

Ijraset Journal For Research in Applied Science and Engineering Technology
Stock Prediction using LSTM Technique
Authors: Aditya Kumar Singh, Anurag Gupta, Faraz Rabbani, Abhijeet Yadav , Mr. Atma Prakash Singh
DOI Link: https://doi.org/10.22214/ijraset.2024.61815
Certificate: View Certificate
Abstract
We attempt to use a machine learning approach to anticipate stock prices in this project. When it comes to stock price predictions, machine learning works well. The goal is to forecast future stock prices. make more accurate and better investment decisions We propose incorporating mathematical functions into stock prices. To arrive at an acceptable timescale, examine the prediction system, machine learning, and other external factors. delivers accurate stock predictions and lucrative trades There are some There are two types of stocks. Day trading is another name for intraday trading. The phrase \\\"day trading\\\"was thrown around. Interday traders invest in a diverse range of assets. at least one day after another, and frequently for several days or weeks, LSTMs are quite effective in solving sequence prediction problems.because they may store information from the past.
Introduction
I. INTRODUCTION
We've all heard the term stock, without a doubt. Stock, in particular, is linked to partners and organisations that have become well-known and are settling into the marketization cosmos. The second word for the stock is share, which is commonly used in ordinaryconversation. It's even referred to as a growth plan, andit's something that people perceive to be a long-term investment that generates and distributes abundant assets during retirement. A successful stock forecastcan result in large gains for both the seller and thebroker. Prediction is sometimes described as chaotic rather than random, meaning that it can be predicted by studying the history of the relevant stock market. Artificial intelligence in the form of machine learning.
The dataset used in machine learning is crucial. Thedata source Because a small modification in the data might produce large changes in the conclusion, it should be as specific as possible. This project entails on a dataset collected, supervised machine learning is used. Yahoo Finance is a search engine for financial information. The following five variables make up this dataset: open, close, low, high, and volume are all options. The terms open, close, low, and high are used. multiple stock bid prices at different periods with virtually direct names. The volume is the number ofshares that have passed from one person to another. During the historical period, one owner to another. The model is then put to the test. the test results For this, regression and LSTM models are used, separate speculation The goal of regression is to reduce error, and LSTM helps with that. helps you recall things.
II. RECURRENT NEURAL NETWORK (RNN) AND LONG SHORT-TERM MEMORY (LSTM)
Long Short Term Memory (LSTM) is one of several types of RNNs, which can also collect data from past stages and use it for future prediction [7]. In general, an artificial neural network (ANN) consists of three layers:
- input layer
- Hidden layers
- Output layer
dimension of the data, the nodes of the input layer connect to the hidden layer via links called ‘synapses’. The relation between every two nodes from (input to the hidden layer), has a coefficient called weight, which is the decision-maker for signals. The process of learning is naturally a continuous adjustment of weights, after completing the process of learning, the Artificial NN will have optimal weights for each synapse.The hidden layer nodes apply a sigmoid or tangent hyperbolic (tanh) function on the sum of weights coming from the input layer which is called the activation function, this transformation will generate values, with a minimized error rate between the train and test data using the SoftMax function. The values obtained after this transformation constitute the output layer of our NN, these values may not be the best output, in this case, a backpropagation process willbe applied to target the optimal value of error, and the backpropagation process connects the output layer to the hidden layer, sending a signal conforming the best weight with the optimal error for the number of epochs decided. This process will be repeated trying to improve our predictions and minimize the prediction error. After completing this process, the model will be trained. The class of NN that predict future value based on the passed sequence of observations is called Recurrent Neural Network (RNN) this type of NN makes use of earlier stages to learn data and forecast future trends. The earlier stages of data should be remembered to predict and guess future values, in this case, the hidden layer act as a stock for the past information from the sequential data.
The term recurrent is used to describe the process of using elements of earlier sequences to forecast future data.
Since RNNs cannot store long- term memories, the use of long-term memory (LSTM) based on " memory strings" has proven to be very useful for predicting when long-term data is present. In LSTM, the memorization of the previous step can be performed through the gate with the memory line active. This diagram illustrates aLSTM node configuration
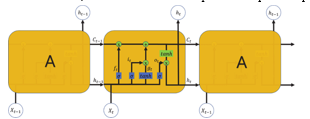
Fig -1: Figure
The ability to memorize the sequence of data makes the LSTM a special kind of RNN. Every LSTM node must be consisting of a set of cells responsible for storing passed data streams, the upper line in each cell links the models as a transport line handing over data from the past to the present ones, and the independence of cells helps the model dispose filter of add values of acell to another. In the end, the sigmoidal neural network layer composing the gates drive the cell to an optimal value by disposing or letting data pass through. Each sigmoid layer has a binary value (0 or 1) with 0 “let nothing pass through”; and 1 “let everything pass through.” The goal here is to control the state of each cell, the gates are controlled as follow: Forget Gate outputs a number between 0 and 1, where 1 illustrates “completely keep this”; whereas, 0 indicates “completely ignore this.” Memory Gate chooses which new data will be stored in the cell. First, a sigmoid layer “input door layer” chooses which values will be changed. Next, a tanh layer makes a vector of new candidate values that could be added to the state. The output gate determines the output of each cell. The output value is based on the status of the cell with the filtered and most recently added data.
III. METHODOLOGY AND DATA
The data in this article consists of the daily market prices of two stocks on the New York Stock Exchange NYSE (GOOGL and TSLA) obtained from Yahoo Finance. For GOOGL, the data series covers the period from January 1, 2005, to May 10, 2023, and for TSLA, thedata series covers the period from January 1, 2005, to May 10, 2023. To build our model we will use an LSTM RNN. Our model uses 70% of the data for training and 30% of the remaining data for testing. Optimize the model using root mean squared error for training. We also used 4, different epochs (12 epochs, 25 epochs, 50 epochs, and 100 epochs) for the training data, and the model consists of:
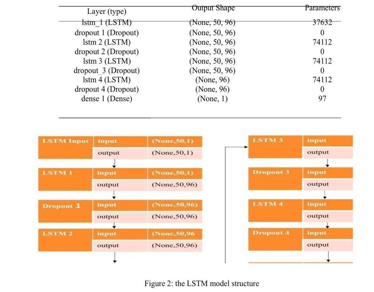
IV. RESULT AND DISCUSSION
After training the NN, the test results showed different results, and the number of epochs and data length significantly affect the test results. For example, if we change the data set for TSLA from January 1, 2005 to May 10, 2023, the result is:
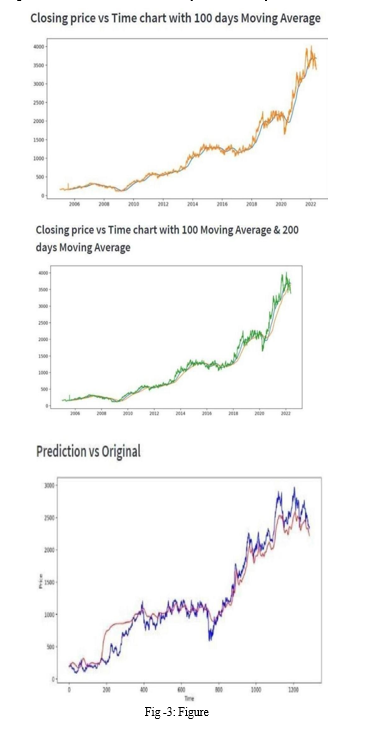
Looking at the data, you can see that initially the data was less volatile and had lower values. In Figure, the Blue line represents the actual market value and the Redline represents the predicted price value after TSLA started peeking. A large value increases the volatility of the asset and changes its characteristics. In our case, itis better to avoid this kind of change. Our model lost its open price tracking over the 600-700 days we tested, consistent with changes in data characteristics.
V. ACKNOWLEDGEMENT
Our college, Babu Banarasi Das Institute of Technology & Management, is delighted to have provided us with a secure atmosphere in which to work on this project.. as well as to our management, mentors, and professors for their assistance and support.
Conclusion
This paper proposes an LSTM-based RNN built to predict the future value of GOOGL and TSLA assets, and the result of our model showed promising results. The test results confirm that our model can track changes inthe open price for both assets. For future work, we will try to find the best set of combat data lengths and the number of training periods that best fit our assets and maximize the accuracy of our predictions.
References
[1] J. F. E. Tay and L. Cao, “Application of support vector machines in financial time series forecasting,” Omega, vol. 29, no. 4, pp. 309– 317, 2001. [2] B. Bick, H. Kraft, and C. Munk, “Solving constrained consumption- investment problems by simulation of artificial market strategies,” Management Science, vol. 59, no. 2, pp. 485– 503, 2013. [3] B. Adrian and L. Nathan, “An introduction to artificial prediction markets for classification,” Journal of Machine Learning Research, vol. 13, pp. 2177–2204, 2012. [4] A. Devitt and K. Ahmad, “Sentiment polarity identification in fi- nancial news: A cohesionbased approach,” in Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics (ACL-07), June 2007, pp. 984–991. [5] V. Lavrenko, M. Schmill, D. Lawrie, P. Ogilvie, D. Jensen, and J. Allan, “Mining of concurrent text andtime series,” in Proceedings of the KDD-2000 Workshop on Text Mining, 2000, pp. 37–44. [6] R. P. Schumaker and H. Chen, “Textual analysis of stock market prediction using breaking financial news: The AZFin text system,” ACM Transactions on Information Systems (TOIS-09), vol. 27, no. 2, pp. 12:1– 12:19, 2009. [7] X. Ding, Y. Zhang, T. Liu, and J. Duan, “Using structured eventsto predict stock price movement: An empirical investigation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP-14). Association for Computational Linguistics, 2014, pp. 1415–1425. [8] M. Hagenau, M. Liebmann, M. Hedwig, and D. Neumann, “Auto- mated news reading: Stock price prediction based on financial news using context-specific features,” in System Sciences, 2012. Proceed- ings of the 45th Annual Hawaii International Conference on System Sciences (HICSS-12). IEEE, 2012, pp. 1040–1049. [9] M. Robert, R. Bharath, S. Mohammad, K. Gert, and P. Vijay, “Understanding protein dynamics with l1- regularized reversible hidden markov models,” in Proceedings of the 31st International Conference on Machine Learning (ICML-14), 2014, pp. 1197– 1205. [Online].Available: http://jmlr.org/proceedings/papers/v32/ mcgibbon14.pdf S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, vol. 9, no. 8, pp. 1735– 1780, 1997. [10] F. A. Gers, J. A. Schmidhuber, and F. A. Cummins, “Learning to forget: Continual prediction with lstm,” Neural Computation, vol. 12, no. 10, pp. 2451–2471, 2000. [11] G. Gidofalvi and C. Elkan, “Using news articles to predict stock price movements,” Department of Computer Science and Engineering, University of California, San Diego, 2001. [12] K. Izumi, T. Goto, and T. Matsui, “Trading tests of long-term market forecast by text mining,” in Proceedings of the tenth IEEE Interna- tional Conference on Data Mining Workshops (ICDM-10), 2010, pp. 935– 942. [13] B. Johan and M. Huina, “Twitter mood as a stock market predictor,” IEEE Computer, vol. 44, no. 10, pp. 91–94, 2011. [14] M. andr Mittermayer, “Forecasting intraday stock price trends with text mining techniques,” in System Sciences, 2004. Proceedings ofthe 37th Annual Hawaii International Conference on System Sciences (HICSS- 04), 2004. [15] S. Jianfeng, M. Arjun, L. Bing, J. P. Sinno, L. Qing, and L. Huayi, “Exploiting social relations and sentiment for stock prediction,” in Proceedings of the 2014 Conference on Empirical Methods in NaturalLanguage Processing (EMNLP-14), 2014, pp. 1139–1145. [16] T. Kudo, “Mecab: Yet another part-of-speech and morphological analyzer,” http://mecab.sourceforge.net/, 2005. [17] Z. Wojciech, S. Ilya, and V. Oriol, “Recurrent neural network regularization,” CoRR, vol. abs/1409.2329, 2014. [Online]. Available:http://arxiv.org/abs/1409.2329 [18] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” CoRR, vol. abs/1412.6980, 2014. [Online]. Available: http://arxiv.org/abs/1412.6980 389–396.
Copyright
Copyright © 2024 Aditya Kumar Singh, Anurag Gupta, Faraz Rabbani, Abhijeet Yadav , Mr. Atma Prakash Singh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61815
Publish Date : 2024-05-08
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online