

Ijraset Journal For Research in Applied Science and Engineering Technology
Smart Video Surveillance Using Deep Learning
Authors: Nakshatra Garad, Prof. Rakhi S. Punwatkar
DOI Link: https://doi.org/10.22214/ijraset.2024.60441
Certificate: View Certificate
Abstract
There is a lot of assessment happening in the business about video observation among them; the occupation of CCTV accounts has been blocked. CCTV cameras are put all around the spots for perception and security. In today\'s digital age, the increasing availability of data and advancements in computer vision have paved the way for numerous applications of object detection. This powerful technology has found its significance in various domains, including video surveillance and image retrieval systems. Object detection enables machines to identify and locate objects within images or video frames, providing valuable insights and aiding in decision-making processes. This article explores the applications, challenges, techniques, and future trends of object detection in the context of video surveillance and image retrieval systems. Object detection is a computer vision technique that involves identifying and localizing objects within images or video frames. Unlike image classification, which assigns a single label to an entire image, object detection goes a step further by detecting and delineating the individual objects present. It enables computers to comprehend visual data and interact with the world, much like humans do.
Introduction
I. INTRODUCTION
Video Surveillance has been used in numerous applications including old consideration and home nursing, security and so on. Object detection plays a crucial role in various real- world applications. In the domain of video surveillance, it enables the automatic monitoring and analysis of security camera footage, detecting and tracking objects of interest such as intruders, vehicles, or suspicious activities. By alerting security personnel in real-time, object detection enhances situational awareness and improves response times. In image retrieval systems, object detection enables efficient searching and indexing of visual content. By automatically identifying objects within images, users can search for specific objects or categories, making it easier to organize, retrieve, and analyze large image databases. This capability finds applications in areas like e-commerce, content moderation, and social media analysis.
II. METHODS AND MATERIAL
Alright, let's talk about the awesomeness of object detection in video surveillance. It's like having superpowers to analyze video streams in real-time. With object detection, security systems can automatically track objects and events, detecting weird stuff like unauthorized access, loitering, or someone leaving their stuff behind. It's like having eyes everywhere, watching out for trouble and giving us a heads up.
But wait, there's more! Object detection also helps in traffic monitoring and management. It can detect vehicles, pedestrians, and all sorts of things on the road, making traffic flow estimation and congestion detection a piece of cake. And hey, it even helps with autonomous driving! It's like having a super-smart cop directing traffic and making our roads safer and smoother.
- Data Collection: We collected a dataset of images containing various objects that we wanted to detect using YOLO.
- Data Preprocessing: The dataset was preprocessed by resizing images, normalizing pixel values, and augmenting data to improve model generalization.
- Model Training: We trained the YOLO model on the preprocessed dataset using a deep learning framework such as TensorFlow or PyTorch
- Model Evaluation: We evaluated the trained model on a separate validation dataset to measure its performance in terms of accuracy, precision, recall, and speed.
- Inference: We performed inference on test images and videos to demonstrate the object detection capabilities of the YOLO model. object detection is a computer vision task that uses deep learning techniques to detect objects in images and videos.
III. PROPOSED METHODOLOGY
The surveillance system can identify objects via live video stream over a URL, in an image or an IP webcam stream. It also offers surveillance features as motion detection in the scene. OpenCV is a huge open-source library for computer vision, image recognition, video and image processing and machine learning it plays an important role in today’s object detection system. Being an open- source library OpenCV has a large base of keeping it updated is used in large scale. Hence the proposed system used opencv at it fullest. Run the Python ‘.exe’ file to start the GUI.
To capture video using webcam user is needed to enter ‘0’ in the blank space or the ‘ip webcam’ link also user can keep the blank space ‘as it is’ before choosing any of the option to experience the prototype or an example of how the system works. Youtube videos can also be used or live streamed over the system all user need is to enter the video url. The image support is also vast ex: jpg, jpeg, png, jiff, etc are readily supported by the system if provided with exact url.
A. YOLO
YOLOv3 is the most alteration of the You Only Look Once (YOLO) approaches. The most well- known computer vision tasks are image classification, aiming at assigning each image in a dataset to one of the two or more categories. If you not only want to make use of detecting the presence of an object, but also of locating where this object is within the picture, you can use of the method called as “object localization”. Now, the most complex, and interesting process of the three is object detection (leaving out object segmentation). In most real-life examples, we want our model to go beyond recognizing and locating only one object, and detect multiple objects from the given same image. Object detection does just this operation and draws a so-called bounding box around each individual object. The most current of the main versions is the third iteration of the approach, namely YOLOv3. In each version, improvements have been made over the previous one. The initial version proposed the general architecture, after which the second variation improved accuracy significantly while making it faster.
YOLOv3 refined the design further by using tricks, such as multi-scale prediction and bounding box prediction through the use of logistic regression. While the accuracy increased dramatically with this version, it traded off against speed which reduced from 45 to 30 frames per second.
There are also several metrics that evaluate the accuracy too. For example, True Positive Rate (TPR), False Positive Rate (FPR), F1-score, and Log Average Miss Rate (MR). In addition to these metrics, object detection models can also be evaluated based on their computational efficiency.
The basic idea behind YOLO is to divide the input image into a grid of cells and, for each cell, predict the probability of the presence of an object and the bounding box coordinates of the object. The process of YOLO can be broken down into several steps:
- Input image is passed through a CNN to extract features from the image.
- The features are then passed through a series of fully connected layers, which predict class probabilities and bounding box coordinates.
- The image is divided into a grid of cells, and each cell is responsible for predicting a set of bounding boxes and class probabilities.
- The output of the network is a set of bounding boxes and class probabilities for each cell.
- The bounding boxes are then filtered using a post-processing algorithm called non-max suppression to remove overlapping boxes and choose the box with the highest probability.
- The final output is a set of predicted bounding boxes and class labels for each object in the image.
One of the key advantages of YOLO is that it processes the entire image in one pass, making it faster and more efficient than two-stage object detectors such as R-CNN and its variants.
YOLO is widely used in real-world projects because of its accuracy and speed; its main powerful sides can be listed like the following:
a. Real-time object detection: YOLO is able to detect objects in real-time, making it suitable for applications such as video surveillance or self-driving cars.
b. High Accuracy: YOLO achieves high accuracy by using a convolutional neural network (CNN) to predict both the class and location of objects in an image.
c. Single-shot Detection: YOLO can detect objects in an image with just one forward pass through the network, making it more efficient than other object detection methods that require multiple passes.
d. Good Performance on small Objects: YOLO is able to detect small objects in an image because of its grid-based approach.
e. Efficient use of GPUs: YOLO uses a fully convolutional network architecture, which allows for the efficient use of GPUs during training and inference.
f. Ability to Handle Multiple Scales: YOLO uses anchor boxes, which allows the model to handle objects of different scale.
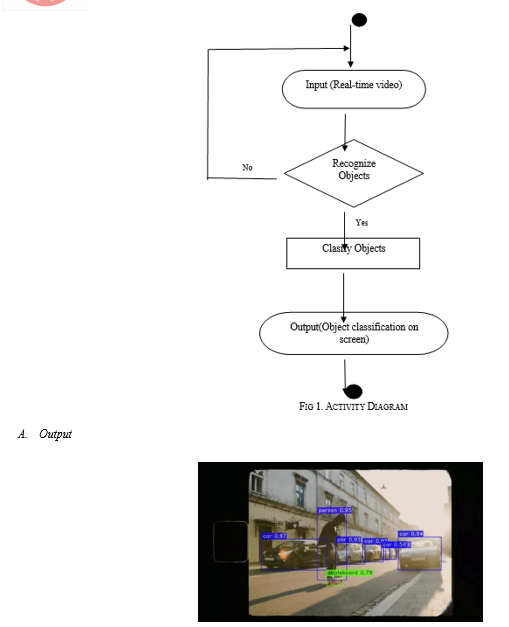 ???????
???????
Conclusion
In this paper we have examined about different reasons for irregularities and procedures to distinguish the inconsistencies. Though we leave the guide by examining the issues that emerge during the identification of peculiarities as a further extent of distinguishing procedures that beat the issues. Intelligent video surveillance using the YOLO object detection algorithm attained exceptional performance. Once models were trained on the available data. The system was able to perform with higher accuracy and while identifying objects and classes as well detecting motion based on optimized algorithms that were used. The neural networks and algorithms used performed well with confound predictions. GUI created allowed user to use features more efficiently and practically and each module was working efficiently and increased overall user experience overall.
References
[1] Ahmed, Md.Tofael & Rahman, Maqsudur & Nur, Shafayet & Islam, Azm & Das, Dipankar. (2021). Deployment of Machine Learning and Deep Learning Algorithms in Detecting Cyberbullying in Bangla and Romanized Bangla text: A Comparative Study. 1-10. 10.1109/ICAECT49130.2021.9392608. [2] V. Singh and M. Kankanhalli, “Adversary aware surveillance systems,” Information Forensics and Security, IEEE Transactions on, vol. 4, no. 3, pp. 552–563, 2009. [3] S. Avidan, “Ensemble tracking,” IEEE transactions on pattern analysis and machine intelligence, pp. 261–271, 2007. [4] X. Yu, K. Chinomi, T. Koshimizu, N. Nitta, Y. Ito, and N. Babaguchi, “Privacy protecting visual processing for secure video surveillance,” in ICIP, 2008, pp. 1672–1675. [5] Y. Cong, H. Gong, S. Zhu, and Y. Tang, “Flow mosaicking: Real-time pedestrian counting without scene-specific learning,” in CVPR, 2009, pp. 1093–1100. [6] H. Zhong, J. Shi, and M. Visontai, “Detecting unusual activity in video,” in CVPR, 2004. [7] A. M. Cheriyadat and R. J. Radke, “Detecting Dominant Motions in Dense Crowds,” Selected Topics In Signal Processing, IEEE Journal Of, vol. 2, no. 4, pp. 568–581, 2008. [8] C. Loy, T. Xiang, and S. Gong, “Detecting and discriminating behavioral anomalies,” Pattern Recognition, vol. 44, no. 1, pp. 117–132, 2011
Copyright
Copyright © 2024 Nakshatra Garad, Prof. Rakhi S. Punwatkar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60441
Publish Date : 2024-04-16
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online