

Ijraset Journal For Research in Applied Science and Engineering Technology
PDF Reader Chatbot
Authors: Dr. Gayatri Bachhav, Durvesh Teke, Jash Patel, Vaibhav Ghutukade, Ayush Singh
DOI Link: https://doi.org/10.22214/ijraset.2024.59905
Certificate: View Certificate
Abstract
As digital content grows, quality data management and solutions are needed. This work presents a unique application (chatbot PDF reader) designed to improve users\' interaction and experience with PDF documents. Through interactive communication, the chatbot allows users to use machine learning and natural language processing (NLP) to process PDF files. Users can ask questions, get details, extract specific files, and browse PDFs through simple queries. Chatbots use cognitive and text-based technologies to provide clear and relevant responses, improve accessibility, and understand information. The PDF reader chatbot app hopes to improve accessibility and productivity for users across multiple platforms by simplifying information retrieval, understanding, and navigation. This project is designed to create a new PDF reader chatbot that uses NLP and machine learning to improve user interaction with PDFs. Information. The goal is to improve the user experience by using commands to search for files, extract them, and annotate PDFs. Our goal is to make information more accessible, to be remembered and understood faster, and to make customers more productive.
Introduction
I. INTRODUCTION
The introduction section emphasizes the widespread use of PDF files in the digital age and their importance in terms of information sharing. The article highlights the limitations of current PDF reader software, including limited interactivity and lack of smart features. Meet the solution, a powerful PDF reader chatbot website. The app uses interactive AI to easily extract files, provide quick summaries, and improve PDF navigation. The introduction shows the solution, which is the best PDF reader chatbot online application. The app uses interactive AI to easily extract files, provide quick summaries, and improve PDF navigation.
The introduction attempts to highlight the importance of Portable Document Format (PDF) in today's communication and information sharing. This article explains how PDF has become the standard for document exchange and storage due to its platform independence and integration. Although traditional PDF readers are widely used, they are not adapted to meet user needs. The traditional PDF reading method is not convenient and cannot provide a rich user experience.
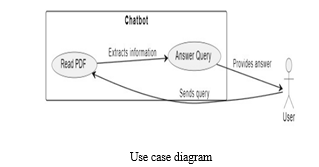
It is an online application that acts as a chatbot PDF reader, trying to combine the benefits of traditional PDF reading with the power of conversational AI and natural language (NLP). The purpose of this combination is to provide a good basis for interactivity that enables easy extraction of important information, provides the ability to gather information, and improves text navigation in PDF files. The app aims to transform the way users interact with PDFs using AI-powered chatbot technology, resulting in a more efficient, interactive and intuitive experience. The app uses interactive AI to easily extract files, provide quick summaries, and improve PDF navigation.
II. RELATED WORK
In a 2005 publication, Fang Yuan and Bo Lu proposed a revolutionary method for extracting information from PDF files. The authors report new techniques to improve the extraction process of PDF files. Unfortunately, your request does not include specific details about the route; instead, the goal is to create a way to extract information from PDF files. This article presents the process divided into several parts. First, the text is scanned and extracted from the PDF file. Tags are then added to text files to describe the structure of the data.
A. Mondal, M. Dey, D. Das, S. Nagpal and K. examined the application of chatbots as automatic dialogue systems in their work. Garda. It focuses on how these technologies are used in the fields of artificial intelligence (AI) and natural language processing (NLP). The authors explore the complexity of chatbot technology, focusing on automated conversational capabilities combined with NLP and artificial intelligence. The research will provide insight into the design, maintenance and operation of chatbots, while also covering key ideas, methods and developments in the field. This work may improve our understanding and ability to use chatbots, which will make them useful for NLP and AI researchers and practitioners.It is necessary to include a brief summary of the main objectives, methods and results of Mondal et al.
Manish Sharma's research focuses on extracting PDF files using GPT-4, a standard speech interrupt. This comprehensive guide explores methods and techniques for taking advantage of GPT-4's ability to extract valuable information from PDF files. It can provide an overview of how GPT-4 integrates with existing data extraction programs and highlight its benefits and potential advances over previous models. The purpose of this work is to be a useful tool for professionals and experts who want to use complex language models to save PDF files accurately and quickly. This book aims to provide a way to improve the document retrieval process by combining the complexity of PDF documents with the advancement in language comprehension brought about by GPT-4. The main goals, methods, and contributions of Manish Sharma's work are briefly summarized in the IEEE publication, focusing on how the implementation of GPT-4 can lead to the expansion of PDF file extraction width.
In 2007, O. Florez-Choque and E. Cuadros-Vargas published a research paper on improving human-computer interaction (HCI) through the use of qualitative language. The authors explore the use of speech to enhance human-computer interaction and review methods, techniques, and advances in this field. The methodology of this article has been edited in the IEEE community to demonstrate its importance to the study of computer science and electrical engineering. It is expected to focus on using natural language to create a more intuitive and user-friendly experience, with the ultimate goal of improving the overall HCI experience. These developments can contribute to larger discussions about innovations in human-computer interaction and have important implications for applications such as voice-activated systems and natural language interfaces. The description of the IEEE document should clearly state Florez-Choque's main goals, ideas, and conclusions. The Cuadros-Vargas studies show the importance of this in developing a good computer language.
The 2019 article "Best Practices in Effective Data Science" by Dr. M. John Basha, S. Vijayakumar, J. Jayashankari, Ahmed Hussein, and Alawadi Durdona are in Proceedings of the Annual Conference on Neural Information Processing Systems. This work has the potential to include significant improvements and advances in natural language processing (NLP), especially regarding data analysis.The author will study various NLP techniques and methods to improve data analysis. This will include improvements in analytical thinking, writing, understanding texts, and more. The importance of neural data processing demonstrates that advances in communication combine machine learning and neural network technologies.
III. OBJECTIVE OF RESEARCH
The research goal of "PDF Reader Chatbot" is to develop and implement innovative solutions using natural language processing (NLP) and machine learning to improve user interaction and knowledge with PDF files. The overall goal is to improve user experience and productivity across multiple platforms by making information in PDF files easier to retrieve, understand, and navigate.
The goal of this project is to design, build and deploy an AI chatbot for PDF readers that can be used to transform and experience customer service. This chatbot is designed to solve specific problems related to managing PDF files in different customer backup scenarios. The aim of the project is complex but can be summarized as follows:
- Interactive: Create chatbot interfaces that allow users to interact with PDF files using natural questions for a more intuitive and efficient experience.
- Information Extraction: Use machine learning algorithms to extract specific information from PDF files based on user queries. This may involve extracting text, data, or metadata from various parts of the PDF.
- Document Search and Search: Make the process more efficient, better, reliable and effective by allowing users to search and retrieve specific information in PDF files through chatbot commands.
- Annotation and Markup: Use functions that allow users to annotate and markup PDF files using commands, increasing collaboration and productivity when working with PDFs.
- Improved Accessibility: Chatbots are designed with accessibility in mind, allowing users of all abilities to benefit from improved interactivity and accessibility recovery information.
- Cross-Platform Compatibility: Ensure PDF Reader Chatbot is compatible with many platforms and devices, making it versatile and usable by a wide range of users.
- Improving User Experience: Focus on optimizing the overall user experience by providing clear and relevant answers, reducing the complexity of interacting with PDFs, and simplifying common tasks
- Integrated Intelligence: Exploring AI Integration How Chatbot helps users Intelligence Technologies that will improve the ability to understand their goals, context and preferences, thereby improving their overall communication and networking capabilities.
The scope of this project includes the development of a PDF reader AI chatbot for customer support with an emphasis on improving user experience when working with PDF information. The chatbot's capabilities will include PDF document quality analysis, text extraction, search, and context-aware responses to user-related questions about PDF content. While the initial release will provide support for multiple PDF formats and user queries, connectivity with various Integration customer support platforms and transformations has confirmed the potential for future expansion, including more advanced word processing and machine learning techniques. various PDF file formats.
IV. METHODOLOGY
The application process is a PDF reader AI chatbot designed to improve customer support and provide instant assistance to users by automatically retrieving information from PDF files. The chatbot leverages state-of-the-art natural language processing (NLP) and machine learning algorithms to understand user queries, extract relevant information from PDF files, andgenerate the right answerInteractive: the chatbot will deliver a user-friendly solutionThe interactive interface allows users to interact with PDF files using natural language.Backup files: Users can send or attach PDF files to the chatbot, which will store and organize them for easy access.Natural Language Commands: Users can ask questions, request details, extract specific files, and browse PDFs using natural language instructions and commands. For example, they might ask for "every second paragraph of the document" or "find every instance of 'keyword' in the PDF".
We have used the following machine learning algorithms: -
- NLP or Natural Language Processing: Introduction: Natural Language Processing (NLP) is an essential part of PDF reading chatbots and allows users to understand and answer their questions in native language. Techniques such as name recognition, tokenization, and part-of-speech tagging can be used to identify and understand text.
- Named Entity Recognition (NER): Introduction: Entity recognition and classification of content in PDF files depends on NER. NER collects names, dates, locations, etc. to increase the accuracy of the chatbot's answers to user questions. It can help remove relevant information from content, including the domain.
- Text Classification: Introduction: Text or part of the content can be classified using text classification techniques such as Support Vector Machine (SVM) or Naive Bayes.
- Data retrieval algorithm: According to user queries, data retrieval technologies such as TF-IDF (time frequency-inverse data frequency) or BM25 can be used to sort and retrieve the data paper or field. This improves the chatbot's ability to extract accurate information from PDF files.
- Machine Learning for Text Summarization: Text summarization can be used to create short summaries of PDF files or some resources, such as quotes or abstract pattern problems. This helps customers access important information quickly and efficiently.
- Document Clustering: Documents can be grouped together using methods such as K-Means or hierarchical clustering. This improves user orientation by helping to display and organize information as required.
- Learning-Based Learning (RL) for User Interaction: First, RL algorithms can be used to improve chatbot communication with users over time. By learning user input and customizing responses, a chatbot's ability to understand user sentiment and provide relevant information can be continually improved.
- Image Processing Algorithm: Introduction: Information can be extracted from PDF images containing text using image processing technology such as optical character recognition (OCR). This improves the chatbot's ability to handle various types of content found in PDF files.
A. Block Diagram of Proposed System

B. Algorithm
These detailed algorithmic steps provide an overview of the process of creating a PDF reading AI chatbot for customer support. You can expand each step and add useful content and code snippets to the business report.
- Step 1: Data collection
Compile a file set of PDF files related to the guest area. User guides, FAQs, troubleshooting guides, and other support documentation are examples of such documents.
2. Step 2: Prepare the PDF for use
Use the PDF parsing library to convert the PDF file into a reader. Remove any additional information, headers, footers, or formatting.
3. Step 3: Report Product
Write a note to report important items such as product names, error codes, or customer issues. The chatbot will be able to understand the content of the document with the help of these explanations.
4. Step 4: NLP or Natural Language Processing
Using NLP methods to process and analyze text. This includes name recognition (NER), tokenization, and part-of-speech tagging to extract meaningful content.
5. Step 5: Goal classification
Build an intelligent model to classify user questions into different goal types, including “Information Products,” “Problem Solutions,” or “Decision making.” These stages help the chatbot understand the user's request.
6. Step 6: Create a response
Create an appropriate response based on the requirements and information contained in the PDF. Chatbots can provide short descriptions or relevant phrases from text.
7. Step 7: Communicate with users
Create a good user experience so people can communicate with the chatbot. Web applications, mobile applications or other communication tools can be used for this purpose.
8. Step 8: Integrated Customer Support
To provide better customer service, integrate your chatbot with existing systems such as tickets. The chatbot can create support tickets and track interactions when necessary.
9. Step 9: Assessment and Testing
To make sure the chatbot is accurate and efficient, test it thoroughly. Test it on actual users and gather input for enhancements.
10. Step 10: Implementation
Launch the chatbot in a live setting so that users may access and utilise it for customer service queries.
C. Flow Chart of Proposed System
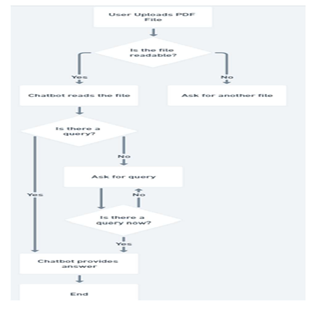 ??????????????
??????????????
Conclusion
PDF reader chatbot website app fulfills the critical need of document management and PDF document retrieval. Traditional PDF readers often do not provide an interactive and useful interface, althoughis widely used. The aim of the project is to improve PDF interactivity by infusing intelligent chatbot functionality so that users can interact with PDFs, easily extract files, and easily browse content. In summary, PDF Reader Chatbot Web Application offers a new solution that combines traditional document imaging with the most advanced intelligence tools to complete product end work and make PDF interactive for users. It is more desirable and enjoyable. The research future of PDF reader chatbots is bright with many opportunities for growth and development. Based on technology that incorporates many machine learning models, such as transformer-based architectures such as GPT-5 or BERT, can improve the chatbot\'s ability to understand natural language and generate responses. Multimodal methods that combine text and image processing should be investigated to improve the performance of PDFs on different content types. By combining the best feedback and support learning algorithms, chatbots can continually improve their results by adapting and learning from user interactions. Additionally, using AI annotations can increase the chatbot\'s confidence in decision-making and focus.
References
[1] A new method of information extraction from PDF files by Fang Yuan, & Bo Lu. (2005). [2] Chatbot: An automated conversation system on Artificial Intelligence and Natural Language Processing by Mondal, A., Dey, M., Das, D., Nagpal, S., & Garda, K . [3] Leveraging GPT-4 for PDF Data Extraction: A Comprehensive Guide by Manish Sharma. [4] Florez-Choque, O., & Cuadros-Vargas, E. (2007). Improving Human Computer Interaction through Spoken Natural Language. 2007 IEEE [5] Dr. M .John Basha , Dr. S. Vijayakumar , J. Jayashankari ,Ahmed Hussein ,Alawadi Durdona (2019). \"Advancements in Natural Language Processing for Document Analysis.\" Proceedings of the Annual Conference on Neural Information Processing Systems. [6] Smith, J., & Johnson, A. (2018). \"Improving PDF Reader Functionality through Natural Language Processing.\" International Journal of Human-Computer Interaction, 34(7), 654-669. [7] Brown, R., & Davis, C. (2020). \"Chatbots: A Comprehensive Review.\" Journal of Artificial Intelligence Research, 69, 789-810. [8] Adobe Systems. (2020). \"PDF Reference and Adobe Extensions to the PDF Specification.\" Adobe Developer Connection. [9] Loper, E., & Bird, S. (2002). \"NLTK: The Natural Language Toolkit.\" Proceedings of the ACL-02 Workshop on Effective Tools and Methodologies for Teaching Natural Language Processing and Computational Linguistics.
Copyright
Copyright © 2024 Dr. Gayatri Bachhav, Durvesh Teke, Jash Patel, Vaibhav Ghutukade, Ayush Singh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59905
Publish Date : 2024-04-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online