ultimately grow services without relying on the rest of the system and the potential for system-wide problems. This architecture also supports polyglot persistence, in which every service can utilize the proper data storage technique. However, one of the concerns that a system designer must address appropriately is managing the distributed system's complexity and providing data integrity across different services. API gateways and service discovery become critical in microservice architectures as the number of services increases. These components assist in routing requests, load balancing, and insulating the clients from the complex nature of microservices architecture.
B. Serverless Architecture
Serverless computing, or Function as a Service (FaaS), is a new application deployment and scaling approach. As in this model, developers only have to write separate functions that perform specific tasks, and in turn, the cloud provider is responsible for basic infrastructure such as scaling and resource assignments [16].
When it comes to API integration, serverless setup holds some benefits specific to it. This means that the kind of scalability where each Function can scale depending on demand is achieved at an exceptional level. It is beneficial for APIs with irregular load patterns because it reduces load fluctuations. For instance, a content delivery API could have functions that involve resizing images. When used during high loads, they can increase without any impact on the rest of the system.
Cloud APIs implemented in serverless designs thrive when integration includes relatively brief events or calculation activities. The fact that an organization pays for the actual computing time spent allows it to cut operational overhead and costs [17] drastically. However, they also come with issues like cold start latency and restricted execution time, which must be remembered when designing APIs. The integration patterns of a function-as-a-service model in serverless structures rely on event-driven data from different sources like an API gateway, message queues, or database updates. This allows for very responsive and loadable APIs for integration that allow the management of complex workflows across devices.
C. Event-Driven Architecture (EDA)
Event architecture is a design pattern that can be described as an environment where the creation, issuing, receiving, and handling of events are the central components of the system. Regarding integration patterns for APIs, EDA proves to be a potent reference model for developing entirely loosely connected systems with the ability to scale and respond to changes and interactions in real-time.
In an event-driven system, services interact using events—signals that some critical state has been modified. It is most useful when an API integration delivers updates or synchronizes between distributed systems. Events could be stock price changes on a financial trading platform, for example, setting off a series of events that affect different integrated services.
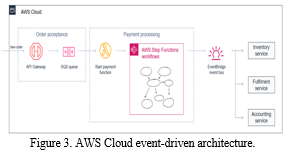
A payment processing system and an order acceptance microservice communicate through a queue in the above figure. The order acceptance service may store many incoming orders by buffering the messages in a queue. Messages from the queue can be accepted continuously by the payment processing service, which is usually slower because processing payments is complicated. The payment service uses error handling and retry logic to move between different system states. The workflow service coordinates and oversees the payment processes based on the system's status. Eventually, it generates additional events relevant to the accounting, fulfillment, and inventory services.
EDA helps to manage complex integrations since the systems that use this model can respond to events non-synchronously. This decoupling of services is good for the system and makes it more resilient and easily scalable. That is especially useful in cases with more extensive operations; request-response fashions may be better. In integration scenarios, the EDA usually uses message brokers or event streaming solutions, such as Apache Kafka. These technologies allow practicing event publishing and consumption with the necessary reliability during application distribution. The problem is in ordering and executing events, achieving exactly one processing, and dealing with the evolution of event schema.
D. API Gateway Pattern
The API Gateway pattern has emerged as a crucial part of the API architecture, particularly concerning modern-day microservices and integration. API Gateway acts as a front door to all clients, consolidating several back-end services and providing the clients with a single API. In the high-level API implementations, the identified roles of the gateway are as follows: This includes aspects such as authentication, authorization, or rate limiting and is done to free up the services from having to perform such tasks. As a result, many of these concerns are centralized, making the entire system structure less complex and more secure. API gateways also implement protocol transformation and request routing. They can translate between one or the other protocol, for example, REST to gRPC, while others can turn several back-end calls into one front-end call [18]. This capability is handy when an organization is working with old systems with APIs or managing API responses for clients with different classes. Also, API gateways can introduce caching techniques, thereby increasing efficiency and decreasing the utilization of services from servers [18]. They also help with member logging and okaying so the admin has a centralized place to monitor API usage and performance factors. When using microservices and serverless architectures, API gateway solutions frequently collaborate with service discovery solutions to operate as an entry point and determine where to send requests. They can also be used for logging and monitoring, giving developers a one-stop view of how the API is being used and how it is performing.
API gateways in microservices and serverless systems coordinate commonly with service discovery solutions to route the flows toward the back-end services. This synergy allows for a high-quality and continuously adaptable form of linking to APIs to counter the dynamics of the service environment. While working with the intricate nature of today's software systems, these approaches offer sound techniques for building reliable, extensible, and high-performance API solutions.
In this case, the focus is given to the decision-making about the application of specific strategies, with the idea that effectiveness depends upon the combination of the strategies most appropriate for the given particular requirements of the application environment.
V. ADVANCED INTEGRATIONS TECHNIQUES
A. Webhooks and Real Time Data Feeds
Since real-time applications are in high demand nowadays, traditional polling methods fail to give real-time results. This is where webhooks and real-time data streaming are the decisive factors that change how systems interact and transfer information. Webhooks, reverse APIs, or HTTP callbacks are essentially a means by which, as events happen in one system, one system informs another [19]. Instead of polling the system and asking for updates, the source system posts an HTTP POST event at a specific URL when a particular event occurs. This contrast in the call initiation strategy lessens latency and unneeded communication traffic. For example, a payment gateway can apply webhooks to notify an e-commerce platform about successful payment processing and include links to the details of the payments so that the e-commerce platform can start processing the orders immediately.
Webhooks are inherently more complex than callbacks and include provisions for topics as simple as employing a signing service to check the identity of the entity issuing a request. Webhook consumers must also be created to address delivery failures and out-of-order notifications.
Real-time data streaming extends this concept by defining continuous data exchange between the systems. WebSocket, server-sent Events, or streaming APIs based on HTTP/2 enable connections and data to be sent back and forth [20]. This is most useful in cases where information is to be updated as it occurs, like in real-time data analytical displays and shared applications. Such mechanisms include managing the connection, choosing data serialization formats such as protocol buffers and Apache Avro for efficient streaming, and dealing with backpressure when the consumer is not in a position to consume data as produced.
B. Batch Processing and Bulk Operations
Although real-time operations are helpful and necessary in some settings, batch operations and bulk tasks are valuable much more often. These techniques are vital for managing vast amounts of data efficiently, decreasing a network's overall traffic load, and enhancing a system's overall performance.
Batch processing denotes a concept where records or operations are bundled into one request [21]. Especially if there is a need to copy data frequently between systems or when analyzing a large volume of data, rather than sending separate updates for every product change, an inventory management system may, for instance, send an e-commerce platform a daily batch update of stock levels.
This is taken a notch higher by bulk operations, whereby clients can carry out many create, read, update, or delete (CRUD) operations in one API. This is especially advantageous when a relationship between two datasets or latency is an issue in a network. For instance, if there was a CRM system, it might provide a bulk API to create multiple customer records at once. Batch and bulk operations also need to take into consideration things like how large a batch is appropriate, if any item in the batch fails, should the entire operation fail or should be allowed to succeed partially, and lastly, how detailed information about failed items needs to be [22]. Furthermore, the synchronous processing models might require huge batches, where the API responds to the client with a job ID, and the client must check for the status later.
C. Caching Strategies
Cache management is a critical component of a fast-running API connection. It makes communication faster, decreases the server load, and enhances user experience. Nevertheless, caching's application in complex and distributed systems presents several important tactics and implications throughout complexity. Client-side caching deals with caching responses on the client side, minimizing the frequent requests to the network. This can be implemented by using the caching headers of HTTP, such as Cache-Control and ETag [23]. To make the content more active, there is the ability to use such tricks as conditional requests supported with If-Modified-Since or If-None-Match headers. Then, there is side caching, which places the most accessed data closer to the API server. This can be local solutions like Redis, among others, or distribution caching for big solutions. Invalidation becomes an issue here, even more apparent in microservices architectures where multiple services can put data into a cache and update it. Another such optimization layer is Content Delivery Networks (CDNs), which are primarily helpful in applications where data delivery is geo-distributed [24]. They can save API responses in the edge locations, helping minimize the latency that users experience in the various regions. Performance and freshness must be balanced while using caching techniques.
Cache warming and cache stampede prevention (using probabilistic early expiration, for example) are two strategies that can help keep the system stable during heavy loads.
D. Idempotency and Retry Mechanisms
However, conditions like network failure and timeouts are unavoidable in distributed systems. Idempotency and retrying the failure handling are critical success factors for achieving data accuracy in connection with the API. Idempotence helps ensure that executing the same request several times has the same impact as requesting once [25]. This is especially true in the case of write operations and any instances where they might have to be repeated or retried. For instance, a payment API might use the idempotency keys to prevent a transaction from being done twice if the client repeats the action due to a network failure. It usually requires creating an idempotency key for any operation and establishing the outcome of the initial successful operation. In the subsequent request, the previously computed result is returned with the same key instead of rerunning the operation. Retry mechanisms go hand in hand with idempotence in that a request that has been retried is retried if it fails to go through [26]. Retry methods want to be exponential with some level of randomness to ensure that the server is not overwhelmed when retrying occurs. It is also vital to distinguish between transient and non-recoverable errors to prevent the application from attempting to retry errors that should not be retried (for example, validation errors). In retrying, aspects like the maximum number of retries, the timeout for a function or operation, and circuit breaker patterns should also be considered to avoid issues with other related subsystems. With these techniques, developers can build strong, prosperous, and elastic APIs for integration to meet the strenuous demands of advanced distributed systems. The measure is to be aware of the specifics of a particular technique and to use any for the intended integration, admitting it to the scope of a particular integration scenario.
VI. ERROR HANDLING AND RESILIENCE
Resilience and error handling are mainly vital regarding system reliability in API integration. The circuit breaker pattern could be heralded as a significant solution for managing cascading effects in distributed systems [27]. This pattern keeps track of failures, and when a specific limit is breached, it triggers or creates a break, or, as it is sometimes referred to, ''blows the fuse'' for more calls to the failing service. This leads to some relief of the service load, and after the necessary time, the circuit can be joined to continue the work. Circuit breakers need to determine failure boundaries, the time for recovery, and the half-open state through which services can be checked for their health.
Retry policies work hand in hand with circuit breakers because they try the failed requests independently. When done, the retry approach generally applies exponential backoff with additional jitter to ensure recovery services are not overloaded [28]. These types of failures are temporary and require attempting again, and permanent failures are not worth attempting again.
Contingency measures refer to programs used in cases where the leading service is unavailable. This could mean presenting stale data, limited functionality, or pointing to mirrors and backup services. When developing fallback solutions, studying system interdependencies and tolerance to failure is necessary. Detailed logging and monitoring are starting points that can be supported when implementing the error- handling mechanism [29]. The kind of logging that aids in failure analysis is called detailed logs, whereas real-time monitoring is used to detect and possibly respond to problems as they occur. Applying distributed tracing to distributed services is most effective when there is a need to determine exactly where an error occurred in an extensive application. Continuous monitoring metrics should be defined based on business needs, and specifications should be set in areas like error rates, response time, utilization of resources for its proper functioning, and alerts for critical conditions.
VII. SECURITY CONSIDERATIONS
Security is critical in the integration of API, and several measures should be put in place to enhance the security of data/information and systems. API versioning is a crucial approach that enhances API development based on backward compatibility. Any changes in URL paths, custom headers, and content negotiation make the transition easy, allowing updates without necessarily affecting other integrations [30]. The first protective wall is pre-requisite input checking and cleansing from the attack vectors. Any data received through the API should be checked for type, format, and range. Sanitization methods should be used to eradicate any disagreeable material that may be injurious to the data, especially when data is being persisted or used in dynamic processes.
HTTPS and encryption cannot be discussed or omitted in today's world of API protection [31]. All the API traffic must be encrypted using TLS, and the supported protocols and cipher suites should be updated periodically. In addition to transport level encryption, data that is to be protected should be encrypted even when stored, and the keys for the encryption should be appropriately managed.
It is also essential to manage API keys in the long run.
Rotational API keys enhance the application's security [32]. Although the keys might get compromised, the daily rotation of API keys helps minimize their effects. Some of the best practices include the protection of parameters through distribution, storage, and revocation. One should consider using short-lived tokens or OAuth 2.0 to increase the detail level of access control strategies.
Also, rate limiting and IP allowlisting of users, as well as the use of extensive audit logs, make the system more secure. Security audits should be conducted frequently, and there should be frequent penetration testing to eliminate risks. Thus, when developing and growing API ecosystems, it is crucial to consider DevSecOps, as security is aimed at being integrated into the API development life cycle.
VIII. PERFORMANCE OPTIMIZATION
Performance optimization is equally essential in cases where APIs are integrated into systems to make them more efficient and fast [33]. One such technique is the asynchronous processing of requests, enabling non-blocking processing and increasing the effective, sustained throughput of all the system's elements. As in the case of message queues or event-driven systems, the requests can be processed much more efficiently, particularly for extended running operations.
Connection pooling is another vital optimization technique, especially concerning the database connection [34]. This way, a pool of connections can be made reusable, reducing the time needed to establish new connections for each application request and, therefore, improving the overall response time and using the system's resources. Among the critical components of effective communication operations, compression methods are essential. Enabling gzip or Brotli for API responses can significantly decrease the payload size and accelerate data transfers [35]. The efficiency of this approach is high, especially when it comes to mobile clients or in situations where network capacity is limited.
Content Delivery Networks (CDNs) are known to be one of the most effective methods of API performance enhancement, considering the usage of APIs in geo-distributed applications. Specifically, primary CDNs take API responses closer to consumers by caching, which helps reduce API latency. They also assist in distributing the load from the origin servers, thus improving the general system's scalability and capacity to handle loads.
IX. TESTING AND DOCUMENTATIONS
Ensuring practical compatibility between the APIs and the app is critical to its success; this requires rigorous testing and documentation. To perform unit testing on API integrations, each component of the API must be tested without using other integral components [36]. This also encompasses confirmation of request/response handling, errors, and other margins. Unit tests help to confirm that every feature of the API works as it should before their integration. Integration testing is a broader concept that concerns the interaction of the separate constituents that comprise the system. This implies checking API endpoints with other services, databases, and dependencies, among other elements. In integration tests, problems related to data flow, authentication, and the general functionality of the system can be found.
Documentation standards for APIs are essential for developers' ability to use and fit the API into their applications. Documentation should be clear and concise and must be updated periodically, incorporating distinct endpoint specifications, request(s) and response(s) information, and information about authentication and error handling [37]. Such tools can plug into your application and provide interactive documentation like Swagger UI or ReDoc to make developers' lives healthier. Several tools help with API testing and its documentation. Many developers use Postman for API testing, either with the help of a GUI or in a script-oriented mode with such options as environment variables and test scripts. To document APIs, tools such as Swagger (OpenAPI) often define the format for RESTful API descriptions. Static code analysis tools, for example, Javadoc for Java, Sphinx for Python, etc., can assist in providing the correlation between code and documents.
Conclusion
As is apparent in this article, the specialist sub-field of API integration is rich in theoretical angles and has many vital considerations for architecture and design. Every aspect is crucial for constructing modern applications, from microservices and serverless services to complex error handling and security services. Therefore, in the future, API integration is expected to advance with the growth of other techniques. These two areas are highly likely to apply machine learning and AI as the foundations of API management and optimization processes. The technologies of edge computing and 5G networks that are becoming more popular nowadays will define new paradigms of real-time data processing and sharing. Blockchain technology may bring changes to the secure and decentralized interactions of APIs. Based on the general study of the architectural styles analyzed in the previous sections, several questions reveal the idea of flexibility and constant learning as the primary goals that developers and architects should focus on while creating innovative applications that should be constantly evolving. The security best practices include considering a security-oriented approach, the scalability and performance features, and the documentation and testing procedures. Keeping these principles in mind and following these emerging trends, developers can design correctly performing, efficient, and innovative API integrations for future software solutions.
References
[1] Apriorit, \"What is API management and why is it important?\" Apriority?—?Specialized Software Development Company, Feb. 16, 2024. https://medium.com/that-feeling-when-it-is-compiler-fault/what-is-api-management-and-why-is-it-important-1df8ced1a2ed (accessed Jul. 08, 2024). [2] Vedraj, “Why API Development Matters for Modern Application,” ValueCoders | Unlocking the Power of Technology: Discover the Latest Insights and Trends.https://www.valuecoders.com/blog/app-development/why-api-development-crucial-modern-applications/#:~:text=APIs%20al low%20various%20sof tware%20systems (accessed Jul. 08, 2024). [3] A. Som and P. Kayal, “AI, Blockchain, and IOT,” Contributions to Finance and Accounting, pp. 141–161, 2022, doi: https://doi.org/10.1007/978-3-031-11545-5_8. [4] Amazon Web Services, “GraphQL vs REST API - Difference Between API Design Architectures - AWS,” Amazon Web Services, Inc., 2024. https://aws.amazon.com/compare/the-difference-between-graphql-and-rest/ [5] Kong, “Common API Authentication Methods: Use Cases and Benefits,” Kong Inc., Aug. 12, 2023. https://konghq.com/blog/engineering/common-api-authentication-methods (accessed Jul. 08, 2024). [6] MuleSoft, “About Throttling and Rate Limiting Policies | MuleSoft Documentation,” docs.mulesoft.com. https://docs.mulesoft.com/api-manager/1.x/throttling-rate-limit-concept#:~:text=Rate%20Limiting%20and%20Throttling%20policies%20are%20designed%20to%20limit%20API (accessed Jul. 08, 2024). [7] S. Roy, “API Pagination 101: Best Practices for Efficient Data Retrieval,” www.getknit.dev, 2023. https://www.getknit.dev/blog/api-pagination-best-practices#:~:text=Pagination%20allows%20APIs%20to%20handle (accessed Jul. 08, 2024). [8] D. Adetunji, “API Integration Patterns – The Difference between REST, RPC, GraphQL, Polling, WebSockets and WebHooks,” freeCodeCamp.org, Oct. 09, 2023. https://www.freecodecamp.org/news/api-integration-patterns/#:~:text=They%20come%20in%20different%20integration (accessed Jul. 08, 2024). [9] DevLead, “Simplify Complex Subsystems With The Facade Design Pattern in C# | HackerNoon,” hackernoon.com, 2024. https://hackernoon.com/simplify-complex-subsystems-with-the-facade-design-pattern-in-c (accessed Jul. 08, 2024). [10] S. Kumar, “Adapter Pattern - GeeksforGeeks,” GeeksforGeeks, May 03, 2016. https://www.geeksforgeeks.org/adapter-pattern/ [11] Refactoring Guru, “Adapter,” Refactoring.guru, 2014. https://refactoring.guru/design-patterns/adapter [12] S. Goyal, “5. Design Pattern:- Proxy - Nerd For Tech - Medium,” Medium, Jul. 22, 2023. https://medium.com/nerd-for-tech/5-design-pattern-proxy-ea1a40a014ec (accessed Jul. 08, 2024). [13] Bectorhimanshu, \"Implementing the Observer Design Pattern in real-world Applications with Spring\'s Event-Handling,\" Medium, Feb. 29, 2024. https://medium.com/@bectorhimanshu/implementing-the-observer-design-pattern-in-real-world-applications-with-springs-event-handling-2ba5ca668055 (accessed Jul. 08, 2024). [14] GeeksforGeeks, “Strategy Method Design Pattern | C++ Design Patterns,” GeeksforGeeks, Nov. 24, 2023. https://www.geeksforgeeks.org/strategy-method-design-pattern-c-design-patterns/ (accessed Jul. 08, 2024). [15] C. Richardson, “Microservices.io,” microservices.io, 2017. https://microservices.io/patterns/microservices.html [16] IBM, “What Is Serverless Computing? | IBM,” www.ibm.com, Oct. 13, 2021. https://www.ibm.com/topics/serverless#:~ :text=Serverless%20is%20mor e%20than%20function (accessed Jul. 08, 2024). [17] SentinelOne, “Function as a Service (FaaS) Explained, Simply | Scalyr,” SentinelOne, Jul. 16, 2021. https://www.sentinelone.com/blog/function-as-a-service-faas/ [18] Roopa Kushtagi, “The Role of API Gateway in Microservices Architecture,” Medium, Apr. 05, 2024. https://medium.com/@roopa.kushtagi/the-role-of-api-gateway-in-microservices-architecture-5eca7ab0a2e4#:~:text=It%20can%20translate%20between%20protocols (accessed Jul. 08, 2024). [19] N. Kovalchuk, “What are Webhooks and How Do They Work? - API2Cart,” API2Cart - Unified Shopping Cart Data Interface, May 08, 2024. https://api2cart.com/api-technology/what-are-webhooks/#:~:text=Fundamentally%2C%20webhooks%20are%20nothing%20but (accessed Jul. 08, 2024). [20] M. Nottingham, “Server-Sent Events, WebSockets, and HTTP,” Mark Nottingham, 2022. https://www.mnot.net/blog/2022/02/20/websockets (accessed Jul. 08, 2024). [21] AWS, “What is Batch Processing? - Enterprise Cloud Computing Beginner’s Guide - AWS,” Amazon Web Services, Inc. https://aws.amazon.com/what-is/batch-processing/ [22] Salesforce, “Salesforce Developers,” developer.salesforce.com, 2024. https://developer.salesforce.com/docs/atlas.en-us.api_asynch.meta/api_asynch/asynch_api_batches_failed_records.htm (accessed Jul. 08, 2024). [23] T. P. Singh, “Browser Caching | Practical: ETags and Cache-control,” Medium, Nov. 27, 2023. https://medium.com/@ironman8318/browser-caching-practical-etags-and-cache-control-6c7139bdcb39 (accessed Jul. 08, 2024). [24] K. Yasar, “What is a CDN? How Do Content Delivery Networks Work?,” SearchNetworking, Apr. 2023. https://www.techtarget.com/searchnetworking/definition/CDN-content-delivery-network [25] H. Khaleghi, “Idempotency in REST Architecture,” Medium, Sep. 07, 2023. https://medium.com/@hamidrezakhaleghi67/idempotency-in-rest-architecture-79568955d6d4 [26] E. Portolan, “How AWS Lambda Retry really works,” serverless.com, 2022. https://www.serverless.com/blog/how-aws-lambda-retry-really-works (accessed Jul. 08, 2024). [27] S. Coughlin, “Building Resilient Apps with Circuit Breaker Pattern,” Sean Coughlin’s Blog, Jun. 26, 2024. https://blog.seancoughlin.me/building-resilient-applications-with-circuit-breaker-pattern (accessed Jul. 08, 2024). [28] J. Montemagno, “Implement HTTP call retries with exponential backoff with Polly - .NET,” learn.microsoft.com, Oct. 06, 2023. https://learn.microsoft.com/en-us/dotnet/architecture/microservices/implement-resilient-applications/implement-http-call-retries-exponential-backoff-polly [29] Fastercapital, “Implementing Robust Error Handling And Monitoring Mechanisms,” FasterCapital. https://fastercapital.com/topics/implementing-robust-error-handling-and-monitoring-mechanisms.html (accessed Jul. 08, 2024). [30] N. Singh, “How to implement API versioning and backward compatibility,” Medium, Feb. 13, 2024. https://medium.com/@singh.neer/how-to-implement-api-versioning-and-backward-compatibility-d818f2daeb2f#:~:text=Enhancing%20Flexibility%3A%20Versioning%20allows%20for (accessed Jul. 08, 2024). [31] M. Cobb, “12 API security best practices to protect your business,” SearchAppArchitecture, Oct. 18, 2022. https://www.techtarget.com/searchapparchitecture/tip/10-API-security-guidelines-and-best-practices [32] K. Paxton-Fear, “Dizzy Keys: Why API Key Rotation Matters - Traceable API Security,” traceable.ai, Dec. 05, 2023. https://traceable.ai/blog-post/dizzy-keys-why-api-key-rotation-matters#:~:text=API%20key%20rotation%20is%20a (accessed Jul. 08, 2024). [33] Worksoft, “API Performance Testing: Optimizing Response Times and Scalability,” www.worksoft.com. https://www.worksoft.com/corporate-blog/api-performance-testing-optimizing-response-times-and-scalability#:~:text=Resource%20Optimization (accessed Jul. 08, 2024). [34] M. Aboagye, “Improve database performance with connection pooling,” Stack Overflow Blog, Oct. 14, 2020. https://stackoverflow.blog/2020/10/14/improve-database-performance-with-connection-pooling/ [35] J. Juviler, “How to Enable GZIP Compression for Faster Web Pages,” blog.hubspot.com, 2020. https://blog.hubspot.com/website/gzip-compression [36] A. Thorsen, “API Testing vs Integration Testing: What’s the Difference?,” www.leapwork.com, Nov. 23, 2022. https://www.leapwork.com/blog/api-testing-vs-integration-testing-whats-the-difference (accessed Jul. 08, 2024). [37] G. Khanna, “API Documentation, Types, Benefits and Best Practices,” APPWRK IT Solutions, Jun. 18, 2024. https://appwrk.com/api-documentation#:~:text=Neat%20and%20simple%20documentation%20makes (accessed Jul. 08, 2024).
Copyright
Copyright © 2024 Dhruv Kumar Seth, Karan Kumar Ratra, Rangarajan Lakshminarayanachar, Swamy Athamakuri, Aneeshkumar Sundareswaran. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63786
Publish Date : 2024-07-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online