

Ijraset Journal For Research in Applied Science and Engineering Technology
Sepsis Prediction
Authors: Mrs. Nagaveni B Nimbal, Nikhil K H, Rahul B M , Prithvi Raj, Sagar Naidu
DOI Link: https://doi.org/10.22214/ijraset.2024.62010
Certificate: View Certificate
Abstract
Sepsis manifests as a life-threatening condition wherein the body\'s response to infection triggers organ dysfunction. Typically, this immune response inadvertently damages the body\'s tissues while combating the infection. Within the overall range of sepsis, septic shock represents a critical subset characterized by notable circulatory, cellular, and metabolic abnormalities, resulting in a increased mortality rate than standard sepsis. Noteworthy is the consensus from various studies highlighting the crucial role of early intervention in enhancing the survival chances of sepsis patients. Given the urgency of timely recognition and treatment, there is a heightened focus on sepsis prediction. Traditional scoring systems such as APACHE, SAPS, and SOFA provide insights into disease severity and prognosis but lack the capacity for early sepsis detection. This study uses ML techniques and analyzes extensive patient data, which includes vital signs and medical history, to identify important indicators and prognostic patterns that find the occurrence of sepsis. By applying advanced algorithms like neural networks and ensemble methods, the model shows impressive accuracy in predicting the progression of sepsis. In addition, detailed analysis of trait significance helps to understand key prognostic markers, allowing clinicians to strategically prioritize interventions. Successful integration of this prognostic tool into the clinical setting offers a promising opportunity for preventive management of sepsis, which can reduce mortality and improve patient outcomes. We built a (LSTM) network to distinguish the internal association between different. indicators in clinical data. Analysis includes use of electronic health records, multicenter collaboration, and challenge development. Our goal is to support the research of accurate and timely sepsis predictors, ultimately improving patient outcomes.
Introduction
I. INTRODUCTION
Recent advancements in integrated technologies within the medical sector have significantly enhanced the precision of medical professionals. Among its various applications, disease prediction stands out as a primary focus. The landscape of healthcare procurement and management has witnessed substantial growth and evolution, particularly in improving health outcomes. Sepsis, a severe medical condition triggered by the body's extreme response to infection, stands as a major global cause of death, emphasizing the cause for swift and precise diagnosis. Timely identification of sepsis is necessary for effective intervention and better patient outcomes. The advancement of predictive analytics and ML offers a promising path toward constructing robust models capable of anticipating sepsis development even before it becomes clinically apparent. The study aims in delving into extensive patient data, including physiological factors, biomarkers, and historical records, to establish a powerful predictive framework. Through sophisticated algorithms the goal is to generate dependable predictive model. Integrating such predictive tools into clinical settings holds tremendous potential to transform sepsis management by enabling proactive interventions, potentially lowering mortality rates, and elevating patient care standards.
II. TERMINOLOGIES
A. Machine Learning
The growth seen in algorithms that allow computers to find the patterns from data and improve their performance is called machine learning, a branch of artificial intelligence. Statistical, mathematical and data processing are used to investigate and understand patterns in data. It is on the idea of ??statistical learning. Many tasks, such as natural language processing, predictive modelling and image recognition, benefit from the application of machine learning techniques. They can learn from large data sets and adapt to new information, helping you make predictions and gain insights from complex data. Machine learning is seen in many applications across industries such as manufacturing, healthcare, finance and entertainment.
B. Support Vector Machine
LSTM is special type of (RNN) architecture that is particularly good at modelling sequential data. What distinguishes LSTM from the traditional RNNs is its ability to maintain long-term data dependence. This is achieved by a more complex structure that consists memory cells, forget gates, output gates and input gates.
Memory cells act as a conveyor belt so that information flows unchanged when needed, which alleviates vanishing gradient problem which occurs in traditional RNNs. Input gate controls the flow of new data into memory cell, while a forget gate controls which data is ejected from the cell. Finally, the output port determines the data that is sent from the memory cell to rest of the network.
III. LITERATURE SURVEY
A. A Targeted real-time Warning score (TREW-Score) for Septic Shock.
Clinical trials and various machine learning algorithms have been tested in the early prediction of sepsis and sepsis 3. Sepsis is the leading cause of death that is complicated to treat despite modern antibiotics. Early aggressive treatment of this disease improves patient mortality, but the tools currently available in the clinic cannot identify who will develop sepsis and late manifestation, septic shock, until patients are advanced. Using data from patient monitors and medical records to develop TREW-Score that shows which patients are at risk for septic shock using supervised ML with MIMIC-III data.
???????B. ML for Predicting Sepsis and Systematic review along with meta-analysis of Diagnostic test Accuracy.
In recent scenarios, medicine has demonstrated that machine learning has begun to analyze large volumes of data. ML models for the fast diagnosis of sepsis are based on either a left- or right-aligned concept. Models present in the left predict the onset of sepsis followed by a fixed time point at different time points, such as admission or before surgery. Right-aligned models simultaneously predict whether sepsis will occur over a period of time and are also known as real-time or continuous predictive models. From a clinical perspective, they are particularly useful because they can trigger direct clinical effects, such as usage of antibiotics. Based on their possible implementation options and the wide range of left-aligned models, right-aligned models are more widely being used in this field.
???????C. Feature Selection Which Might Improve DNN for Bioinformatics Problems.
A Bioinformatics dataset often contains a large amount of features, and not all features may be relevant or contribute equally well to the prediction task, helping to lower the dimensionality of the input space, avoid the curse of dimensionality, and potentially improve model generalization. Irrelevant data can cause overfitting and performance degradation, feature selection filters out irrelevant data, improving model reliability. It deals with multi-collinearity problems by selecting a representative of features that capture meaningful information. Effective approaches include filter methods (e.g., correlation-based feature selection), wrapper methods (e.g., recursive feature elimination), and embedded methods (e.g., L1 regularization). The choice of approach depends on characteristics of bioinformatics data and the goals of the analysis. Integrating feature selection which is part of development process can increase the effectiveness of NN in bioinformatics applications.
IV. DATASET
The dataset used is collected from Medical Information Mart for Intensive Care (MIMIC-III) project which aims at making health care data sets of the human body available for future discoveries. The chosen type of dataset is in range from child below 10 and above 60 in adults. Data has the following attributes:
- Heart Rate
- SBP
- Respiratory rate
- Shock index
- Fraction of inspired oxygen
- Glasgow coma scale
- DBP
- Temperature
- Oxygen saturation
- Glucose
- Blood urea nitrogen
- Creatinine
- Bun creatinine ratio
- WBC count
- Platelet count
- Partial pressure of oxygen
- Total bilirubin
- Direct bilirubin
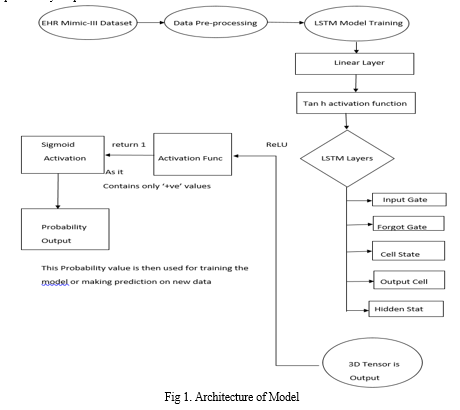
V. ARCHITECTURE
The input is a 3D tensor with dimensions [Batch Size, Sequence Length, dim input]`, where `dim input` is the total number of attributes present in input data ,
- The input then is first passed through a completely connected linear layer with `1028` output units, followed by a hyperbolic tangent (`tanh`) activation function.
- The output of linear layer is then fed to an LSTM (Long Short-Term Memory) layer with `100` hidden units and `4` layers. The LSTM layer processes the input sequence step by step, maintaining a hidden state and a cell state that captures long term dependencies in data.
- The LSTM layer consists of several components: Input Gate: Determines the new input should be added to the cell state.
- Forget Gate: Determines how much of the previous cell state should be forgotten or retained.
- Cell State: The memory component of the LSTM, which stores and updates the state over time.
- Output Gate: Determines the cell state should be used for producing the output hidden state.
- Hidden State (h_t): The output of LSTM cell at each time step, representing the present state based on input and previous states.
4. The output obtained in the LSTM layer is a 3D tensor with dimensions `[Batch Size, Sequence Length, hidden_size=100]`.
5. The end output of LSTM is then sent through a fully connected linear layer having `32` output units, followed by ReLU activation function.
6. Finally, the output is sent through a fully connected linear layer with `1` output unit, and a sigmoid activating function is used to obtain the probability output.
VI. ALGORITHM
- Step 1. Start
- Step 2. Import necessary libraries: pandas, sklearn, Pytorch, numpy, matplotlib
- Step 3. Data Processing
- Step 4. Loading and sequencing data
- Step 5. Define a class to load the dataset
- Step 6. Defining the LSTM model
- Step 7. Training and evaluation functions
- Step 8. Inference cell which has Prediction function
- Step 9. The Main cell where training and evaluation of model , where dataset is sent through the model .
- Step 10. The corresponding predictions are compiled and shown in an tabular form .
Conclusion
In conclusion, the progression of predictive analytics, specifically through ML and deep learning methodologies like neural networks and LSTM models, presents a substantial opportunity to revolutionize sepsis management. These predictive models, by deciphering complex patterns within diverse patient data, facilitate early recognition of sepsis onset, empowering clinicians with proactive intervention plans. Integrating computational techniques into clinical settings represents a significant stride towards more precise and prompt detection, potentially lowering mortality rates and enhancing patient care outcomes. Ongoing advancements in this domain offer a promising prospect where sepsis, a critical medical condition, can be anticipated and handled more effectively, ultimately saving lives and refining healthcare practices. The model\'s target variables align with the characteristics outlined in the study conducted by Henry et al.
References
[1] Annette Leuren, L.M. et al. Machine learning for the prediction of sepsis: a systematic review and meta- analysis of diagnostic test accuracy. Intensive Care Med. (2020). [2] Z. Chen, M. Pang, Z. Zhao, S. Li, R. Miao, Y. Zhang, X. Feng, X. Feng, Y. Zhang, M. Duan, L. Huang, and F. Zhou, “Feature selection may aid deep neural networks to provide still better results for the bioinformatics problems,” Bioinformatics (2019). [3] Kam, H. J. & Kim, H. Y. Learning representations and patterns for the early detection of sepsis using deep neural networks. Computers in biology and medicine 89, 248–255 (2017). [4] Desautels, T. et al. Prediction of sepsis in the intensive care unit with minimal electronic health record data: a machine learning approach. JMIR Med. Inform. 4, e28 (2016). [5] Henry, K. E., Hager, D. N., Pronovost, P. J. & Saria, S. A targeted real-time early warning score (trewscore) for septic shock. Science translational medicine 7, 299ra122–299ra122 (2015). [6] Johnson AE, Shen L, Lehman LH, Ghassemi M, et al. MIMIC-III, a free accessible critical care database. Data 2016;3:160035 [doi: 10.1038/sdata.2016.35].
Copyright
Copyright © 2024 Mrs. Nagaveni B Nimbal, Nikhil K H, Rahul B M , Prithvi Raj, Sagar Naidu. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62010
Publish Date : 2024-05-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online