

Ijraset Journal For Research in Applied Science and Engineering Technology
Predictive Modeling for Cardiovascular Disease Risk Assessment
Authors: Dr. P. Muthuvel, Alumula Srujan
DOI Link: https://doi.org/10.22214/ijraset.2024.58799
Certificate: View Certificate
Abstract
Heart disease remains one of the leading causes of mortality worldwide. Early detection and risk assessment are crucial for effective prevention and management. This research paper presents a novel approach utilizing machine learning techniques, particularly decision trees, for predicting heart disease risk. The study utilizes a dataset sourced from the UCI Machine Learning Repository, encompassing diverse features such as age, gender, height, weight, cholesterol levels, and other relevant attributes. The proposed model aims to accurately classify individuals into risk categories based on their demographic and health-related information. Additionally, a user-friendly web application is developed using Python Flask, enabling users to input their data and receive instant risk assessments. Through rigorous experimentation and evaluation, the efficacy and reliability of the predictive model are demonstrated, offering valuable insights for early intervention and personalized healthcare strategies in the fight against heart disease.
Introduction
I. INTRODUCTION
Heart disease remains a significant public health concern globally, contributing to a substantial portion of morbidity and mortality rates. Despite advancements in medical technology and treatment modalities, the prevalence of heart-related ailments continues to pose challenges to healthcare systems worldwide. Timely detection and effective risk assessment are imperative for implementing preventive measures and optimizing patient outcomes. In recent years, machine learning (ML) techniques have emerged as powerful tools for predictive modeling in various healthcare domains, including cardiovascular disease risk assessment.
This research endeavors to leverage the capabilities of ML, specifically decision tree algorithms, to develop a robust predictive model for assessing heart disease risk. The study utilizes a comprehensive dataset sourced from the UCI Machine Learning Repository, encompassing a diverse array of demographic and clinical variables such as age, gender, height, weight, cholesterol levels, and other pertinent attributes. By analyzing this rich dataset, our aim is to train a predictive model capable of accurately stratifying individuals into different risk categories based on their unique profiles.Furthermore, recognizing the importance of accessibility and user-friendliness in healthcare applications, we have developed a web-based interface using Python Flask. This web application enables users to input their demographic and health-related data conveniently, and in return, receive instant risk assessments regarding their likelihood of developing heart disease. By integrating cutting-edge ML techniques with user-friendly software, our approach aims to democratize access to personalized risk assessment tools, empowering individuals to take proactive steps towards cardiovascular health. Through this research endeavor, we seek to contribute to the growing body of knowledge in predictive healthcare analytics while simultaneously addressing a critical need for early detection and intervention in the prevention of heart disease. By harnessing the potential of ML and web-based technologies, we aspire to pave the way for more effective and personalized healthcare strategies, ultimately striving towards improved outcomes and better quality of life for individuals at risk of cardiovascular ailments.
II. LITERATURE SURVEY
Heart disease prediction and risk assessment represent critical areas of study within healthcare analytics, driven by the imperative to reduce the burden of cardiovascular diseases worldwide. Extensive research in this domain has explored a diverse range of methodologies, from classical statistical techniques to cutting-edge machine learning algorithms, with the aim of developing accurate and clinically applicable predictive models. The seminal Framingham Heart Study, initiated in 1948, stands as a cornerstone in cardiovascular epidemiology, delineating key risk factors associated with heart disease. Through longitudinal observation of a cohort from Framingham, Massachusetts, researchers identified several predictors, including age, gender, blood pressure, serum cholesterol levels, smoking status, and diabetes mellitus, which have since been widely recognized and incorporated into risk prediction models.
Traditional statistical approaches have traditionally played a significant role in heart disease prediction, offering transparency and interpretability. Logistic regression, for instance, has been extensively utilized to model the probability of cardiovascular events based on a combination of risk factors. Additionally, Cox proportional hazards models have been instrumental in assessing the impact of covariates on the time-to-event outcomes, providing valuable insights into disease progression and mortality risk.
However, the inherent limitations of traditional statistical methods, such as linearity and model assumptions, have spurred interest in more flexible and data-driven approaches. Machine learning algorithms, characterized by their ability to capture complex patterns in high-dimensional data, have emerged as promising alternatives for heart disease prediction. Decision tree-based algorithms, including Random Forest and Gradient Boosting Machines, have gained popularity for their ability to handle nonlinear relationships and interactions among predictors. These methods partition the feature space into a hierarchy of decision rules, allowing for the identification of complex patterns that may elude traditional statistical models. Furthermore, ensemble learning techniques, which combine multiple base learners to improve predictive accuracy and generalizability, have demonstrated superior performance in heart disease prediction tasks. The availability of large-scale datasets, such as those from the UCI Machine Learning Repository and national health surveys like NHANES, has provided researchers with unprecedented access to diverse patient populations and rich clinical data. These datasets have been instrumental in training and validating predictive models, facilitating the development of robust risk assessment tools applicable across different demographic and clinical contexts. In addition to model development, considerable attention has been devoted to evaluating the clinical utility and real-world applicability of predictive algorithms. Studies have assessed the performance of risk prediction models in diverse patient populations and healthcare settings, emphasizing the importance of external validation and model transparency in clinical decision-making.
Overall, the literature on heart disease prediction underscores the need for interdisciplinary collaboration between epidemiologists, statisticians, and machine learning experts to develop accurate and clinically relevant predictive models. By leveraging advanced modeling techniques and comprehensive datasets, researchers can continue to advance the field of cardiovascular risk assessment, ultimately contributing to improved patient outcomes and population health.
III. PROPOSED METHOD
To embark on heart disease prediction using a decision tree algorithm, the journey begins with assembling a dataset encompassing a diverse array of health parameters alongside corresponding labels denoting the presence or absence of heart disease. This dataset undergoes meticulous preparation, where imperfections such as missing values and outliers are meticulously addressed, ensuring data integrity. Features deemed essential in influencing heart disease diagnosis are carefully selected for further analysis.
Following data preparation, the dataset is partitioned into distinct training and testing subsets, laying the groundwork for model development and evaluation. With the training data in hand, the decision tree algorithm is deployed, orchestrating a systematic process of data partitioning based on key features. This iterative process unfolds, progressively refining the model's ability to discern patterns indicative of heart disease presence. As the decision tree model matures through training, it becomes adept at navigating the intricate web of health parameters to make informed predictions. The model's proficiency is then put to the test using the reserved testing set, where its predictive prowess is rigorously assessed against ground truth labels.
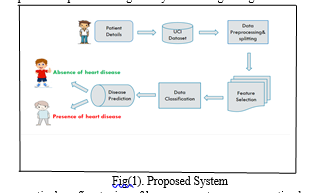
Throughout this iterative journey, meticulous fine-tuning of hyperparameters ensures optimal model performance, culminating in a robust decision tree model primed for real-world deployment. Armed with this predictive tool, healthcare professionals gain valuable insights into early heart disease diagnosis, empowering them to initiate timely interventions and mitigate potential risks, ultimately enhancing patient outcomes and well-being.
IV. METHODOLOGY
A. Dataset Description
The dataset comprises several key health parameters, each potentially indicative of heart disease presence or absence.
- Age: The age of the individual, which is a crucial factor in assessing cardiovascular risk.
- Gender: The gender of the individual, which may contribute to variations in heart disease prevalence and manifestation.
- Chest Pain Type (CP): Different types of chest pain, which could be indicative of varying levels of cardiac distress.
- Blood Pressure (trestbps): The resting blood pressure of the individual, measured in mm/Hg.
- Cholesterol (chol): The cholesterol level in mg/dl, another important marker of cardiovascular health.
- Fasting Blood Sugar (fbs): Indicates fasting blood sugar levels, with a value of 1 indicating >120mg/dl and 0 indicating otherwise.
- Resting Electrocardiographic Results (restecg): Provides insights into the individual's cardiac electrical activity at rest.
- Max Heart Rate Achieved (thalach): The maximum heart rate achieved during exertion, a measure of cardiovascular fitness.
- Exercise-Induced Angina (exang): Presence of exercise-induced angina, which may signal underlying coronary artery disease.
- ST Depression Induced by Exercise (oldpeak): Measures ST depression induced by exercise relative to rest, indicating cardiac stress response.
- Slope of the Peak Exercise (slope): Describes the slope of the peak exercise ST segment, offering further insights into cardiac function.
- Number of Major Vessels (CA): Indicates the number of major vessels (0 to 3) showing significant narrowing by fluoroscopy.
- Thal Value: A categorical feature representing a blood disorder, with values 0=NULL, 1=Fixed Defect (no blood flow), 2=Normal Blood Flow, and 3=Reversible Defect.
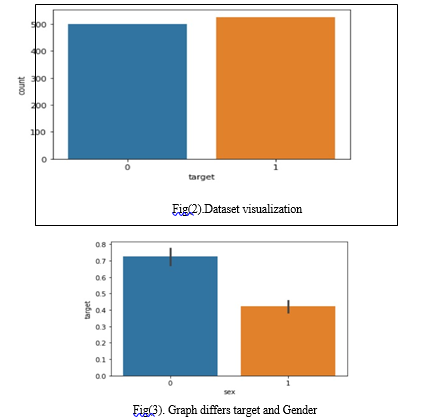
Examine the figure 2 below The dataset displays the number of users who have heart disease and those who do not; heart illness is not the dataset's purpose. Heart disease is represented by the numbers 0 and 1, respectively. Figure 3 illustrates the target gender difference in the number of male and female disease-carriers.
B. Decision Tree Methodology
Decision trees are a popular machine learning algorithm used for classification and regression tasks. They represent a tree-like structure where each internal node represents a "test" on an attribute, each branch represents the outcome of the test, and each leaf node represents a class label.The decision tree algorithm begins with the entire dataset at the root node. It iteratively selects the best feature to split the data based on criteria such as Gini impurity or information gain. This process continues recursively until a stopping criterion is met, such as reaching a maximum tree depth or minimum number of samples per leaf node.One of the key advantages of decision trees is their interpretability. The resulting tree can be visualized, allowing healthcare professionals to understand the decision-making process and identify the most influential features in predicting heart disease.
C. Applications in Heart Disease Prediction
In the context of heart disease prediction, decision trees offer a transparent and interpretable framework for assessing risk factors and making predictions. By analyzing the decision path from the root node to the leaf nodes, healthcare professionals can gain insights into the factors contributing to heart disease and tailor interventions accordingly.By leveraging decision trees with the provided dataset, healthcare professionals can develop effective models for heart disease prediction, integrating clinical expertise with data-driven insights to improve patient outcomes and quality of care.
V. EXPERIMENTAL RESULT
In our study, we explored the performance of various machine learning algorithms including logistic regression, naive Bayes, support vector machine (SVM), k-nearest neighbors (KNN), decision tree, and random forest. Fig(4) shows all algorithms accuracy. After rigorous training and evaluation, it was observed that both the random forest and decision tree algorithms achieved the highest accuracy among all tested methods.

Conclusion
After analyzing multiple machine learning algorithms, we found that both the random forest and decision tree algorithms consistently achieved the highest accuracy. Among them, the decision tree algorithm emerged as the top performer, offering superior predictive capability and interpretability. As a result, we selected the decision tree algorithm for predicting input data in our experiment. This project underscores the effectiveness of decision tree algorithms in predictive modeling tasks, highlighting their potential for practical implementation in real-world scenarios.
References
[1] Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer. [2] Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5-32 [3] Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1(1), 81-106. [4] Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer. [5] Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., ... & Vanderplas, J. (2011). Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research, 12(Oct), 2825-2830. [6] Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189-1232. [7] Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 13(1), 21-27 [8] Duda, R. O., Hart, P. E., & Stork, D. G. (2012). Pattern Classification (2nd ed.). Wiley [9] Cortes, C., & Vapnik, V. (1995). Support-vector networks. Machine Learning, 20(3), 273-297. [10] Mitchell, T. M. (1997). Machine Learning. McGraw Hill.
Copyright
Copyright © 2024 Dr. P. Muthuvel, Alumula Srujan. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58799
Publish Date : 2024-03-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online