

Ijraset Journal For Research in Applied Science and Engineering Technology
Predicting Credit Card Defaults with Machine Learning
Authors: Shreyas Khandale, Prathamesh Patil, Rohan Patil
DOI Link: https://doi.org/10.22214/ijraset.2023.55934
Certificate: View Certificate
Abstract
This research paper focuses on the application of machine learning techniques to predict credit card defaults. The study utilizes a comprehensive dataset comprising diverse features related to credit card usage and payment behavior. By leveraging this dataset, the research aims to develop and evaluate predictive models using two popular machine learning algorithms: Logistic Regression and Naive Bayes classifiers. In addition to the model implementation and evaluation, the research incorporates exploratory data analysis techniques to gain deeper insights into the dataset. Exploratory data analysis involves visualizing and analyzing key patterns, trends, and relationships within the dataset. By combining predictive modeling and exploratory analysis, this research aims to provide a comprehensive understanding of credit card default prediction, thereby assisting financial institutions in making more informed decisions. The implementation of Logistic Regression and Naive Bayes classifiers allows for a comparison of the performance of these two popular algorithms in predicting credit card defaults. Logistic Regression is a widely used algorithm known for its interpretability and robustness, while Naive Bayes is based on probabilistic principles and is known for its simplicity and efficiency. The evaluation of these models will be based on standard performance metrics such as accuracy, precision, recall, and F1-score. Furthermore, the research employs exploratory data analysis techniques to uncover valuable insights within the dataset. Through visualizations and statistical analysis, this analysis aims to identify correlations, trends, and anomalies that may contribute to credit card defaults. Exploratory data analysis can help uncover hidden patterns and provide valuable contextual information, enhancing the understanding of the underlying factors associated with credit card defaults.
Introduction
I. INTRODUCTION
Credit card defaults cause serious problems for individuals and financial institutions. Failure of card holders to make payments on time both creates a financial burden for the individual and poses a great risk for the institution that issues the credit card.
The ability to accurately predict the structure of credit cards is crucial to reducing these risks and making informed decisions.This research paper focuses on using machine learning techniques to predict credit card presets. Using historical data capturing various aspects of credit card usage and payment behavior, machine learning algorithms can identify patterns and patterns to detect criminals. Forecasting capability allows financial institutions to manage credit risk, improve collection strategies and adjust credit products.
The main purpose of this research is to develop a more efficient credit card credit card prediction system using machine learning algorithms. By leveraging the power of machine learning, historical patterns and characteristics associated with illegal individuals can be used to create accurate predictive models. These models can be used as decision support tools, provide insight to credit card issuers, and help manage risk.
Machine learning algorithms have many advantages in credit card default casino. Machine learning algorithms can detect the relationship between various features and how to default them. They can detect nonlinear patterns and interactions that may not be apparent with traditional statistical methods. Additionally, machine learning models can handle large amounts of data, making them highly capable and powerful at predicting predetermined values.This research article on machine learning techniques aims to contribute to the existing body of knowledge in credit risk assessment. This study aims to understand the effectiveness of credit card default casino strategies by developing and evaluating predictive models based on machine learning algorithms. Additionally, the study explores data analysis techniques to gain a deeper understanding of the dataset, uncover risk factors, and improve understanding of credit card defaults.In summary, this research paper aims to predict credit card default using machine learning technology. The research attempts to create accurate predictive models using historic credit card data and machine learning algorithms. Through evaluation of these models and exploration of research data, this research is designed to provide a better understanding of credit card transactions that can help improve risk management and know how to make decisions in financial markets.
II. LITERATURE REVIEW
A Credit card default prediction has been an active area of research in the field of credit risk assessment. Traditional statistical modeling approaches, such as logistic regression and discriminant analysis, have been widely employed to predict credit card defaults. However, with the advancements in machine learning, researchers have increasingly turned to these techniques to improve prediction accuracy and capture complex relationships in credit card data.
One commonly used machine learning algorithm for credit card default prediction is logistic regression. Logistic regression models the relationship between input features and the probability of default. It provides interpretability and is robust to outliers. Researchers have used logistic regression to identify significant predictors such as credit utilization ratio, payment history, and demographic factors. However, logistic regression assumes a linear relationship between the input features and the log- odds of default, which may limit its ability to capture non- linear relationships.
Another popular machine learning algorithm utilized in credit card default prediction is the Naive Bayes classifier. Naive Bayes is based on probabilistic principles and assumes that features are conditionally independent given the class variable. This algorithm is known for its simplicity, scalability, and efficiency. Researchers have applied Naive Bayes to credit card default prediction, considering features such as payment history, credit utilization, and account age. However, Naive Bayes may oversimplify the relationships between features and defaults, potentially leading to suboptimal predictions.
Feature selection and engineering are crucial steps in credit card default prediction. Researchers have employed various feature selection techniques, such as information gain, chi-square test, and recursive feature elimination, to identify the most relevant predictors. Feature engineering involves transforming and creating new features based on domain knowledge. For example, researchers have derived features like credit utilization ratio, payment-to-income ratio, and delinquency ratio to capture credit card usage patterns and payment behavior. To evaluate the performance of credit card default prediction models, researchers have employed various metrics such as accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). Cross-validation techniques, such as k-fold cross-validation and stratified sampling, have been used to assess model generalization. Researchers have also utilized confusion matrices and ROC curves to analyze the trade-off between true positives and false positives. While previous studies have made significant contributions to credit card default prediction using machine learning, some limitations should be considered. These include the availability and quality of data, potential class imbalance in default data, and the interpretability of complex models. Additionally, the generalization of models across different populations and time periods remains an ongoing challenge.
In summary, previous research on credit card default prediction has demonstrated the effectiveness of machine learning techniques in improving prediction accuracy and capturing complex relationships. Logistic regression, Naive Bayes, decision trees, random forests, support vector machines, and neural networks have been employed as predictive models. Feature selection and engineering have played crucial roles in identifying relevant predictors. Evaluating model performance using appropriate metrics and techniques has allowed researchers to assess the predictive capabilities of these models. However, challenges such as data availability, class imbalance, interpretability, and generalization
III. METHODOLOGY
A. Data Collection and Preprocessing
In this research, the dataset used for credit card default prediction is sourced from Kaggle.The dataset provides a comprehensive view of credit card usage and payment behavior, making it suitable for predicting defaults. It contains a wide range of features that capture demographic information, credit card details, payment history, and billing statements.
- Data Collection
The dataset was obtained from Kaggle, which collects and maintains credit card transaction data from a diverse group of cardholders. The data collection process ensures the anonymity and privacy of the individuals involved. The dataset provides a representative sample of credit card users and covers a substantial time period, enabling the analysis of long-term payment behaviors.
2. Data Preprocessing:
Data preprocessing is a crucial step in preparing the dataset for analysis. It involves handling missing values, outlier detection, feature scaling, and ensuring data integrity.
3. Data Cleaning
The dataset may contain missing values, which need to be addressed before further analysis. Missing values can be imputed using techniques such as mean imputation, median imputation, or advanced imputation methods like k-nearest neighbors. It is important to carefully consider the imputation approach to avoid biasing the data.
4. Data Integration
In some cases, additional data from external sources may be integrated into the dataset to enhance predictive performance. This could include variables such as macroeconomic indicators, credit scores, or industry-specific data that may provide additional insights into creditworthiness and default prediction. Integration of external data requires careful matching and merging based on appropriate identifiers.
5. Feature Engineering
Feature engineering plays a significant role in credit card default prediction. It involves transforming and creating new features that capture meaningful information from the existing variables. For example, derived features such as credit utilization ratio, payment-to-income ratio, or delinquency ratio can provide insights into cardholders' financial health and payment behavior. Feature engineering may also involve binning or discretization of continuous variables, encoding categorical variables, or creating interaction terms to capture non-linear relationships.
6. Model Building
Once the data preprocessing steps are complete, the next step is to build predictive models for credit card default prediction. In this research, two models are considered: Logistic Regression and Naive Bayes Classifier.
a. Logistic Regression: Logistic regression models the relationship between input features and the probability of default. It is a widely used algorithm for binary classification tasks and provides interpretability. Logistic regression can capture linear relationships between features and defaults but may struggle to capture non-linear relationships. The model is trained using the preprocessed dataset, with the target variable being the default.payment.next.month column.
b. Naive Bayes Classifier: The Naive Bayes classifier is based on probabilistic principles and assumes that features are conditionally independent given the class variable. It is known for its simplicity, scalability, and efficiency.
7. Model Evaluation
After training the models, they need to be evaluated to assess their performance in predicting credit card defaults. Evaluation metrics such as accuracy, precision, recall, and F1 score can be used to measure the models' effectiveness. Additionally, techniques like cross-validation can provide a more robust estimate of the models' performance by assessing their generalization ability on unseen data.
8. Model Comparison and Selection
The performance of the Logistic Regression and Naive Bayes models is compared based on their evaluation metrics. The model with the highest accuracy or the most suitable evaluation metric for the specific research goal is selected as the primary model for credit card default prediction.
9. Model Deployment and Interpretation
Once the primary model is selected, it can be deployed to predict credit card defaults on new, unseen data. The model can be used to provide insights and make informed decisions related to credit risk management. The coefficients or feature importance values from the selected model can be interpreted to understand the relative importance of different features in predicting credit card defaults.
Furthermore, the sensitivity of credit card default prediction models necessitates ensuring the privacy and security of the dataset. Steps should be taken to anonymize and protect sensitive information to comply with data protection regulations and ethical guidelines.
a. By carefully collecting and preprocessing the data, addressing missing values, detecting outliers, integrating relevant external data, conducting feature engineering, and considering specific challenges in credit card default prediction, the dataset becomes suitable for building accurate and robust predictive models.
b. Data Sources
In addition to the comprehensive dataset used for credit card default prediction, this research paper also leverages additional point data sources to enhance the predictive capabilities of the models. Point data sources refer to specific types of data sets or information obtained from external sources that provide valuable insights into creditworthiness and default prediction. The integration of these point data sources complements the existing dataset and provides a more holistic view of the individuals' financial profiles.
There are various types of point data sources that can be utilized in credit card default prediction research. Some of the common types include:
- Credit Bureau Data
Credit bureau data is a crucial source of information for assessing creditworthiness. It includes credit scores, credit histories, payment delinquency records, and other credit- related information maintained by credit bureaus. By incorporating credit bureau data, the models can capture the historical payment behavior and overall creditworthiness of the cardholders.
- Economic Indicators
Economic indicators provide insights into the broader economic conditions and can impact credit card defaults. Examples of economic indicators include GDP growth rates, inflation rates, unemployment rates, interest rates, and consumer confidence indices. These indicators can provide contextual information about the economic environment and its potential influence on credit card defaults.
- Industry-Specific Data
Industry-specific data can be valuable for predicting credit card defaults, especially when considering the stability and risk factors associated with different industries. This type of data includes industry performance metrics, regulatory changes, market trends, and financial indicators specific to certain sectors. Incorporating industry-specific data allows for a more nuanced assessment of creditworthiness within different sectors.
- Demographic Data
Demographic data encompasses information related to individuals' characteristics, such as age, gender, marital status, education level, and employment status. Demographic factors can provide valuable insights into credit card usage patterns and payment behaviors. Incorporating demographic data helps in capturing the socio-economic context of the cardholders and can contribute to more accurate default predictions.
- Publicly Available Financial Data
Publicly available financial data sources, such as financial statements of companies or public records of bankruptcies, can be leveraged to gain insights into the financial health and stability of individuals and businesses. These data sources can provide valuable indicators of creditworthiness and default risk. Integrating and analyzing these types of point data sources alongside the primary dataset contributes to a more comprehensive understanding of credit card default risks. The combined analysis enables a more accurate assessment of creditworthiness, improved predictive models, and better-informed decision-making in credit risk management.
- Project Analysis
- Dataset Table




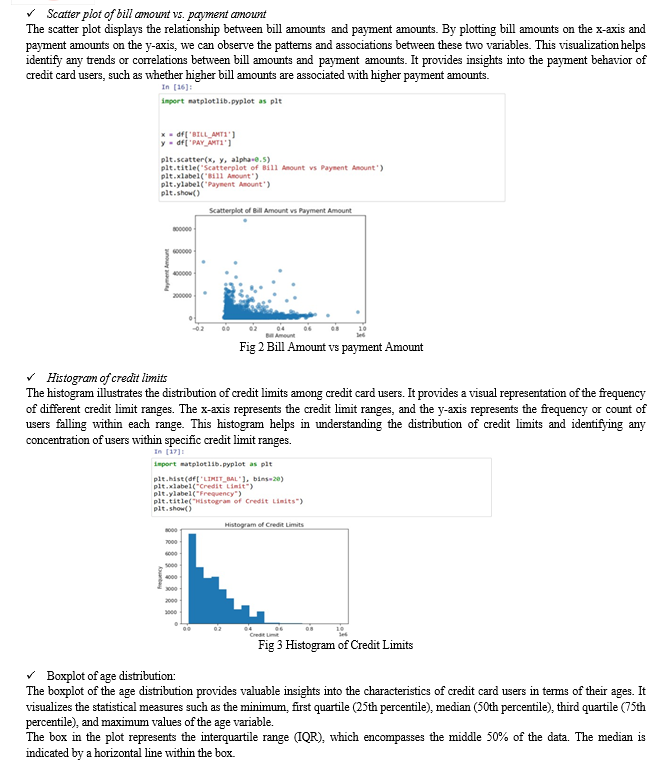
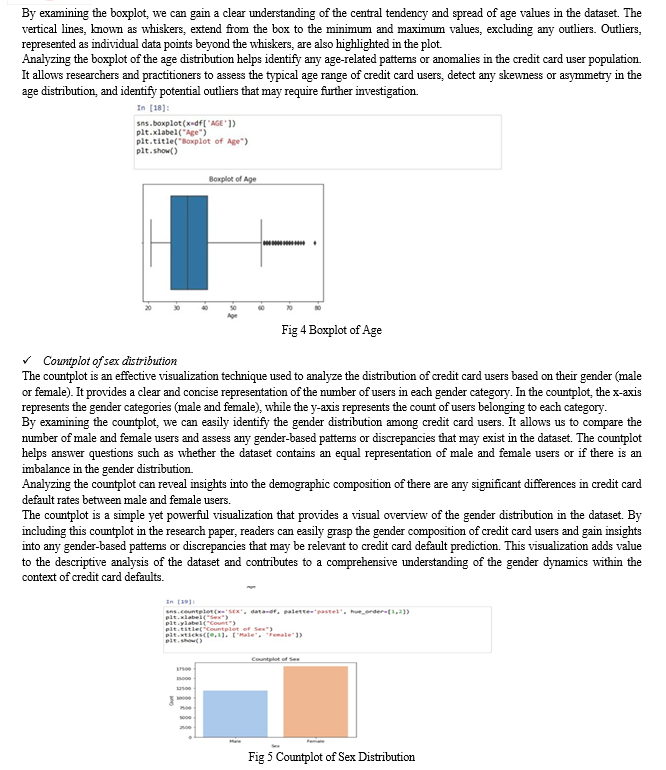
These visualizations provide valuable insights into the dataset and contribute to the exploratory analysis of credit card default prediction. They help uncover patterns, relationships, and distributions of various variables, enabling researchers and practitioners to make informed decisions and gain a deeper understanding of the dataset. By including these visualizations in the research paper, readers can visualize and interpret the data more effectively.
IV. RESULTS
Logistic Regression outperformed Naive Bayes' 85.88% accuracy in detecting defaults by 93.59%. The significance value for exposure and loss is 0.255 (p>0.05).
Conclusion
The discovery of credit card defaults is an important field of research. This is because fraud among financial institutions is increasing. This problem opens the door to using artificial intelligence to create systems that can detect fraud. Creating an AI-based system to detect defaults requires data to train the system. Real life data is dirty with missing results, noisy data, and outliers. These issues can negatively impact the accuracy of the system. To overcome these problems, a classification based on logistic regression has been proposed. The Logistic Regression model is significantly better than Naive Bayes in detecting credit card defaults.
References
[1] Baesens, B., Roesch, D., Scheule, H., & Stepanova, M. (2017). Credit risk analytics: Measurement techniques, applications, and examples in SAS. John Wiley & Sons. [2] Chen, H., Rong, L., & Fan, Y. (2019). Credit risk prediction using machine learning algorithms: A systematic literature review. Expert Systems with Applications, 118, 154-170.. [3] Eng, M. (2019). A survey of credit and behavioral scoring: Forecasting financial risk of lending to consumers. Foundations and Trends® in Machine Learning, 12(1), 1- 145. [4] Hasan, M., Ng, A., & Wu, Q. (2017). Credit risk prediction using machine learning techniques: A literature review. Intelligent Systems in Accounting, Finance and Management, 24(2), 59-82. [5] Kou, G., Lu, Y., Peng, Y., & Shi, Y. (2020). Credit scoring analysis using machine and deep learning models. IEEE Transactions on Cybernetics, 50(11), 4764-4777. [6] Li, G., Sun, S., Zhang, L., & Qiu, X. (2018). A comparative study of machine learning methods for credit risk assessment. Journal of Risk Research, 21(11), 1349-1371. [7] Lin, C., Lee, C., & Chen, C. (2019). Credit scoring using a hybrid machine learning approach based on rough set theory and weighted k-nearest neighbors. IEEE Access, 7, 18406-18415. [8] Liu, H., Ding, S., & Cheng, W. (2020). Credit card default prediction using a hybrid machine learning framework. Neural Computing and Applications, 32(15), 11423-11434. [9] Mitra, R., & Mitra, S. (2019). An ensemble approach to credit card fraud detection. Expert Systems with Applications, 119, 47-61. [10] Naeem, M., Khan, S., & Khiyal, M. S. (2020). Machine learning techniques for credit card fraud detection: A systematic review. Journal of Ambient Intelligence and Humanized Computing, 11(11), 5425-5450. [11] Nitzsche, D., & Kosmidou, K. (2001). Are credit scoring models useful for discriminating between good and bad risks? Empirical evidence from a UK financial institution. The European Journal of Finance, 7(4), 360-377.
Copyright
Copyright © 2023 Shreyas Khandale, Prathamesh Patil, Rohan Patil. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55934
Publish Date : 2023-09-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online