

Ijraset Journal For Research in Applied Science and Engineering Technology
Privacy Challenges and Solutions in Big Data Analytics: A Comprehensive Review
Authors: Mr. R. Ramakrishnan, R. Sujithra, A. Joice Niranjalin
DOI Link: https://doi.org/10.22214/ijraset.2024.62103
Certificate: View Certificate
Abstract
Large data collections with a more intricate and diversified structure are referred to as \"big data.\" These traits are typically associated with more challenges when it comes to storing, analyzing, and applying additional procedures or getting results. The technique of analyzing vast quantities of intricate data to uncover patterns or connections that are concealed is known as \"big data analytics.\" Nonetheless, there is a clear conflict between big data\'s extensive use and its security and privacy. This paper examines privacy needs in big data, distinguishes between privacy and security, and focuses on privacy and security issues in large data. This study addresses the applications of privacy in business by utilizing established techniques like HybrEx, k-anonymity, T-closeness, and L-diversity. Many privacy-preserving techniques have been created for protection of privacy at various phases of the big data life cycle (such as data generation, storage, and processing). This work aims to explain the issues facing current privacy preservation strategies in big data and to give a comprehensive evaluation of them. This study also introduces new approaches to privacy preservation in big data, such as quick anonymization of massive data streams, identity-based anonymization, differential privacy, privacy preserving big data publishing, and hiding a needle in a haystack. This study discusses big data privacy and security issues in healthcare. A comparative analysis of some contemporary large data privacy approaches is also conducted. A comparative analysis of the latest big data privacy approaches is also conducted.
Introduction
I. INTRODUCTION
The emergence of Internet applications, social networks, and the Internet of Things has led to a substantial increase in data generation, commonly referred to as big data. Big data is characterized by its 5V properties: Volume, Velocity, Variety, Value, and Veracity, stemming from its generation from diverse sources, in various formats, and at high speeds. However, these characteristics also introduce new challenges throughout the lifecycle of big data, particularly concerning privacy and five key security aspects: confidentiality, efficiency, authenticity, availability, and integrity. Confidentiality stands as the cornerstone of big data security and privacy, necessitating protection against data leaks. Any breach in data security results in the loss of its value. Big data's value diminishes significantly if hackers tamper with or access confidential information. Efficiency plays a pivotal role in big data security and privacy due to the demand for high network bandwidth. Authenticity ensures the reliability of data sources, processors, and authorized data recipients, safeguarding against inaccurate analysis and maximizing the potential value of big data. The availability of big data is paramount, as its value diminishes if inaccessible when needed. Furthermore, integrity is vital for obtaining accurate and valuable data. Inaccurate or incomplete data compromises the integrity of analyses, especially when the missing data is sensitive and crucial. Today, big data finds extensive utilization across various sectors such as healthcare, government agencies, businesses, research, and other organizations for analysis purposes. However, utilizing this data often involves its publication, investigation, and other applications, raising concerns about privacy. Since big data contains individuals' specific information, directly releasing it for analysis poses significant risks to user privacy. Therefore, techniques for privacy-preserving big data mining are indispensable, aiming to mitigate identity and sensitive information disclosure within datasets.
II. LITERATURE REVIEW
Aggarwal, C. C. (2014). In this paper, Aggarwal provides a comprehensive exploration of big data privacy issues from a technological perspective. He examines various challenges and solutions related to preserving privacy in the era of big data analytics. Kitchin, R. (2014). Kitchin's work focuses on the broader implications of big data, including its epistemological and paradigmatic shifts.
He offers insights into how big data affects various aspects of society and knowledge production. Boyd, D., & Crawford, K. (2012). Boyd and Crawford present critical questions and provocations regarding big data, emphasizing its cultural, technological, and scholarly impacts. They raise important considerations for researchers and practitioners navigating the big data landscape. Mayer-Schönberger, V., & Cukier, K. (2013). The authors discuss the transformative potential of big data in their book, highlighting its implications for various domains such as healthcare, business, and governance. They explore the opportunities and challenges associated with harnessing big data. Lazer, D., Kennedy, R., King, G., & Vespignani, A. (2014). This article discusses the pitfalls of big data analysis using the example of Google Flu Trends. It underscores the importance of critical scrutiny and validation in interpreting big data insights. Floridi, L. (2012). Floridi contributes to the discourse on big data by addressing its epistemological challenges. He reflects on the nature of knowledge production in the context of vast amounts of data and the implications for understanding the world. Dhar, V. (2013). Dhar's work delves into the domain of data science and prediction, offering insights into the methodologies and techniques used in analyzing big data. He discusses the role of predictive analytics in extracting value from large datasets. Chen, M., Mao, S., & Liu, Y. (2014). This survey paper provides an overview of big data technologies and applications. It covers various aspects such as data processing, analytics, and challenges in managing and deriving insights from big data. Zikopoulos, P., Eaton, C., DeRoos, D., Deutsch, T., & Lapis, G. (2012). The authors present a comprehensive guide to understanding big data technologies, with a focus on Hadoop and streaming data analytics. They offer practical insights for organizations leveraging big data platforms. Raghupathi, W., & Raghupathi, V. (2014). This paper explores the promise and potential of big data analytics in healthcare. The authors discuss applications such as predictive modeling, personalized medicine, and healthcare management using large healthcare datasets.
III. NAVIGATING THE PRIVACY AND SECURITY LANDSCAPE OF BIG DATA
Privacy and security concerns in big data arise due to the sheer volume, variety, and velocity of data being generated, collected, processed, and stored. Some key concerns include:
- Data Breaches: Large volumes of sensitive data increase the risk of unauthorized access, leading to data breaches and potential exposure of personal or confidential information.
- Unauthorized Access: The complexity of big data systems can make them vulnerable to unauthorized access, whether from external hackers or insider threats.
- Data Integrity: Maintaining the accuracy, consistency, and reliability of data is crucial in big data systems. Any compromise to data integrity can lead to incorrect analysis, decision-making, or outcomes.
- Privacy Violations: Big data analytics often involve the collection and analysis of personal information. Improper handling of this data can result in privacy violations, such as unauthorized surveillance, profiling, or discrimination.
- Lack of Transparency: The opacity of big data algorithms and analytics processes can raise concerns about accountability, fairness, and bias, especially when decisions impact individuals or groups.
- Compliance and Legal Risks: Big data systems must comply with various regulations and legal requirements governing data privacy, security, and usage. Non-compliance can lead to financial penalties, reputational damage, or legal action.
- Data Sovereignty: Big data often involves the storage and processing of data across multiple jurisdictions. This raises concerns about data sovereignty, data localization requirements, and conflicts between national regulations.
- Inadequate Data Governance: Poor data governance practices, such as insufficient data quality controls, lack of data access controls, or inadequate data lifecycle management, can exacerbate privacy and security risks.
- Insider Threats: Trusted insiders with access to sensitive data can pose significant security risks, whether through intentional misuse, negligence, or inadvertent errors.
- Emerging Threats: Rapid advancements in technology, such as IoT devices, AI-driven analytics, and cloud computing, introduce new security challenges and vulnerabilities that must be addressed in big data environments.
Overall, addressing privacy and security concerns in big data requires a holistic approach, combining technical solutions, robust governance frameworks, and adherence to regulatory requirements to ensure the responsible and ethical use of data.
IV. ENSURING PRIVACY COMPLIANCE
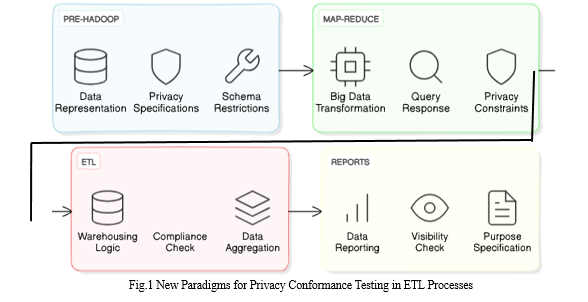
Innovative approaches for ensuring privacy compliance extend to all phases of the ETL (Extract, Transform, and Load) process:
- Pre-Hadoop Process Validation: This initial step involves data loading representation. Here, privacy specifications define sensitive data elements capable of uniquely identifying users or entities. Additionally, privacy terms outline data storage permissions and duration, with potential schema restrictions.
- Map-Reduce Process Validation: This phase transforms big data assets to respond efficiently to queries. Privacy terms specify the minimum number of returned records needed to obscure individual values and impose restrictions on data sharing among processes.
- ETL Process Validation: Similar to the Map-Reduce step, this stage confirms warehousing adherence to privacy terms. Certain data values may undergo anonymous aggregation or exclusion from the warehouse to mitigate the risk of identifying individuals.
- Reports Testing: Reports serve as inquiries with broader visibility and audience reach. Here, privacy terms defining the 'purpose' are critical to ensure that sensitive data is only reported for specified uses, minimizing unauthorized disclosures.
V. DE-IDENTIFICATION
De-identification has long been employed as a method for preserving privacy in data mining, involving the anonymization of data through generalization and suppression techniques. To bolster traditional approaches, concepts like k-anonymity, l-diversity, and t-closeness have been introduced to thwart re-identification risks. While de-identification remains pivotal in privacy protection, its efficacy in the realm of big data analytics faces challenges, particularly in addressing flexibility and effectiveness concerns, as well as heightened risks of re-identification due to the vast external data available. Developing efficient algorithms is crucial to enhance de-identification's suitability for privacy-preserving big data analytics. Common terms in the privacy domain include identifier attributes (e.g., full name), quasi-identifier attributes (e.g., age, gender), sensitive attributes (e.g., medical conditions), insensitive attributes (e.g., general information), and equivalence classes (sets of records sharing identical quasi-identifier values).
A. K-Anonymity
K-Anonymity offers a significant level of privacy protection by thwarting re-identification attempts, thereby ensuring highly accurate and secure data analysis. This privacy model serves to deter linking attacks by anonymizing datasets. A dataset achieves K-Anonymity when an individual's data in the published dataset is indistinguishable from at least k-1 other individual’s data. Consequently, an attacker cannot differentiate a specific record from the k-1 other individuals' records solely based on their quasi-identifier attributes.
Two primary techniques are proposed to reinforce K-anonymity in private datasets:
- Generalization involves substituting specific values with more generalized ones. For instance, replacing "male/female" with "person."
- Suppression entails concealing values by withholding them entirely, often replacing them with special characters like "*", "@".
Both techniques uphold the integrity of the data while bolstering K-Anonymity.
a. Suppression: This approach involves replacing certain attribute values with a placeholder symbol, such as '@'. Either all or selected values within a column can be substituted with '@'. In the anonymized Table 1, all entries in the 'Name' attribute and each value in the 'Postal code' attribute are replaced with '@'.
b. Generalization: In this method, specific attribute values are substituted with broader categories. For example, the value '19' in the 'Age' attribute might be replaced with (20,30), while '23' could be replaced with (20,30), and so forth.
Table 1: Healthcare Information Dataset
|
KEY ATTRIBUTE |
QUASI – IDENTITIERS ATTRIBUTE |
SENSITIVE ATTRIBUTE |
|||||
|
NAME |
AGE |
SEX |
POSTAL CODE |
DISEASE |
|||
|
Seetha |
35 |
Female |
23120 |
Chickenpox |
|||
|
Ram |
38 |
Male |
32103 |
COVID-19 |
|||
|
Varsha |
33 |
Female |
42182 |
Measles |
|||
|
Manasi |
30 |
Female |
13216 |
Meningitis |
|||
|
Siva |
40 |
Male |
21425 |
Viral hepatitis |
|||
|
Sam |
32 |
Male |
61321 |
COVID-19 |
|||
|
Aruvi |
37 |
Female |
21835 |
Measles |
|||
|
Naveen |
45 |
Male |
32167 |
Common cold |
|||
|
Nikitha |
42 |
Female |
42896 |
Chickenpox |
|||
TABLE 2: Publicly available LICENSE NUMBER Dataset
|
DRIVER’S LICENSE NUMBER |
NAME |
AGE |
SEX |
POTAL CODE |
|
DL-4839201437832 |
Seetha |
35 |
Female |
23120 |
|
DL-5647392745362 |
Ram |
38 |
Male |
32103 |
|
DL-7854325647834 |
Varsha |
33 |
Female |
42182 |
|
DL-5463728987654 |
Manasi |
30 |
Female |
13216 |
|
DL-3647589230123 |
Siva |
40 |
Male |
21425 |
|
DL-8364758320946 |
Sam |
32 |
Male |
61321 |
|
DL-2647364578964 |
Aruvi |
37 |
Female |
21835 |
|
DL-5467382987564 |
Naveen |
45 |
Male |
32167 |
|
DL-6473823456782 |
Nikitha |
42 |
Female |
42896 |
Upon comparing Table 1 and Table 2, the attacker could discern that Seetha is afflicted with Chickenpox. Despite the removal of key identifiers, an individual can still be identified by cross-referencing with publicly available data. This practice of combining released table data with publicly accessible information constitutes a Linking Attack. Thus, this privacy model serves to thwart such linking attacks. Consequently, attempting to identify an individual from a release provides only limited information, such as age, gender, and zip code. Table 3 below exemplifies a 2-anonymous table, where k=2, signifying that at least two tuples share identical values in the quasi-identifier attributes.
TABLE 3: 2-Anonymized Dataset
|
AGE RANGE |
SEX |
POSTAL CODE |
DISEASE |
|
(30 ,40) |
Female |
231@ |
Chickenpox |
|
(30 ,40) |
Male |
321@ |
COVID-19 |
|
(30 ,40) |
Female |
421@ |
Measles |
|
(30 ,40) |
Female |
132@ |
Meningitis |
|
(30 ,50) |
Male |
214@ |
Viral hepatitis |
|
(30 ,40) |
Male |
613@ |
COVID-19 |
|
(30,40) |
Female |
218@ |
Measles |
|
(30 ,50) |
Male |
321@ |
Common cold |
|
(30 ,50) |
Female |
428@ |
Chickenpox |
K-anonymous data, despite its protective measures, remains vulnerable to various attacks such as unsorted matching, temporal, and complementary release attacks. However, there's a silver lining: the introduction of a greedy O(k log k)-approximation algorithm offers an optimal solution for achieving k-anonymity through entry suppression. This algorithm aims to minimize the information withheld while ensuring that individuals remain anonymous within groups of size k. Nonetheless, achieving this privacy level is a complex task, as it involves rendering private records k-anonymous while withholding minimal information, an optimization problem proven to be NP-hard. Moreover, when attributes are suppressed instead of individual entries, the problem becomes even more challenging, also falling under the NP-hard category. Consequently, there's a shift towards adopting the L-diversity strategy for data anonymization.
B. L-Diversity
The l-diversity model (Distinct, Entropy, Recursive) extends the k-anonymity model by decreasing data granularity through generalization and suppression methods, ensuring that each record maps onto at least k different records. Addressing weaknesses in the k-anonymity model, l-diversity ensures that protecting identities to the level of k-individuals also safeguards corresponding sensitive values, particularly when sensitive values within a group are homogenous. The model prioritizes intra-group diversity for sensitive values in anonymization. However, its effectiveness depends on the range of sensitive attributes, when the sensitive attribute lacks diversity, fictitious data may need to be introduced to achieve L-diversity. While this enhances security, it can complicate analysis. Moreover, the l-diversity method is vulnerable to skewness and similarity attacks, limiting its ability to prevent attribute disclosure.
C. T-Closeness
T-closeness, an enhancement of l-diversity group-based anonymization, is utilized to safeguard privacy in datasets by reducing data granularity. This reduction, however, involves a trade-off, sacrificing some data management or mining algorithm efficacy to bolster privacy. The t-closeness model (Equal/Hierarchical distance) builds upon l-diversity by treating attribute values individually and considering the distribution of data values for each attribute. An equivalence class achieves t-closeness if the divergence of a sensitive attribute within this class from the attribute's distribution across the entire table is less than a specified threshold t. A table is deemed to have t-closeness when all equivalence classes exhibit t-closeness. The primary advantage of t-closeness lies in its ability to thwart attribute disclosure. However, as data size and diversity increase, the risk of re-identification also rises. The brute-force approach, which explores every potential table partition to find the optimal solution, requires significant computational time. Improvements have been made to this approach, reducing the computational complexity to a single exponential in n, albeit remaining far from polynomial time complexity.
VI. ENHANCING PRIVACY MODELS WITH MAPREDUCE FRAMEWORK
A proposed approach leverages the MapReduce framework for efficient data processing, particularly for handling large and distributed datasets. Data is partitioned into chunks processed by separate mappers, with outputs consolidated by reducers to produce final results.
MapReduce-based k-Anonymity: Our algorithm, akin to Mondrian, ensures insensitivity to data distribution across mappers. By splitting each equivalence class into (at most) q classes in each iteration, we enhance generality and reduce iterations.
MapReduce-based l-Diversity: Extending privacy models from k-anonymity to l-diversity involves integrating sensitive values into mapper outputs. Unlike k-anonymity, mappers in l-diversity receive both quasi-identifiers and sensitive attributes as input.
VII. ANONYMIZING BIG DATA STREAMS
Anonymizing big data streams poses unique challenges due to the need for real-time processing and the sheer volume of data. Existing k-anonymity approaches, suitable for static data, are not directly applicable to data streams due to their NP-hard nature and the impracticality of repeated scanning. The FADS algorithm, designed for data stream anonymization, faces limitations in handling large volumes and sequential processing.
To address these challenges, a new approach called FAST is proposed. FAST leverages parallelism to enhance the efficiency of the FADS algorithm and introduces a proactive heuristic to prevent publishing expired tuples. Experimental results demonstrate that FAST outperforms FADS and other existing algorithms, reducing information loss and cost metrics during the anonymization process.
Conclusion
In conclusion, the rapid growth and utilization of big data bring significant challenges in terms of privacy and security. While big data analytics offer immense potential for uncovering hidden patterns and insights, they also raise serious concerns regarding the protection of personal and sensitive information. This paper highlights the importance of privacy in big data and distinguishes it from security, emphasizing the need for comprehensive strategies to address both aspects effectively. Various privacy-preserving techniques, such as HybrEx, k-anonymity, T-closeness, and L-diversity, have been developed to safeguard privacy at different stages of the data lifecycle. However, despite the existence of these techniques, challenges persist in preserving privacy in big data environments. The paper identifies limitations and shortcomings of current privacy preservation strategies and introduces innovative approaches to address them. Through a comparative analysis of contemporary big data privacy approaches, the paper underscores the need for ongoing research and development to enhance privacy protection in the era of big data. By advancing privacy-preserving techniques and implementing robust privacy policies, we can harness the benefits of big data while safeguarding individual privacy rights and ensuring ethical data practices.
References
[1] Narayanan, A., & Shmatikov, V. (2008). Robust de-anonymization of large sparse datasets. In Security and Privacy, 2008. SP 2008. IEEE Symposium on (pp. 111-125). IEEE. [2] Sweeney, L. (2002). k-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 10(05), 557-570. [3] Li, N., Li, T., & Venkatasubramanian, S. (2007). t-closeness: Privacy beyond k-anonymity and l-diversity. In Data Engineering, 2007. ICDE 2007. IEEE 23rd International Conference on (pp. 106-115). IEEE. [4] Vaidya, J., & Clifton, C. (2002). Privacy-preserving k-means clustering over vertically partitioned data. In Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 206-215). [5] Aggarwal, C. C. (2005). On k-anonymity and the curse of dimensionality. In Proceedings of the 31st international conference on Very large data bases (pp. 901-909). [6] Fung, B. C. M., Wang, K., Chen, R., & Yu, P. S. (2010). Privacy-preserving data publishing: A survey of recent developments. ACM Computing Surveys (CSUR), 42(4), 1-53. [7] Gehrke, J., & McSherry, F. (2009). The case for privacy-aware data systems. Communications of the ACM, 52(4), 103-108. [8] El Emam, K., Dankar, F. K., Issa, R., Jonker, E., Amyot, D., Cogo, E., ... & Fineberg, A. (2009). A globally optimal k-anonymity method for the de-identification of health data. Journal of the American Medical Informatics Association, 16(5), 670-682. [9] Xiao, X., & Tao, Y. (2006). Anatomy: Simple and effective privacy preservation. In Proceedings of the 32nd international conference on Very large data bases (pp. 139-150). [10] Oliveira, R., Santos, C., & Rodrigues, J. J. (2015). Differential privacy in big data: A state-of-the-art survey. IEEE Access, 3, 1671-1679. [11] Xu, J., Li, D., & Yu, S. (2014). A survey of privacy-preserving data publishing in the big data era. IEEE Transactions on Big Data, 1(1), 1-16.
Copyright
Copyright © 2024 Mr. R. Ramakrishnan, R. Sujithra, A. Joice Niranjalin. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62103
Publish Date : 2024-05-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online