

Ijraset Journal For Research in Applied Science and Engineering Technology
Student Placement Prediction Portal
Authors: Prof. Rupali Jadhav, Sanket Shinde, Shubham Ghadge, Rushikesh Babar, Anurag Bobde
DOI Link: https://doi.org/10.22214/ijraset.2024.62896
Certificate: View Certificate
Abstract
We have acquired knowledge through articles and papers on the use of machine learning to anticipate student placement. In our understanding of the education field, it is evident that placement holds importance, for both students and educational institutions. For students it can provide insights into their likelihood of securing placements enabling them to make informed decisions regarding their career paths. Although we are still in the development phase and continuously gaining insights into this matter, we are confident in our potential as a tool, in creating an accurate, reliable and fair student placement prediction portal. Using machine learning we can analyze data related to student performance placement outcomes and other factors. This analysis helps us identify patterns that can inform predictions, about placement success. To gain insights we employ logic techniques to uncover patterns and trends, within large datasets of student information. This valuable knowledge is then utilized in the development of models. Moreover, we used web development technologies to create a user portal where students can conveniently input their data and receive placement predictions.To analyze this data and predict student placement accurately implementing a machine learning algorithm within the portal is necessary. In my understanding of the education field, it is evident that placement holds importance, for both students and educational institutions.For students it can provide insights into their likelihood of securing placements enabling them to make informed decisions regarding their career paths. Ensuring the security of student data is of importance for the portal
Introduction
I. INTRODUCTION
In the rapidly evolving landscape of education and industry, the process of matching qualified students with appropriate job opportunities has become a pivotal aspect of ensuring a successful transition from academia to the professional world. To streamline this process and enhance the prospects of both students and recruiters, we present the "Placement Selection Portal" – an innovative and comprehensive solution designed to revolutionize the way placements are conducted.
The institutions, in order to offer the best training to their students, follow a decision-making process. To back up the decision-making process, different techniques and methodologies involved in education data mining were used for identifying the knowledge by understanding the student databases. Accuracy of algorithms using Machine Learning.
Logistic regression Requires a large amount of data: Logistic regression requires a large amount of data to train the model. This can be a challenge for placement selection portals, which may not have access to a large dataset of student data. Support vector machine Can be computationally expensive: SVM can be computationally expensive, especially for large datasets. This can be a challenge for placement selection portals, which may need to process a large number of student applications’-nearest neighbors Sensitive to the value of k: The performance of KNN can be sensitive to the value of k, which is the number of neighbors that are used to make a prediction. This means that it is important to carefully select the value of k for the specific placement selection portal.
Use a combination of machine learning algorithms This can help to mitigate the weaknesses of individual algorithms. For example, logistic regression can be used to identify the most important features, while SVM can be used to make the predictions. Use ensemble learning: This is a technique that combines the predictions of multiple machine learning algorithms to make a more accurate prediction.
Use active learning This is a technique that allows the placement selection portal to select the most informative data points to collect. This can help to improve the accuracy of the model by ensuring that the data that is collected is relevant to the task at hand. Use domain knowledge: This is the knowledge of the specific domain that the placement selection portal is operating in. This knowledge can be used to improve the accuracy of the model by helping to select the right features and interpret the results of the model.
II. RELATED WORK
This section summarizes the works in the state-of-the-art related to student placement prediction. In computer science education system programming plays an important role. The students are ranked according to their skill level in programming and aptitude. The software companies also recruit and evaluate employees by their programming skills through some programming tests and contests, etc. A system to predict the placement and ranking of programming contests, which relieves teachers and recruiters from their burden, is proposed in [1]. Educational data mining is mining patterns from educational data [2]. This study includes the interesting research areas viz modeling the students’ learning curve [3] and modeling the learning style [4]. This field also has the allied area of research such as modeling human behavior for predicting the memory process [5]. For taking important decisions or to assist educators, data mining techniques are used to discover useful information in educational environment. For example, a work showing how to predict the bad coding practices of the students is presented in [6]. The authors in [7] present a data mining methodology to analyze relevant information and produce different perspectives about student to monitor their activities. This study applied different classification algorithms on students’ previous and current academic record. Based on that, a model is proposed to find an enhanced evaluation method for predicting the placement for students. In [8], authors propose a placement prediction system to predict the likelihood of a student understudy in getting a job in IT organizations. The scholarly history of the understudy just as their range of abilities like programming aptitudes In [9], authors directed an examination to foresee understudy placement prediction status utilizing two characteristics: area of interest and Cumulative Grade Point Average (CGPA)This system predicts the students to have one of the five placement statuses, viz., dream company, core company, mass recruiters, not Eligible and not interested in placements. This prediction helps the institute to focus attention on students based on their interest.
III. MOTIVATION
Embarking on such a project can be a valuable learning experience and contribute positively to the educational and career development of many students. To help you channel your enthusiasm effectively, here are a few steps to get you started.
IV. OBJECTIVE
The objective of creating a student placement prediction portal is to provide students with insights into their potential job placement opportunities based on various factors such as academic performance, skills, and industry trends. This portal aims to assist students in making informed decisions about their career paths and improve their chances of securing desirable job placements upon graduation.
V. SYSTEM ARCHITECTURE
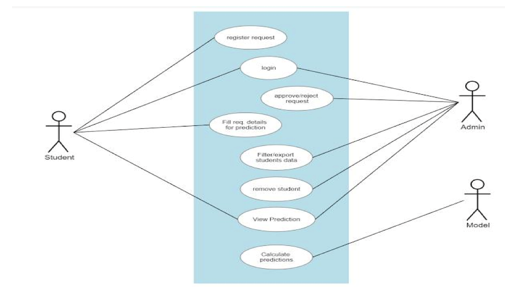
VI. METHODOLOGY
- Data Collection and Preprocessing: Historical placement data is gathered, encompassing factors like academic performance, extracurricular activities, internships, and skill certifications. This data is then meticulously cleaned, formatted, and transformed to ensure its quality and suitability for model training.
- Feature Engineering: Data scientists may create new features from existing data to enhance the model's predictive power. This might involve calculating grade point averages, categorizing skill sets, or deriving engagement scores from participation data.
- Model Selection and Training: Various machine learning algorithms, such as logistic regression, random forests, or support vector machines, are considered. The chosen model is then trained on the prepared data, allowing it to learn the relationships between student attributes and placement outcomes.
- Model Evaluation and Refinement: The trained model's performance is rigorously evaluated using metrics like accuracy, precision, and recall. Based on these evaluations, the model may be fine-tuned or even a different algorithm might be explored to achieve the most accurate predictions.
- Deployment and Monitoring: The final, optimized model is integrated into the portal, enabling students to input their information and receive placement predictions. The portal's performance is continuously monitored to identify potential biases or performance degradation over time, and retraining may be necessary to maintain accuracy.
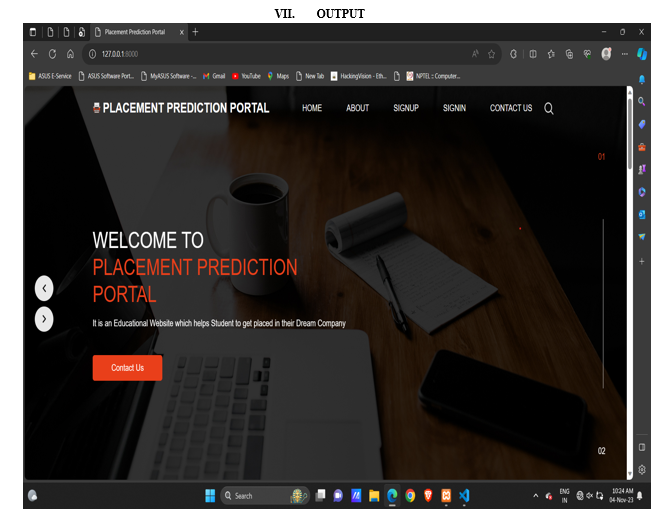
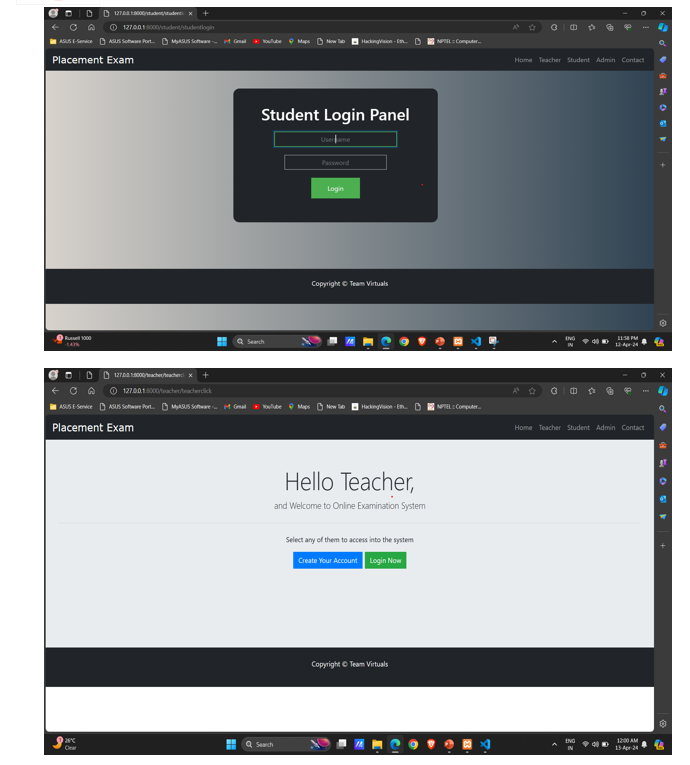
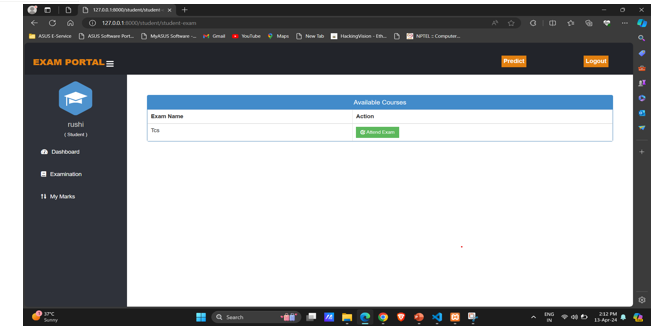
VIII. ADVANTAGES & DISADVANTAGES
A. ADVANTAGES
- It used to Predicting the placement of a student gives an idea to the Placement Office as well as the student on where they stand.
- To predict the eligibility of student for placement so to prepare for only those companies for which the student will actually be eligible for.
- Provide an efficient single point management system which will give all the data of the students of the college at the same place.
- Easily predicts and analyses lot of student data set for predefined classes by using SVM.
B. Disadvantages
- Need to improve to a great extent using this prediction model in all institutions.
- Improvement in User Interface to make user friendly.
Conclusion
The campus placement task is extremely a lot of vital from the organization’s point of view as well as the student’s point of view. The algorithms are applied to the data set and features are selected to build the model. These results recommend that amongst the machine learning algorithm verified. This portal will be helpful to students from the beginning of their Engineering career. This system will reduce the chaos caused at the end of the final year. Students will start improving themselves from initial year itself about their career awareness and learning new skills throughout their graduation course. This system will help them to achieve their dream company as well as they will learn how to overcome their weaknesses.
References
[1] Selvakumar A. Sheik Abdullah, A. Manoj, G. T. Tarun Kishore, “A New Approach to Remote Health Monitoring using Augmented Reality with WebRTC and WebXR”, 22nd International Arab Conference on Information Technology (ACIT), DOI: 10.1109/ACIT53391.2021.9677324, 2022 [2] M. Sandeep, and B.R. Chandavarka, \"Data Processing in IoT, Sensor to Cloud: Survey,\" IEEE Publisher, 12th International Conference on Computing Communication and Networking Technology, IEEE Publisher, Kharagpur, 2021. [3] Sheik Abdullah, A. Manoj, and S. Selvakumar, “A Hybrid Data Analytic Approach to Evaluate the Performance of Stirling Engine using Machine Learning Techniques,” 2021 IEEE Bombay Section Signature Conference (IBSSC), Nov. 2021 [4] L. Al-Shalabi, \"New Feature Selection Algorithm Based on Feature Stability and Correlation,\" IEEE Publisher, Vol. 10, pp. 4699-4713, 2021. [5] Nagamani, K. Mohan Reddy, and S. RaviKumar UmaBhargavi. \"Student Placement analysis and prediction for improving the education standards by using Supervised Machine Learning Algorithms,\" 2020 Journal of Critical Reviews, vol. 7, no. 14, pp. 854-864, Jun. 2020 [6] L. Ming, G. Xue, and H. Liu, “Research on the Application of Big Data in Education Industry,\" International Conference on Information Science and Education\", IEEE Publisher, Sanya, 2020. [7] Manvitha, and N. Swaroopa, \"Campus placement prediction using supervised machine learning techniques,\" 2019 International Journal of Applied Engineering Research, vol. 14, no. 9,pp. 2188-2191, Jan. 2019. [8] Ryosuke Ishizue, Kazunori Sakamoto, Hironori Washizaki and Yoshiaki Fukazawa, “Student placement and skill ranking predictors for programming classes using class attitude, psychological scales, and code metrics”, Research and Practice in Technology Enhanced Learning, Vol. 3, No. 7, 2018.
Copyright
Copyright © 2024 Prof. Rupali Jadhav, Sanket Shinde, Shubham Ghadge, Rushikesh Babar, Anurag Bobde. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62896
Publish Date : 2024-05-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online