

Ijraset Journal For Research in Applied Science and Engineering Technology
Students Attention Monitoring in Learning Environment
Authors: Venkatavinaykumar Vundrakunta, Sithale Shashi Preetham
DOI Link: https://doi.org/10.22214/ijraset.2024.59423
Certificate: View Certificate
Abstract
Educational facts mining is a discipline that specializes in developing techniques to take a look at the specific and large-scale information produced by using educational environments and applying those methods to better recognize the scholars and environments in which they study. Predicting pupil execution is one of the greatest essential issues in scholarly realities mining and is gaining recognition. Student performance prediction attempts to are expecting a student\'s grades before they join in a course or complete an exam. The motive of this newsletter is to provide a scientific overview of the literature on the way to are expecting student performance the use of machine gaining knowledge of techniques and how to use prediction algorithms to identify the maximum essential student records. The have a look at observed that neural networks are the most used classifier for predicting college students\' academic performance and offering the satisfactory outcomes in phrases of accuracy. Additionally, 13% of unsupervised studying used supervised getting to know and fifty nine% of studies used diverse characteristic selection methods to improve the overall performance of gadget mastering fashions. Educational Data Mining (EDM) may be used to become aware of students’ sports, progress, achievements, and typical achievement in their learning. EDM has emerge as very popular in latest years as a mixture of getting to know, analysis, visualization and recommendation that makes the gaining knowledge of procedure coherent and seen. In this paper, an EDM method turned into followed to classify and expect scholar performance the use of system gaining knowledge of techniques. Based on historic instructional records amassed from getting to know control systems (LMS) and training management structures (EMS), a model became created to categorize pupil performance. A version is trained and evaluated with data from 4 special publications. Machine studying algorithms together with Strategic Relapse (LR), Straight Discriminant Investigation (LDA), K-Closest Neighbors (KNN), Choice Tree (DT), Guileless Bayes (NB), help vector gadget (SVM) are discussed. Finally, the Support Vector Machine (SVM) classifier turned into selected for training and validation of the model. Although the proposed model produced excellent outcomes as shown inside the paper, enhancements can be made in future work.
Introduction
I. INTRODUCTION
The vast use of online learning and schooling control structures has resulted within the garage of big amounts of facts. Student interaction with instructional experiences, along with on line checks within the form of boards, lectures, assignments, projects, tests, and many others., gives an possibility to find out valuable and essential facts approximately the traits college students and their next achievements. Student performance is a time period used to measure no longer simplest the performance of students however also the exceptional of tutorial institutions. While a few authors define student overall performance as the price obtained by way of measuring a particular student's academic performance when it comes to coursework, grade factor average (GPA), or very last grades, others define academic performance of the pupil genuinely as a long-term success. To do. -Term goals. Like a college degree or destiny job prospects. The effectiveness of tutorial institutions in reading gathered statistics and predicting pupil overall performance may be very vital and can help pick out college students with poor instructional overall performance at the initial degree of studies, assembly educational requirements, costs high college dropout costs, obtaining a diploma. Can assist hit upon put off and so on. It may be very vital for establishments to understand the capability of individuals and establishments to apply the accrued records to improve mastering effectiveness and academic performance. Educational facts mining (EDM) is a technique that instructional institutions can use to find out hidden styles in academic facts and growth their know-how or predictions approximately destiny pupil performance. When using EDM to find out information from data, machine getting to know (ML) algorithms offer the tools essential to accomplish that. EDM uses an extensive variety of records traits, measurements and forecasting strategies.
Characteristics such as grade point common (GPA) and overall performance on online tests (i.e., evaluation rankings, assessments, and attendance) were generally used to infer or predict students' instructional performance.
Students. Previous educational performance (i.e., high school information) can assist understand scholar performance. . Some authors take into account university front tests to be an essential element. Additionally, student demographics together with gender, age, socioeconomic popularity, own family history, and disability also can effect pupil success. Learning in an online mastering surroundings method that the statistics recorded in the device, along with the variety of lesson accesses, time spent studying and participation in forums, plays an vital position and suitable measures can be taken to enhance student performance. Research. , Psychological attributes inclusive of motivation, student hobby, and personality kind are frequently exciting for research and taken into consideration crucial, but their qualitative nature once in a while makes them hard to research. Different features observed in different studies lead to distinct prediction models to explore student performance. Predicting students' instructional performance entails estimating an unknown score or grade that's generally acquired the usage of numerous category and regression strategies inclusive of decision bushes, synthetic neural networks, Naive Bayes, okay-nearest buddies, and guide vector machines. Data from object-orientated programming publications obtained on the Polytechnic University of Timisoara turned into used to increase a model that predicts college students' academic overall performance and facilitates pick out at-threat students. Their information set covered characteristics which include scholar membership in advanced look at agencies, range of credits earned within the previous 12 months, common hobby grades, quantity of attendance at academic meetings internship activities, average exam ratings and variety of examination attempts. Last. The logistic regression (LR) classifier furnished higher accuracy in predicting students' instructional performance. Support vector machine (SVM) and studying discriminant analysis (LDA) algorithms have proven high schooling accuracy with small dataset sizes for predicting students' academic performance. A dataset of 395 samples from the University of Minho, Portugal, changed into used to expect students' educational success the use of SVM and KNN. The performance of the 2 algorithms become in comparison and it turned into determined that SVM performs better than KNN. Review articles on predicting scholar educational overall performance based on device learning show that neural networks have the highest prediction accuracy (ninety eight%), accompanied by selection bushes (ninety one%), machines with help vectors (eighty three%) and the ok nearest pals (eighty three%). . , and Naive Bayes (seventy six%). In this text, we awareness on predicting college students' academic overall performance using ancient records collected from Belgrade Metropolitan University with the purpose of identifying a appropriate version for predicting student success in a route. The information used in this work represents instructional information accumulated in two item-oriented programming guides and two information era-based guides from the instructional year 2017/18 to 2021/22. Data sets accumulated consist of excessive school scholar GPA, test rankings, homework, initiatives, and sophistication participation, as well as scholar elegance attendance, quantity of failed attempts to bypass final tests and very last grades. Final grades are divided into two classes: individuals who passed the course and those who did no longer. This work presents a comparative analysis of numerous gadget learning calculations including Strategic Relapse (LR), Direct Discriminant Examination (LDA), K-Closest Neighbors (KNN), Choice Trees (DT), Guileless Bayes (NB) and framework getting to be aware. Support vectors (LR). , SVM). This article is coordinated as follows: Section 2 provides an overview of tutorial facts mining strategies. Section three describes the technique used for statistics collection and evaluation. Section four provides and discusses the effects received. Finally, Section 5 concludes the article..
II. PROBLEM STATEMENT
The principal objective of this product is to upgrade the presentation of understudies in their exploration in view of a couple of significant components. Training is something basic for the turn of events and improvement of a country. This allows the population of a rustic to be civilized and behave nicely. Nowadays, new strategies are being developed to extract know-how from educational databases to analyze students' attitudes and behaviors towards training. Analyze records via classifying it along special dimensions and summarizing relationships. This stimulated us to paintings on analyzing the student dataset. Data collection, type and category are achieved manually..
III. LITERATURE REVIEW
- Predicting student overall performance the use of getting to know analytics and information mining techniques: A systematic literature assessment.
Best practices for accomplishing systematic literature evaluations, e.g. PICO and PRISMA, had been applied to synthesize and record key findings. Achievement of mastering outcomes is measured broadly speaking in terms of overall performance elegance class (i.e. Rank) and overall performance rankings (i.e. Grade). Supervised system getting to know and regression fashions are frequently used to rank scholar overall performance. Finally, students' on line learning activities, quarterly evaluation results, and students' instructional feelings were the most sizeable predictors of getting to know effects.
We conclude the survey by means of highlighting a few key studies demanding situations and imparting a summary of important suggestions to encourage destiny paintings on this place.
2. Predicting Student Performance Using Data Mining Techniques
In this technique, a preprocessing step is carried out to the raw information set so that the information mining algorithm is carried out efficiently. Predicting pupil performance will assist you enhance your overall performance. Decision tree, naive Bayes, aid vector gadget, K-nearest acquaintances Did now not have a look at pupil results from distinct angles - Did not speak limitations - Did now not evaluate prediction models - Formulation of properly-defined questions
3. Predicting Students' Academic Performance through Data Mining: Analysis
In this paper, an evaluation is finished between the pupil union regulations set of rules, okay-way clustering algorithm and choice tree. This survey uses diverse characteristics to evaluate pupil performance. Features include in-elegance tests, midterm and final examination grades, homework, lab work, and more. We discuss the information mining method and choice tree-based information clustering technique that allows lecturers to expect pupil performance and instructors to take vital steps to broaden student academic performance. The effectiveness of different determination tree calculations might be dissected founded absolutely on their exactness and the time expected to obtain the tree. The expectations acquired from the machine assisted mentors with distinguishing more fragile understudies and work on their presentation. The evaluation of the outcomes declared via the university is proof of this. Since the application of statistics mining presents many benefits in better education institutions. This is the group quantity, which have to be determined earlier. It is tough to decide the wide variety of clusters while there's little variation inside the data..
4. An exploratory examine of records mining in education: algorithms and methods in exercise.
The results revealed that various algorithms and strategies are utilized in records mining for training. Many of those algorithms are crucial for classifying and manipulating big-scale statistics. The C5.0, C4.Five and K-way algorithms are the strategies highlighted in this examine. In 48% of the articles, those three mining algorithms are normally used to investigate huge-scale facts, specifically within the subject of schooling. The dominant method turned into decision trees, carried out by using forty five% of algorithms, perhaps due to the graphical illustration of know-how, which allows professionals higher interpret clean evidence and establish motive and impact. The preliminary observe supplied offered a well-known context of pupil consequences that lacked crucial information. The full consequences of the research have not been launched.
5. Predicting Students' Scholastic Execution Utilizing Backing Vector Machine and Irregular Woodland
Exploratory results of SVM and RF calculations applied to both datasets show that the exactness can arrive at 93% on account of twofold class, even as in relapse the least RMSE is 1.Thirteen inside the situation of the RF. It is easier and quicker to are expecting the magnificence of the take a look at dataset. It additionally works nicely in multi-class prediction, SVM is also known to be a negative estimator, so the probabilistic outcomes of the prediction must not be considered very crucial.
6. A Relative Report to Foresee Understudy Execution Utilizing Instructive Information Mining Methods
The results showed that first-semester students' attendance and GPA accomplished better than all function selection strategies and the Bayesian community achieved higher than the decision tree.
This works better in conditions with specific enter variables than in situations with numeric variables. If a small sample is analyzed, the statistics may be overclassified or under classified.
IV. OBJECTIVE
The essential objective of this application is to upgrade the presentation of understudies of their exploration essentially founded on a few significant components. Schooling is a fundamental component for the turn of events and improvement of a country. This allows the occupants of a country to be cultivated and behave properly.
Nowadays, new strategies are being advanced to extract expertise from instructional databases to analyze students' attitudes and behaviors towards training.
Analyze statistics by way of classifying it along specific dimensions and summarizing relationships. This stimulated us to work on analyzing the scholar dataset. Data series, classification and type are performed manually.
V. GOALS
There are many open source machine mastering frameworks for assessment and analysis. For this article, we can awareness on two transformer models. Transformer [6] is a deep studying model that uses an attention machine to one by one measure the significance of each detail of the input records. Its major applications are natural language processing (NLP) and laptop imaginative and prescient (CV). This study will focus on NLP transformers and their use in binary text class for open supply device studying frameworks. The category falls under the class of supervised cash laundering. This take a look at will now not attention on 12ML unsupervised class and will not consciousness on different kinds of classification in system studying together with multi-elegance/multi-label/imbalanced classification or regression.
VI. EXISTING SYSTEM
Currently, the existing machine simplest considers performances with the intention to assist us compare a scholar's performance, which isn't always enough for the system. We don't have any machine to help us determine what's effective and what's undesirable. Currently, since the gadget simplest takes overall performance into consideration, it is not enough to have a device that may assist us predict a student's overall performance. We haven't any gadget to assist us stability overall performance and undesirability. The drawback of the existing machine is that scholars lose unwanted data due to the fact the system does not take a look at students' social data.
Disadvantages:
- Existing framework miss the unwanted information for the understudies.
- Furthermore, It may not actually take a look at the social information for the understudy.
VII. PROPOSED SYSTEM
The target of this works of art is to grow an acknowledge as obvious with model utilizing records mining systems that removes significant records so the ongoing schooling contraption can embrace it as an essential control gadget. The proposed machine utilizes scholastic insights mining techniques to survey execution and distinguish unwanted ways of behaving. Information mining in education is used for diverse packages such as student overall performance, attendance, group of workers remarks, extracurricular sports, bullying, and pressure. Data mining strategies are used to identify scholar performance using K-Means and KNN algorithms. The goal of this paintings is to expand a believe model by way of extracting important statistics the usage of information mining techniques, with the goal that the contemporary training machine can get them as a key functional instrument. Educational records mining methods are used to estimate traditional machine overall performance and become aware of unwanted disasters. In schooling, information mining is used for a diffusion of sports much like academic overall performance, which include grades, attendance, and body of workers remarks, implicit conditioning, irregularities, and stress. Data mining techniques related to pupil performance utilizing K-Means and KNN calculations. The upside of the proposed contraption is that the informative data set comprises of gainful information for assessing understudies. Information mining methods are exceptionally valuable in ordering instructive data sets and help us examine a scholar's performance and unwanted behaviours.
Advantages:
- Instructive data set contain the valuable data for Assessing Understudies.
- The information mining methods are more useful in grouping instructive data set and help us in assessing the exhibition and unwanted way of behaving of an understudy.
VIII. SYSTEM ARCHITECTURE
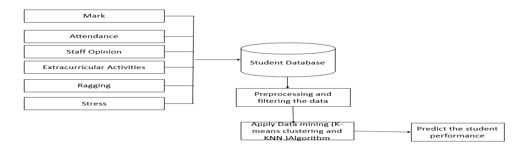
IX. MODULE AND DISCRIPTION
The accompanying modules are utilized in this task:
- Information Assortment: In this module, Understudy information's will be gathered from the committee. Understudy's information like imprint, participation, staff assessment, Web-based entertainment, extracurricular exercises, Ragging and stress.
- Preprocessing: Information pre-handling is finished to eliminate the inadequate loud and conflicting information. Information should be pre-handled prior to involving in point determination task.
- Grouping Module: The information digging ways utilized for relating the exhibition of the student utilizing Credulous Bayes and KNN calculations. These two calculation's recognizes and examinations the presentation of the student.
- Prediction: In this module, to visualize the student execution grounded upon understudy mark, participation, staff assessment, Web-based Entertainment, extracurricular exercises, Ragging and stress.
X. SYSTEM REQUIREMENTS
Hardware Requirements:
System - Pentium-IV
Speed - 2.4GHZ
Hard disk - 40GB
Monitor - 15VGA color
RAM - 512MB
Software Requirements:
Operating System - Windows XP
Coding language – Java
IDE - Net beans
Database -MYSQL
XI. PROPOSED ALGORITHMS
K-Nearest Neighbor (KNN)- K-NN is a form of case- grounded literacy, also known as lazy literacy. In this method, the function is only approached locally, and all calculations are left until the bracket. The k-NN calculation is among the least complex of all AI calculations. The neighbors are taken from a bunch of items for which the class (for k-NN section) or the item property estimation (for k-NN retrogression) is known.
Stage 1 Start
Stage 2 Info D = (x1, c1),..., (xN, cN)
Stage 3 x = (x1... xn) new case to be grouped
Stage 4 FOR each marked case (xi, ci) compute d (xi, x)
Stage 5 Request d (xi, x) from littlest to loftiest, (I = 1... N)
Stage 6 select the K closest cases to x Dkx
Stage 7 Relegate to x the most regular class in Dkx
Stage 8 END
Naive Bayes Algorithm
This is an incidental mode essentially founded on Bayes' hypothesis with the possibility of freedom among indicators. Essentially positioned, a Guileless Bayes classifier expects that the presence of a particular calculate a class isn't connected with the presence of another point. For example, a natural product might be viewed as an apple in the event that it is red, round, and measures around 3 creeps in circuit. Assuming that those characteristics depend on one another or at the truth of different qualities, then those characteristics add to the open door that this natural product is an apple that is the reason it is alluded to as "innocuous." How about we perceive this with an occurrence. Beneath I even have a tutoring dataset of precipitation and the comparing objective variable "play" (which shows the chance of playing). Presently, players ought to qualify principally founded on downpour circumstances whether they play or presently not. Kindly consent to the ensuing strategy to place in compel it. Step 1: Make a frequency desk from the dataset. Stage 2 Make a responsibility table in light of probability of weighty playing = 0.29 and plausibility of playing 0.Sixty four. Step 3: Determine the posterior probability of each elegance by employing a straightforward Bayesian equation. The absolute last class with the best capacity is plants development.
XII. RESULT AND DISCUSSION

As depicted in Figure 1, when the student is paying attention in the learning environment, the system doesn’t give any stimuli but as depicted in Figure 2 when the student is not paying attention, the system notifies the lecturer about the student / students who are not listening to them so that he / she can retain their attention back. Hence, this system can effectively monitors students attention in any learning environment for quality and uninterrupted learning.
Conclusion
In this paper, an organizing trademark is utilized on the researcher data set to foresee researcher division dependent absolutely upon past results. Since different strategies are utilized for information grouping, the Credulous Bayesian Classifier and Weighted Guileless Bayesian Classifier are utilized. Data which incorporate participation, in-class checks, sheets, and mission grades were gathered from the student\'s former data set to are anticipating generally execution on the stop of the semester. This notice will help academicians and teachers to improve student segmentation. This examine will serve to lessen failures in next semester\'s exams, take concrete measures and perceive those among academics who require unique attention. This will help academicians enhance their educational performance, so as to in the end lead to higher consequences of their final assessments. With this discount in strain, the suicide price amongst academics will also lower. This will make a contribution to the improvement of our U.S.A. With the aid of imparting excellent and powerful leaders to the U. S. A.
References
[1] B.K. Bharadwaj and S. Pal. \"Data Mining: A prediction for performance improvement using classification\", International Journal of Computer Science and Information Security (IJCSIS), Vol. 9, No. 4, pp. 136-140, 2022. [2] Erkan Er. \"Identifying At-Risk Students Using Machine Learning Techniques\", International Journal of Machine Learning and Computing, Vol. 2, No. 4, pp. August 2020. [3] S. Kotsiantis, I.D. Zaharakis, and P. Pintelas, \"Assessing Supervised Machine Learning Techniques for Predicting Student Learning Preferences\" [4] M.Durairaj, C.Vijitha .Educational Data mining for Prediction of Student performance Using Clustering Algorithms. The data mining techniques are more helpful in classifying educational database Which contain the useful information for predicting a student\'s performance. [5] Kin Fun Li, David Rusk and Fred Song.Predicting Student Academic Performance,The performance predictors, if identified, can then be used effectively to formulate corrective action plans to improve the attrition rate. [6] Achumba, I. E. and Azzi, D. and Dunn, V. L. and Chukwudebe, G. A. ”Intelligent Performance Assessment of Students’ Laboratory Work in a Virtual Electronic Laboratory Environment.” IEEE Transactions on Learning Technologies, vol. 6, pp. 103- 116, Apr 2020. [7] Chen, Hsuan-Hung and Chen, Yau-Jane and Chen, Kim-Joan. ”The Design and Effect of a Scaffolded Concept Mapping Strategy on Learning Performance in an Undergraduate Database Course” IEEE Transactions on Education, vol. 56, pp. 300-307, Aug 2021. [8] Doctor, Faiyaz and Iqbal, Rahat. ”An intelligent framework for moni- toring student performance using fuzzy rule-based Linguistic Summari sation.” 2012 IEEE International Conference on Fuzzy Systems, pp. 1-8, Jun 2019. [9] Barney, Sebastian and Khurum. ”Improving Students with Rubric-Based Self-Assessment and Oral Feedback”, IEEE Transactions on Education, vol. 55, pp. 319-325, Aug 2022. [10] Barney, Sebastian and Khurum. ”Improving Students With Rubric Based Self-Assessment and Oral Feedback”, IEEE Transactions on Education, vol. 55, pp. 319-325, Aug 2020.
Copyright
Copyright © 2024 Venkatavinaykumar Vundrakunta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59423
Publish Date : 2024-03-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online