

Ijraset Journal For Research in Applied Science and Engineering Technology
Real-Time Face Mask Detection Using MobileNet V2
Authors: Poulami Ghosh, Somnath Panda, Arnab Ghosh
DOI Link: https://doi.org/10.22214/ijraset.2024.62213
Certificate: View Certificate
Abstract
The rapid disruption of international trade and travel caused by the COVID-19 epidemic has had an impact on our daily lives. The custom of donning a face mask for protection has evolved. In the near future, a lot of public service providers will demand that clients wear appropriate masks in order to use their services. Identification of face masks is becoming a crucial duty to support world culture. This paper outlines a condensed method for accomplishing this goal utilizing certain fundamental machine learning tools, such as TensorFlow, Keras, OpenCV, and Scikit- Learn. The project\'s goal is to identify face masks at a public event or gathering. MobileNet V2 is the algorithm employed in the project to accomplish the goal. There is a picture of a few people with and without masks. As an input dataset, a picture of a few individuals wearing and not wearing masks is employed. Pre- processing, data augmentation, training, testing, and image segmentation are some of the steps that go into reaching the project\'s goal. Creating a model that can identify people who are not wearing masks in public settings is the goal of this project. To guarantee adherence to the standards for public safety, this work can be combined with real-time applications at airports, train stations, businesses, schools, and other public locations.
Introduction
I. INTRODUCTION
The corona virus that caused COVID-19, was a disease that caused severe acute respiratory syndrome. The virus primarily spreaded through the air, where it is inhaled by droplets from respiratory symptoms such as coughing, sneezing, or colds of infected individuals. Wearing face masks and avoiding close contact with other people are only two of the restrictions that the WHO has put in place to stop the spread of this infection. This programme can be used in public gathering places to identify face masks that could slow the spread of Covid-19 during such a severe crisis.
The project's goal is to create a model that can be used to identify face masks in a crowd of people in order to stop spreading of infections for a situation like COVID-19. MobileNet V2 is utilised in its creation. The COVID-19 transmission can be prevented by using the built-in model from this study to identify people who are not wearing face masks on the surveillance cameras. Data on each camera point's position can be provided, allowing authorities to determine which areas need more attention. Identification of even a single person amongst a large crowd to prevent mass spreading of diseases is the novelty of this work and a futuristic approach that can be undertaken in various fields of the society.
II. LITERATURE SURVEY
A condition that produces severe respiratory issues is Nanette et al(2020) .'s Covid-19, also known as significant acute respiratory disorder. This infection is contagious and is conveyed by respiratory droplets from a sick person who talks, sneezes, or coughs when afflicted. This spreads quickly through direct contact with infected individuals as well as through touching contaminated objects or surfaces. Since there is currently no vaccine to protect against Covid-19, preventing infection seems to be the only method to protect ourselves. Exhausting a facemask hides the nose and mouth in public. As technology has developed, deep learning has proven useful in image processing for both detection and classification. techniques based on deep learning for facial recognition and facial mask detection. Significant acute respiratory disorder, or Covid-19 as described by Nanette et al. (2020) is a condition that causes severe respiratory problems and this illness is communicable. On the gathered dataset, the trained model exhibits a 96% accuracy rate of performance. The system develops a real- time facemask identification system using a raspberry Pi that notifies and records facial image data if the person being monitored is not donning one [1]. According to Anushka et al. (2020), the corona virus outbreak has wreaked havoc on the entire world. Wearing a mask is now required, among other things, to prevent the spread of the sickness, according to the World Health Organization.
Everyone in the nation likes to live a healthy lifestyle by using a mask during public gatherings in order to avoid contracting the terrible virus. Since there are so few datasets that contain both masked and unmasked images, recognizing faces when they are wearing masks is a challenging issue. Detecting facial masks using a layered Conv2D model is quite successful. This technique, which consists of a stack of 2-D convolutional layers with RELU activations and Max Pooling, was developed using Gradient Descent for training and binary cross entropy as a thrashing function. Two datasets were combined for the model's training. Testing and validation accuracy of 95% was attained. [2]
Corona virus disease has had a significant impact on the world in 2019, according to Jiang and Fan (2020). One of the most popular ways people defend themselves in public is by donning masks. Many public service providers only permit customers to use their services if they are properly masked. However, there aren't many studies on identifying face masks using image analysis. A very precise and powerful face mask detector is Retina Face Mask. Retina Face Mask is a one-phase detector that integrates numerous feature maps with high-level semantic data via an attribute pyramid network, and a context attention module to identify face masks explicitly. Use a cross-class object removal method to reject predictions with low confidence and a high intersection of union. [3]. According to Chen et al. (2020), the Covid-19 has spread widely since its massive breakout in December 2019, causing the entire world to suffer a great deal of loss. The easiest and most effective way to stop it at the source is to wear masks. Face masks are normally only worn occasionally and for a brief time. The GLCMs of the face mask micro-photos can be used to derive four attributes. The next step is to develop a three- result detection system using the KNN algorithm. Validation studies reveal that the system can achieve an accuracy of 82.87 percent on the testing dataset [4].
Principal component analysis was used to distinguish between mask and non-mask faces, according to Ejaz et al. (2019). The word "security" is essential in today's environment. Since face recognition is superior to other traditional ways like PIN, password, fingerprint, and so on, and because it is the most effective way to identify or authenticate a person, face recognition is widely employed in biometric technology to protect any system. These kinds of masks affect how accurately faces are recognized. Many non-masked facial recognition algorithms have recently been created that are extensively utilized and pro-vide higher performance. PCA is a more successful and effective statistical approach that is extensively used [5]. According to Meenpal et al. (2019), face detection has grown to be a very common issue in image processing and computer vision. Many modern algorithms use convolutional structures to increase their accuracy to the maximum extent possible. Even pixel information has been able to be retrieved because to these convolutional designs. the process for accurately generating face segmentation masks from any image, regardless of size. The faces in the image are semantically separated out using Fully Convolutional Networks during training. The FCN's out-put picture is cleaned up to eliminate unnecessary noise and prevent erroneous predictions [6].
According to Zhang et al., Face alignment and identification in an open setting are challenging issues to resolve, but they are essential for maintaining traffic order and public safety. In order to attain the optimum face area identification and attribute alignment of the driver's face on the road, the enhanced multi-task cascaded convolutional networks were utilized to anticipate face and attribute placement employing coarse to fine pattern. The ITS-MTCNN strategy also suggests a powerful online hard sample mining technique and an improved regularization method. The training scheme and divergence experiment are run in the self-built driver face database. Finally, comparison studies display the efficacy of the ITS-MTCNN scheme [7].
According to Wu et al. (2019), considerable representations for describing face appearance were needed for precise face identification. For attribute aggregation, current detectors, particularly those based on convolutional neural networks, apply functions like convolution to any native areas on each face and assume that all native alternatives will be equally effective for the recognition job. A proposal was made, using a learnable gaussian kernel to sculpt part-specific attentions, which would be employed to find the proper native area placements and scales to find dependable and illuminating face element alternatives. Later, interactions among native components are modelled using LSTM, and their contributions to detection tasks are modified utilizing face-specific notice. On three challenging face identification datasets, an in-depth testing was conducted to demonstrate the effectiveness of our hierarchical attention and construct comparisons with progressive techniques. According to Vallimeena et al. (2019), CNN algorithms have gained popularity recently for a range of computer vision- based applications, including disastermanagement systems that leverage crowdsourcing photos with sources. A frequent natural disaster that endangers human lives and property is flooding. The amount of damage in flood-affected areas is calculated using flood images of people taken using smart phone cameras to measure the depth of the water. Numerous CNN algorithms are available for these uses. Each one has a different architecture, which has an impact on the accuracy of the results [8].
Deep Metric Learning is utilized to detect and recognize human faces, according to Set et al. (2019). Deep metric learning, the methodology used in this study, blends face recognition with human object detection.
To evaluate recorded footage, real-time images or stream movies gathered by CCTV or any other video capturing equipment may be employed. The approach uses widely known classification algorithms to recognise and identify faces even in blurry pictures or strewn-together movies [9]. According to Kumar et al. (2019), multiple face detection and extraction are crucial for face recognition across a range of applications. The recommended approach utilised Discrete Wavelet Transform, Edge Histogram, and Auto-correlogram to extract features while Support Vector Machine was used for multiple face recognition. On the Carnegie Mellon University and BAO databases, the suggested method for MFD was tested. In this study article, the anticipated plan outperforms the current plan in terms of performance. Finally, a 90% accuracy level was reached. [10].
It is essential to abide by the recommendations made by the WHO and local health authorities given the range of the Covid-19 pandemic that happened around the world. The aforementioned papers were helpful in visualizing and comprehending the overall project's flow as well as in creating its architecture. It highlighted the input and its format that must be provided for each module along with the anticipated output. The literature works mentioned above concentrated on one aspect of finding people who aren't wearing masks. In light of all of these studies, another goal of our study is to use MobileNetV2 to identify persons who are not wearing face masks.
III. DATASET DESCRIPTION AND DESIGN DIAGRAM
Masks are one of the few preventative measures that were made mandatory during COVID-19 in the absence of immunization, making them essential for defending against respiratory illnesses. With the help of this information, a model may be developed to identify people who are wearing masks, are not wearing them, or are donning them incorrectly. 3833 photos from the two classes are included in this dataset. The classes are:
- With mask
- Without mask
Where, with mask class contains 1915 images and without mask contains 1918 images.
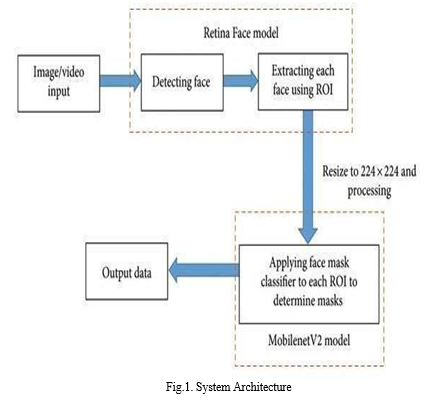
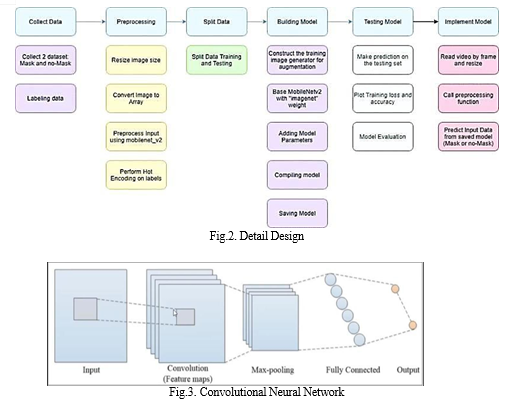
Figure 1 shows the detailed system architecture for the process of detecting face Masks and extracting and identifying the face without masks. The MobileNet V2 is being utilized to identify the person using the face mask classifier and the output data is the face identified without the mask. Figure 2 represents the detailed design of the process flow that includes steps of data collection, data pre-processing, data splitting, building model, developing test model and finally designing the implementation model. Figure 3 represents the design of the convolutional neural network model that helps to solve the algorithm to find out the face without mask. This entire design formulated in this work is thereby utilized to solve the proposed problem.
IV. PROPOSED METHODOLOGY
Through the use of MobileNetv2, an image classification technique, a machine learning algorithm was created for the face mask recognition in this work. The Convolutional Neural Network (CNN)-based approach known as MobileNetV2 was created by Google and has been enhanced for better performance. Two (02) original datasets were used in this study's experiments. For the training, validation, and testing phases, the dataset was taken from the Kaggle dataset so that the model could be applied to the dataset. The model can be created by doing the following steps: (i) data collecting, (ii) pre-processing, (iii) split the data, (iv) building the model, (v) testing the model, (vi) implement the model.
A. Data collecting
The procedure for gathering data is the initial step in creating a Face Mask Recognition model. Both mask users and non-users are represented in the dataset as training data. The model will tell people wearing masks apart from those who aren't. To build the model, this study used data from 1918 without a mask and data from 1915 with a mask. At this point, the image has been cropped so that the object's face is the only part that is still visible. The data then has to be labelled. Two groups of the acquired data—one with masks and the other without—have been created. After being labelled, the data is split into those two categories.
B. Pre-processing
Before the data is trained and tested, there is a pre-processing phase. The pre-processing technique entails four steps: scaling the image's size, converting it to an array, using MobileNetV2 to pre-process the input, and hot encoding labels as the last step. Scaling the image is an important pre-processing step in computer vision since training models perform so well. With a smaller image, the model will work more effectively. An image is scaled in this study to be 224 x 224 pixels. After that, the image will be used to pre- process the input. The next step is to create an array from the photographs in the dataset. The image is transformed into an array so that the loop function can call it. Following that, MobileNetV2 will pre-process input using the image.
C. Split the data
Following pre-processing, the data is divided into two batches, with training data making up 80% of each batch and testing data the remaining 20%. Each batch includes photographs both with and without a mask.
D. Building the model
The next phase is building the model. Six stages are required to produce the model: generating the augmented training picture, the MobileNetV2 base model creation, addition of model parameters, model compilation, training of the designed model and finally, saving and using the model for future prediction.
E. Testing the model
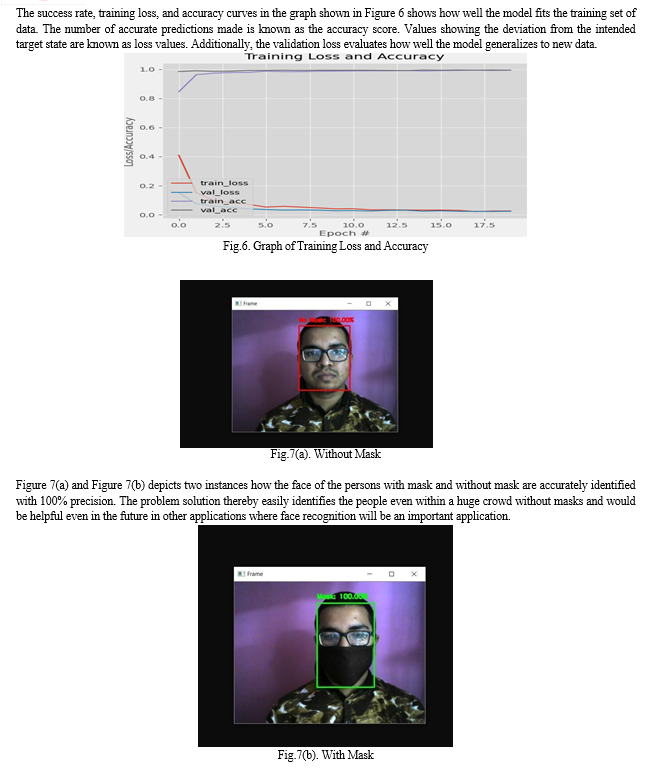
Making predictions about the testing set is the first stage. The outcome after 20 iterations of assessing the accuracy and loss during model training. Beginning with the second epoch, we will see an increase in accuracy and a decrease in loss. There is no longer a need for more iterations to improve the model's accuracy when the accuracy line is stable. The evaluation of the model is the subsequent phase. So then, the next step is making the model evaluation.
F. Implement the model
The system used in the video. The face detection method is used after reading the movie from frame to frame. If a face is found, the process moves on to the next step. Face detection frames will then undergo reprocessing, including picture scaling, array con- version, and input pre-processing with MobileNetV2. Predicting input data using the saved model is the next step. Using a model that has already been developed, forecast the processed input image. Along with the projected percentage, the video frame will also indicate if the subject is wearing a mask or not.
V. RESULTS AND DISCUSSION
A convolutional neural network of 53 layers deep is called MobileNetV2. The ImageNet database contains a pre-trained version of the network that has been trained on more than a million photos. MaxPooling is one of the key contributors to this precision. Along with reducing the number of parameters the model must learn, it gives the internal representation some basic translation invariance. This sample-based discretization method reduces the dimensionality of the input representation, which is a picture. The number of neurons has an optimal value that is not excessive. Having a lot of neurons and filters may result in subpar performance. The major portion (face) of the image is filtered out to correctly detect the presence of the mask without over-fitting thanks to the optimum filter settings and pool size.
To evaluate the effectiveness of classification using the attribute-sets identified by the various strategies in order to compare the performance of various attribute selection techniques. In order to achieve this, we employ the conventional methodology, which involves displaying classification results as a confusion matrix and then employing conventional metrics like precision, recall, F-score, and accuracy. Accuracy is the most widely used metric to indicate the percentage of correctly predicted observations, true or false. The correctness of a model can be ascertained using the following equation. In this example, for training a classification model, a false positive (a prediction of true when the item was actually incorrect) can have undesirable consequences. However, high accuracy scores generally suggest a good model. Likewise, if an article contains accurate facts, a forecast that it is wrong could damage trust. Consequently, three additional metrics are applied to account for the incorrectly classified observation: precision, recall, and F1-score.
Accuracy = |T P| + |T N|/ |T P| + |T N| + |F P| + |F N|
Recall indicates the total number of accurate classifications outside of the true class is estimated to determine this. In this case, the percentage of accurately predicted articles among all correctly predicted articles has been determined.
Recall = |T P|/ |T P| + |F N|
Conversely, the proportion of true positives to all events predicted as true is represented by the precision score. In this scenario, precision points to the proportion of positively predicted (true) items that are designated as such. Precision score signifies the ratio of true positives to all events considered true. Here, precision is determined by calculating the number of articles that are marked as true amongst all the positively predicted (true) articles.
Precision = |T P|/ |T P| + |F P|
The F1-score illustrates the recall versus precision trade-off. It calculates each difference's harmonic mean. It considers both false positive and false negative observations as a result.

VI. ACKNOWLEDGMENT
The authors would like to acknowledge the support rendered by the Department of Computer Applications, UEM Kolkata and Department of Electrical Engineering, UEM Kolkata for successful completion of the work. The authors would also like to thank the people who provided the necessary support for collection of datasets to test the efficiency of the suggested algorithm.
Conclusion
Covid-19 was a deadly disease and it became a widespread pandemic over the entire globe. It needed lots of steps and new ways were adapted such as use of masks, vaccination and social distancing to control the pandemic. While the specialists handled the vaccination component by adhering to the WHO\'s recommendations to stop the spread of this illness, the other steps were public oriented and depended on the drive of the people. Even then, some irresponsibility amongst the common mass such as improper use of masks led to spread of the disease. This project\'s goal is to use MobilenetV2 to distinguish between people wearing and not wearing masks. This algorithm transforms a busy input image into the desired result, which is the identification of people who aren\'t wearing masks. Lastly, it evaluates the numerical outcomes related to precision and accuracy based on the true outcomes of the events. The proper outcome from the designed problem would assist in identifying individuals who are not wearing masks. This would make it much easier for health and sanitary officials to follow the WHO recommendations. Using the methods mentioned above, this project was tried in a webcam, and the outcomes were as anticipated. It will be simpler to identify persons who are breaking the mask use policy with the widespread use of this work especially in crowded areas and public gatherings. In this research, a face mask detector was developed utilising Deep Learning, OpenCV, and Keras/TensorFlow. A two-class model of those wearing masks and those who are not was built to construct a face mask detector. On this mask/no mask dataset, MobileNetV2 was improved and a classifier was produced that is approximately 99% accurate. After that, this face mask classifier was used to analyse both photos by: Finding faces in pictures. removing each face one at a time applying to our classifier for face masks. Since the MobileNetV2 architecture was employed, the face mask detector is accurate and computationally efficient, which makes it simpler to deploy the model on embedded systems (Google Coral, Nano, Raspberry Pi, Jetson, etc.). Corporate behemoths from a variety of industries are utilising AI and ML to advance humanity in the face of the epidemic. Digital product development firms are launching mask detection API services that let programmers quickly construct a face mask identification system to help the community in times of emergency. The system guarantees accurate and immediate face recognition of users who are wearing masks. Additionally, the solution is simple to integrate into any company system that already exists while maintaining the security and privacy of user data. Thus, the face mask detection system will be the top digital solution for the majority of industries, particularly those in retail, healthcare, and business. Here, the researchers have found out a way to assist the world in using digital solutions to serve the communities.
References
[1] S.V. Militante, N.V. Dionisio, “Real-time facemask recognition with alarm system using deep learning”, 11th IEEE Control and System Graduate Research Colloquium (ICSGRC), 2020, pp. 106–110. [2] A.G. Sandesara, D.D. Joshi, S.D. Joshi, Facial Mask Detection Using Stacked CNN Model, 2020. [3] X. Fan, M. Jiang, “Retina Mask: a face mask detector”, Computer Vision and Pattern Recognition, 2020. [4] Y. Chen, M. Hu, C. Hua, G. Zhai, J. Zhang, Q. Li, “Face mask assistant: Detection of face mask service stage based on mobile phone”, IEEE Sensors Journal, Vol. 21(9), 2021, pp. 11084-11093. [5] M.S. Ejaz, M.R. Islam, M. Sifatullah, A. Sarkar, “Implementation of principal component analysis on masked and non-masked face recognition”, 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), IEEE, 2019, pp.1-5. [6] T. Meenpal, A. Balakrishnan, A. Verma, “Facial mask detection using semantic segmentation”, 4th International Conference on Computing, Communications and Security (ICCCS), IEEE, 2019, pp. 1-5. [7] Y. Zhang, P. Lu, X. Lu, J. Li, “Face detection and alignment method for driver on highroad based on improved multi-task cascaded convolutional networks”, Multimedia Tools Application, vol. 78(18), 2019, pp. 26661-26679. [8] P. Vallimeena, U. Gopalakrishnan, B.B. Nair, S.N. Rao, “CNN algorithms for detection of human face attributes–a survey”, International Conference on Intelligent Computing and Control Systems (ICCS), IEEE, 2019, pp. 576-581. [9] S.S. Sapkal, A.P. Mengane, T.A. Kalbhor, N.S. Ohol, “Human Face Detection and Identification using Deep Metric Learning”, International Research Journal of Engineering and Technology (IRJET), Volume: 06 Issue: 05, 2019, pp. 4379-4386. [10] S. Kumar, S. Singh, J. Kumar, “Multiple Face Detection using Hybrid Features with SVM Classifier”, Data and Communication Networks. Springer; Singapore, 2019, pp. 253-265.
Copyright
Copyright © 2024 Poulami Ghosh, Somnath Panda, Arnab Ghosh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62213
Publish Date : 2024-05-16
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online