

Ijraset Journal For Research in Applied Science and Engineering Technology
Study of Aerial Image Classification
Authors: Vaishnavi Deulkar, Shashwat Kale, Yashsingh Thakur, Prof. Anirudh Bhagwat
DOI Link: https://doi.org/10.22214/ijraset.2024.60424
Certificate: View Certificate
Abstract
Classifying images captured through remote sensing is necessary for various reasons, including monitoring the environment and assessing agriculture. The progress in this field has been greatly enhanced by the integration of advancements in machine learning, especially deep learning, and also accessibility of high-definition images obtained through remote sensing. CNNs are now necessary instruments for precise recognition and classification of objects in aerial imaging. These models use convolution and pooling operations to capture local patterns and relationships, enhancing image classification accuracy. This review paper presents a comprehensive look at the most recent techniques for categorising remote sensing images. It emphasises the significance of accurate classification in the constantly evolving contemporary society and investigates new progress made possible by deep learning methods. The article explores problems in pinpointing unique and important areas in remote sensing images and illustrates how deep learning models tackle these problems through comprehending relationships among objects and other elements in the scene. The article assesses the advantages and disadvantages of various techniques in relation to accuracy, computational efficiency, and scalability through a comparison between traditional methods and deep learning-based methods.
Introduction
I. INTRODUCTION
The categorization of remote sensing pictures is crucial in a range of areas like overseeing the environment, evaluating agriculture, and planning land usage. Recently, the combination of machine learning, specifically deep learning, and the easy access to high-quality remote sensing images has led to substantial advancements in this field. CNNs have played a crucial role in improving accurate object detection and classification in satellite imagery. Due to rapid technological advancements and increasing demand for precision and effectiveness, it is crucial to understand and utilise advanced methods for analysing remote sensing data. The integration of deep learning techniques with satellite imagery has created possibilities for enhancing classification precision, facilitating in-depth and intricate data analysis within the images.
With this background in mind,the goal of this review article is to offer a thorough summary of the advanced techniques used in remote sensing aerial image classification. It explores the importance of precise categorization in tackling present-day issues like environmental shifts and resource supervision. The article examines the recent progress achieved through deep learning methods, with a particular emphasis on how CNNs can be used with remote sensing data to detect complex spatial patterns. Challenges linked to classifying remote sensing images, like extracting significant and non-overlapping areas from intricate images, are emphasised. The conversation highlights how deep learning models tackle these issues by capturing contextual relationships between objects and other elements in remote sensing imagery effectively.
A crucial part of this review involves comparing and assessing the pros and cons of traditional methods and deep learning-based approaches. This analysis examines classification accuracy, computational efficiency, and scalability, offering valuable information for researchers and practitioners looking to understand various classification techniques. Moreover, the article discusses major obstacles in the field, such as lack of data and the necessity for clear models in remote sensing tasks. It also delves into possible future research paths, highlighting the importance of combining remote sensing data with other sources and improving the generalisation abilities of classification models. In conclusion, this introduction prepares for a detailed examination of remote sensing aerial image classification by highlighting the revolutionary effects of deep learning methods and offering a guide to grasp the current state, obstacles, and future prospects in this swiftly developing area.
II. RELATED WORK
- Classifying Satellite Images Land Cover Through Contextual Data
The article presents a new approach for Categorising land cover in high-resolution satellite pictures, with a specific emphasis on urban regions. Land cover classification is essential for different purposes like urban planning, environmental monitoring, and disaster management.
Conventional classification techniques based on pixels frequently face challenges accurately defining land cover categories in intricate urban environments because of spectral likeness and spatial diversity. Dealing with these difficulties, the proposed method, Iterative Context Forest (ICF), utilises advanced semantic segmentation methods from computer vision to improve classification precision by integrating contextual details among adjacent pixels.
The main difficulty in land cover classification is accurately assigning pixels to specific land cover categories like buildings, roads, vegetation, and water bodies. This challenge is especially difficult in cities, where the combination of different types of land cover nearby and the complicated urban infrastructure creates major obstacles. Traditional approaches that depend only on spectral data frequently struggle to distinguish small variations between categories, resulting in incorrect categorizations and lower precision.
The ICF method being proposed aims to overcome these challenges by continuously improving the classification process using contextual information gathered from nearby pixels. The algorithm enhances the differentiation between land cover classes with similar spectral signatures by taking into account the spatial relationships between neighboring pixels. Furthermore, the approach combines various types of data such as RGB, NIR, Utilizing nDSM from LiDAR and NDVI for enhanced classification outcomes by gathering extra data.
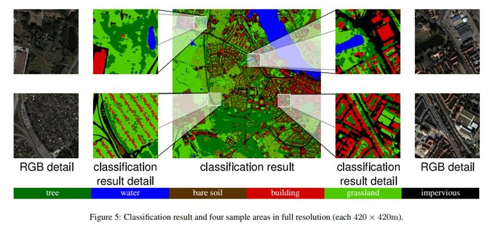
In general, the paper outlines a strong and adaptable method designed specifically for the difficulties found in city settings. The suggested approach enhances classification accuracy and advances the state-of-the-art in automated land cover mapping by utilizing contextual features and leveraging multi-channel data. This has consequences for a variety of uses, such as urban planning, natural resource management, and climate change research, where precise land cover data is crucial for making informed decisions and creating policies.
2. Increased diversity leads to improved results: The combination of multimodal deep learning with remote sensing imagery classification.
The research paper describes the MDL-RS framework used to classify remotely acquired images. The framework aims to address the limitations of traditional classification techniques that often rely on specific modalities such as hyperspectral, multispectral, LiDAR, or SAR data. The goal of the MDL-RS framework is to improve classification accuracy by incorporating multiple modalities simultaneously, particularly when individual modalities have difficulty providing sufficient distinctive information.
Essential elements and impacts of the MDL-RS framework consist of:
a. MDL-RS is a comprehensive deep learning framework for image classification in remote sensing, incorporating different modes of data. It consists of two main modules: Extraction Network (Ex-Net) and Fusion Network (Fu-Net). Ex-Net gathers attributes from different modalities, while Fu-Net combines these attributes to generate final classification results
b. fusion, late fusion, encoder-decoder fusion, and cross fusion. These blending techniques enable the effective merging of data from different sources at different locations in the network.
c. Integration Modules for Connect and use : Five combined modules are explored and developed in the MDL-RS framework. These modules aim to tackle the difficulties of combining and representing multimodal data. Traditional fusion methods like concatenation- based fusion are included, alongside newer techniques like encoder-decoder fusion and cross fusion.
d. Improved Feature Representation: The framework highlights the significance of acquiring concise and informative feature representations from different modalities. This is done by updating network parameters interactively and exploring cross-modal dependencies.
e. Network Architecture: MDL-RS offers a fundamental network architecture for classifying multimodal RS images. It can be easily tailored with different fusion modules and adapted to various fusion strategies.

The article presents a MDL framework for pixel-level RS image classification using multimodal data, incorporating Ex-Net and Fu-Net subnetworks. Various fusion techniques are investigated for combining "what", "where", and "how" information using FC-Nets and CNNs as feature extractors for pixel-based and spatial-spectral classification. The MDL-RS framework tackles the CML problem alongside MML by including fusion components such as early, middle, late, and en-de fusion, as well as introducing a new cross fusion approach. Results from experiments on two RS datasets demonstrate that MDL-RS networks are more effective than single modality networks, and fusion based on compactness is more successful than fusion based on concatenation, particularly for CML. The research examines different methods such as HS-LiDAR and MS-SAR, as well as fusion modules such as early, middle, and late fusion, determining that middle fusion is the most successful. The fusion strategy based on compactness, which includes within-language fusion and cross-language fusion, outperforms concatenation-based fusion for integrating multimodal features in MML and CML situations. Nevertheless, the accuracy of categorising RS images depends greatly on the quality and quantity of samples, especially for DL models. In order to overcome performance limitations in MDL, upcoming research will investigate methods like weakly-supervised or self-supervised techniques with improved fusion modules.
3. Approaches for Remote Sensing Image Classification Using Active Learning
The research presents two active learning techniques aimed at improving the selection of training samples for classifying remote sensing images. The objective is to enhance the efficiency of the classification process by decreasing the need for manually labelling training data. The algorithms are designed to select the most useful pixels for labelling in a systematic manner based on pre-established guidelines. After marking these pixels, they will be used to improve the classifier, leading to a gradual increase in classification accuracy.
The original algorithm, MS-cSV, builds upon margin sampling (MS) by considering the distribution of candidates within the feature space. It aims to ensure selecting just one candidate from every region in the feature space, preventing duplicate samples and improving the speed of the algorithm.
The EQB algorithm, which is the second one, enhances the query-by-bagging method by including an entropy-driven heuristic. This heuristic evaluates the inconsistency among diverse classifiers within the committee based on the entropy of the predicted label distribution. Candidates exhibiting high levels of entropy are perceived as being inadequately addressed by the existing classifier, and are therefore given priority for being added to the training set.
Different remote sensing datasets, such as high resolution optical imagery and hyperspectral data, are used to assess the proposed algorithms. Experimental findings show that the methods are efficient in decreasing the needed training samples, while still upholding a high classification accuracy. The study also evaluates the suggested algorithms against current cutting-edge active learning techniques, emphasising their benefits.
In general, the study helps tackle the issue of selecting training samples efficiently in remote sensing image classification, especially in complicated environments like urban areas. The suggested algorithms show potential in enhancing the flexibility and efficiency of current active learning techniques in this field.
To summarise, this article presents a specific active learning approach designed for classifying remote sensing images. Two new techniques, MS-cSV and EQB, are introduced to enhance the efficiency and flexibility of current active learning methods. These techniques enable the predictor to choose the most beneficial pixels to improve its performance, thereby decreasing the requirement for extensive manual labelling and enhancing computational efficiency.
The use of MS-cSV and EQB on different datasets, such as VHR QuickBird images and AVIRIS hyperspectral images, proves their reliability and efficiency. These methods demonstrate similar results as traditional methods but require much less training data, showcasing their efficient use of resources. Additionally, MS-cSV and EQB demonstrate faster convergence to optimal outcomes in contrast to conventional random sampling techniques. EQB demonstrates outstanding performance on all datasets, highlighting its versatility and effectiveness in various situations.
Although MS-cSV enhances the effectiveness of current techniques, additional adjustments are necessary to address scenarios involving a combination of different classes. Moreover, the proposed methods show resilience in achieving high accuracies, tackling challenges associated with very small objects in VHR imagery.
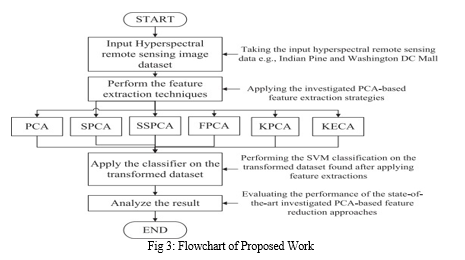
4. Feature reduction through PCA for Classifying Hyperspectral Remote Sensing Images
This research examines various techniques to decrease characteristics and enhance the classification precision of hyperspectral remote sensing images (HSIs), which typically contain multiple consecutive narrow spectral bands. Because HSI data is complicated and it is challenging to process the entire dataset, feature reduction techniques are required for practical use. The article examines two main methods for reducing features: feature extraction and feature selection.
Methods for extracting features concentrate on extracting essential information from the original HSI data by transforming it into a lower-dimensional space. The article explores various linear and nonlinear versions of Principal Component Analysis (PCA), including PCA, Segmented-PCA (SPCA), Spectrally Segmented PCA (SSPCA), Folded-PCA (FPCA), Minimum Noise Fraction (MNF), Kernel PCA (KPCA), and kernel Entropy Component Analysis (KECA). The effectiveness of these methods is assessed for classifying HSI, especially when using an SVM classifier.
The study findings from utilising Indian Pine farms and urban Washington DC Mall hyperspectral images suggest that feature extraction methods can improve classification accuracy and reduce computational complexity. MNF has the highest classification accuracy, whereas FPCA is recognized for its decreased space and time complexity. Additionally, the article examines the limitations of traditional PCA and introduces new techniques like SSPCA and KECA in order to address specific challenges in HSI classification.
In general, the research offers valuable advice to remote sensing and image analysis professionals on choosing feature reduction methods for HSI classification tasks.
5. MMDL-Net: A Model for Classifying Remote Sensing Images with Multiple Bands and Labels
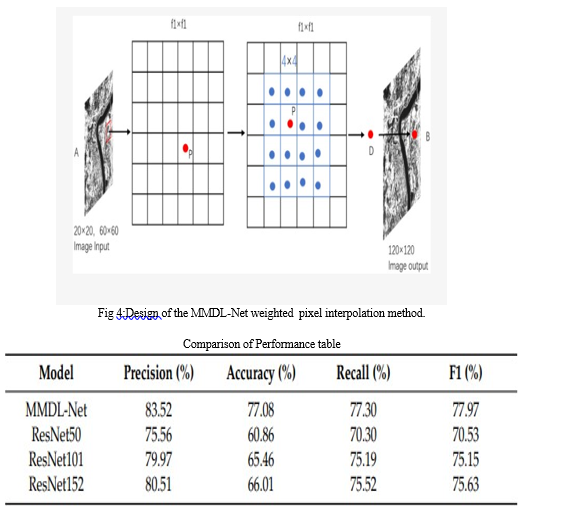
The study detailed the development and assessment of the MMDL-Net model for classifying high-resolution remote sensing images. Initial precision scores from the ResNet50 model and the subsequent improvement achieved with MMDL-Net were highlighted, indicating a significant performance boost. Comparative experiments involving various deep learning architectures, including ResNet variations and MMDL-Net, were meticulously conducted to evaluate their efficacy. The findings revealed that while deeper ResNet models exhibited some performance gains, MMDL-Net consistently outperformed them, underscoring the inadequacy of network depth alone in addressing the complexities of remote sensing images. MMDL-Net's superiority was attributed to its tailored adaptations for multi-band, multi-label classification tasks. Evaluation results demonstrated substantial precision enhancements across most categories compared to standard ResNet models, with MMDL-Net showcasing exceptional proficiency in discerning intricate landform features.
Moreover, the study emphasised the practical significance of accuracy in remote sensing image classification across diverse domains. It elucidated how precise classification could offer valuable insights for development that can be sustained over time, management of land, and efforts to conserve nature. The research found that the MMDL-Net model is a useful method for accurately categorising images captured through remote sensing technology, providing significant enhancements to deep learning model optimization in this field. In general, the study offered a thorough insight into how MMDL-Net handles multi-band, multi-label remote sensing image classification tasks, showcasing its capabilities and benefits and setting the stage for future progress in this area.
6. Universal Domain Adaptation for the Classification of Scenes in Remote Sensing Images
The research introduces a specialised Universal Domain Adaptation (UniDA) framework designed for remote sensing image scene classification, tackling the limitations of current Domain Adaptation (DA) techniques. In the traditional sense, DA techniques depend on prior understanding of the relationship between label sets from source and target domains, making them unsuitable for situations with limited access to source data because of privacy issues. The study's introduction of UniDA removes the necessity of prior knowledge, increasing its relevance to real-life scenarios.
Additionally, the study presents a new UniDA approach that is appropriate for situations where the original data is not accessible. The model structure consists of two primary phases: the Source Data Generation (SDG) stage and the Model Adaptation (MA) stage. During the SDG phase, synthetic source data is created by predicting the conditional distribution of source data using pretrained models and generating it according to class separability in the source domain. Afterwards, in the MA phase, a distinct transferable weight method differentiates between common and individual label groups in every area, aiding in efficient adjustment and identification of unfamiliar samples.
The empirical results highlight the effectiveness and feasibility of the suggested UniDA framework for remote sensing image scene classification, regardless of the presence of source data. This study helps progress DA methods and offers important information on the obstacles and answers linked to remote sensing image study. The study highlights the importance of coherence between the two summaries in addressing real-world challenges in remote sensing classification, as well as the methodological contributions in developing practical and effective UniDA solutions.
7. A new method using Deep Learning for classifying Remote Sensing images to map land cover in developing nations.
Mapping land cover is essential for different uses such as urban growth, disaster tracking, and ecological supervision. Nevertheless, real-time monitoring is required because of changes in land cover caused by population growth and other factors. Remote sensing technology, utilising satellites, offers an inexpensive way to map global land cover changes. Conventional approaches to analysing satellite images are not precise or effective. Convolutional neural networks (CNNs) have become a strong answer for image classification tasks, especially in the field of deep learning. Nevertheless, obtaining large datasets for training CNNs is difficult, particularly for remote sensing data in developing nations. Transfer learning has been suggested as a solution to this problem by utilising pre-trained models designed for natural image datasets in remote sensing assignments. Recent research has demonstrated positive outcomes in applying transfer learning for classifying remote sensing images, however, obstacles persist due to distinct domains between natural images and remote sensing information, resulting in diminished overall performance in generalisation. Various methods are being investigated to enhance heterogeneous transfer learning in this scenario. The main goal was to create a CNN framework that could accurately classify a RS test dataset that was not part of the training data. Furthermore, our goal was to evaluate the model's capacity in categorising pixels in medium resolution remote sensing imagery into five primary land cover categories: Barren land, urban areas, bodies of water, agricultural land, and wooded areas. In order to accomplish this, we utilised transfer learning (TL) by fine-tuning a pre-trained ResNet-50 model on the EuroSAT dataset, which is a vast remote sensing image dataset.
We utilised two data sets: EuroSAT and Nig_Images. EuroSAT consists of categorised and geographically referenced patches of remote sensing images covering 34 countries in Europe. We modified the similar land cover categories in EuroSAT to align with our specified classes, with 10 metres per pixel resolution for each class patch.
Design of the model framework.
- Transfer Learning: ResNet-50 was chosen as the pre-trained model and adjusted by resizing the final layer to align with the total land cover classes.
- Extra layers were introduced in the ResNet-50 base model, including a max-pooling layer, two fully connected layers, and a dropout layer. The max-pooling layer condensed the outputs of the previous convolution layer, while the fully connected layers decreased the inputs to match the number of classes through the use of a softmax activation function. Dropout layer helps to avoid overfitting.
- Ensemble Learning involves merging model weights from various training dataset subsets to enhance generalisation performance.
Model Implementation Details

Utilised Keras for implementing the model, starting off with the pre-trained ResNet-50 model and configuring it with appropriate hyperparameters. The model was constructed using an RMSprop optimizer, a batch size of 32, ReLU activation function, cross-entropy loss function, and a learning rate set at 0.0001. We evaluated how well the model performed using a validation set and made changes to the hyperparameters as needed. The model's classification accuracy was assessed by testing on both the EuroSAT and Nig_Images test datasets.
Overall, our proposed CNN model showed promising results in classifying satellite imagery data, particularly when combined with image augmentation, fine-tuning, and ensemble learning techniques. However, challenges remain when trying to apply these discoveries to various datasets, especially those from developing countries, highlighting the need for further research in this particular area.
8. Study on classifying land cover using an enhanced U-net network with multiple remote sensing data sources.
Remote sensing images have become increasingly important for detecting resources and conservation efforts in recent years. However, using only one type of image like optical or SAR may not provide accurate land cover classification. The widely used U-Net network for this task has constraints such as poor precision and incorrect classification. To overcome these issues, this study proposes an enhanced approach combining optical and SAR images and modifying the U-Net architecture. Changes include using a convolutional block attention mechanism and adjusting activation functions. This approach improves terrain extraction, reduces network parameters, and ensures better training. Experimental results show significant accuracy improvements compared to traditional U-Net methods.
This study introduces an advanced U-Net network model tailored for land cover classification using remote sensing data, particularly focusing on the Autonomous Region. The region's geographical and climatic characteristics, such as its transitional climate and strategic location, make it ideal for development of the economy and building of an ecological civilization. The study employs Sentinel- 1A intensity data and Level-2A Sentinel-2A data for SAR and optical remote sensing, respectively. Data preprocessing requires multiple stages, including processing multiple viewpoints and calibration of radiometric measurements, with a particular emphasis on eliminating topographic distortion using DEM data. The synthesised RGB images from both datasets are merged after ensuring compatibility in resolution and projection coordinates.
The dataset construction involves classifying eight terrain types, including buildings, water bodies, roads, and cultivated land, using images cropped from the study area. To enhance the dataset's size and balance the distribution of terrain types, data augmentation techniques are applied, resulting in 2670 images divided into training, validation, and test sets. The enhanced U-Net network model introduces improvements such as replacing pooling layers with convolution operations, incorporating the Convolutional Block Attention Module (CBAM) for enhanced terrain extraction, and utilizing the Leaky ReLU activation function to mitigate gradient death issues during training.
Furthermore, ablation tests are performed to assess the effectiveness of these improvements, comparing various schemes based on the traditional U-Net architecture. Results indicate that Scheme IV, which combines all enhancements, outperforms others in respect to their accuracy in categorization and mean Intersection over Union (mIoU) values across the Sentinel-2, Sentinel-1, and combined datasets. The study concludes that the proposed enhanced U-Net model significantly improves land cover classification accuracy, particularly benefiting from the collaborative utilization of the CBAM attention mechanism, convolutional downsampling, and Leaky ReLU activation function.
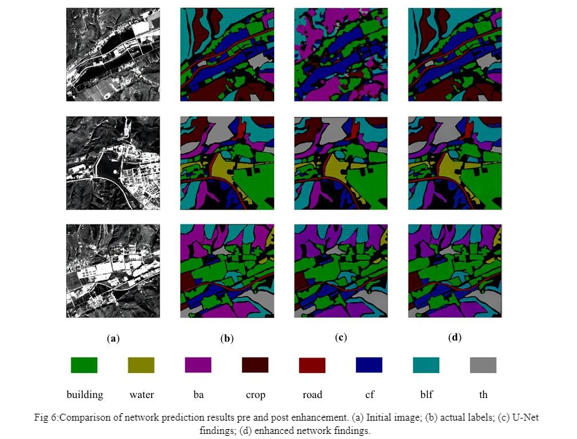
Additionally, it substitutes max pooling with convolution for downsampling, reducing parameters and computations. Experimental results show superior performance across three datasets, indicating the effectiveness of these modifications. Future research directions include exploring fusion of high- resolution images, diverse terrain types, and optimizing network depth and efficiency for improved classification accuracy and applicability.
9. RSI-CB: An Extensive Classification of Images from Remote Sensing Benchmark Utilising Crowdsourced Data
Categorizing images taken through remote sensing technology is a crucial task in the field of remote sensing image processing, attracting a lot of research focus.
Deep Convolutional Neural Networks (DCNNs), led by groundbreaking accomplishments such as AlexNet in the ImageNet Challenge, have transformed computer vision tasks, including image classification, face recognition, video analysis, and object detection. Especially, ResNet's advancement in outperforming humans in the ImageNet1000 Challenge emphasized the revolutionary ability of DCNNs. This successful integration of DCNNs into remote sensing image processing has pushed the boundaries of the field. The universal approximation capabilities, use of databases like ImageNet, and computational power, especially with GPUs, contribute to the success of DCNNs. These networks are skilled at acquiring efficient feature representations from large training datasets, reducing overfitting and improving generalization. However, the absence of a universally accepted, widely-used measure for assessing different image classification algorithms is impeding progress in remote sensing image processing. Several guidelines have been implemented to address this gap. The NLCD, UC-Merced dataset, SAT-4, SAT-6, Terrapattern, AID, and NWPU-RESISC45 are recognized benchmarks, each having distinct characteristics and constraints. Acknowledging the importance of a detailed, thorough benchmark assessment, this paper presents a new approach that utilizes crowdsourced geographical information. By utilizing points of interest (POIs) sourced from OpenStreetMap (OSM) in conjunction with remote sensing imagery from Google Earth and Bing Maps, the Remote Sensing Image Classification Benchmark (RSI-CB) is developed. RSI-CB includes 35 subclasses within six categories, providing a varied and thorough dataset for creating and assessing image classification using remote sensing algorithms.
The Classification of Images from Remote Sensing Benchmark (RSI-CB) for deep learning models like DCNNs must adhere to certain criteria:
- Scale of Benchmark: RSI-CB should be sizable to accommodate the complexity of DCNN models and their ability to learn from large datasets. A more extensive dataset helps capture the diverse characteristics of the data distribution, enhancing model robustness and generalisation.
- Object Diversity: The dataset should encompass diverse objects within each class, including variations in size, shape, perspective, background, lighting, and color. This diversity ensures that the model learns both unique and general characteristics of objects, thus improving classification accuracy.
- Category Differences: There should be significant differences between object categories to facilitate accurate classification. Increasing the number of images within categories with pronounced differences enhances the likelihood of independent feature distributions, thereby boosting classification accuracy.
To meet these requirements, RSI-CB follows specific construction principles:
- Each category is rich in data, with approximately 690 patches per category.
- Object category selection improves benchmark diversity by combining the hierarchy mechanism of ImageNet with the Chinese national land-use classification standard.
- Objects are easily identifiable to prevent semantic divergence in images.
- Every category shows differences in imaging angles, dimensions, forms, and colors to enhance sample variety, thus enhancing model generalisation and resilience.
- Pictures are gathered from large cities around the world and the areas nearby to maintain a balanced distribution of space.
The test methods involved comparing handcrafted feature models with DCNN models using RSI-CB. Handcrafted features included SIFT, Color Histograms, LBP, and GIST, while DCNNs included AlexNet, VGG-16, GoogLeNet, and ResNet. DCNN models were trained from scratch due to dataset differences and scalability. Transfer performance testing assessed model adaptability to other databases like UC-Merced. Data organisation included random selection for training, validation, and testing, along with data augmentation. Parameter settings varied for handcrafted features and DCNN models. Evaluation methods included overall accuracy and confusion matrix analysis. Handcrafted features showed limitations in complex object recognition, while DCNN models demonstrated strong performance, especially with larger datasets like RSI-CB. Model transfer capability was assessed using common categories between RSI-CB and UC-Merced. The study concluded that RSI-CB, based on data gathered from a crowd,offers valuable insights for remote sensing benchmarking and can be expanded with increasing crowdsourced data availability.
10. Classification of Remote Sensing Images in the Planting Area
This study is centred on overcoming the difficulties of categorising study regions using high-definition optical images captured remotely by sensing technology. Usually, high-definition images are restricted in their coverage because of cloud cover and constraints on the revisit period, thus making it challenging to acquire a complete set of images for analysis. However, low-resolution (LR) satellite images do not have enough spatial and texture details to accurately classify ground objects.
The research suggests a new method that utilises super-resolution reconstruction (SRR) technology to improve the resolution of spatial medium-resolution satellite images, matching the resolution of high- resolution images. Through the use of an enhanced Progressive Growing of GANs (PGGAN) model, the scientists successfully replicated Sentinel-2 pictures at a 2.5 metre resolution, which aligns with the resolution of GaoFen-1 (GF-1) images.
The main findings of the study can be outlined as follows:
- Creation of a customised PGGAN-MSR for enhancing multispectral remote sensing image super-resolution. This model improvement enabled better resolution and successful style transfer among various satellite sensors.
- Successful remote sensing image classification in a study area with wide coverage, enhanced resolution, and limited cloud cover using only a few SRR datasets.
- Suggestion of a novel categorization technique blending image resolution reconstruction with texture attributes derived from the reconstructed images. This method greatly enhanced classification accuracy, especially by adjusting Sentinel-2 images to the resolution of GF-1 images.
The study carried out tests in a setting that employed a NVIDIA Quadro P5000 GPU and specific software versions such as CUDA-12.0, CUDNN-8.2.4, TensorFlow-2.8, and Orfeo-ToolBox version
8.1. Various metrics were used to quantitatively assess the super-resolution reconstruction (SRR) effect, such as PSNR, SSIM, RMSE, SAM, and UQI. These measurements were used to evaluate image quality and the resemblance between the original and reconstructed images.
The SRR was accomplished through the utilisation of a modified Progressive Growing of GANs (PGGAN) model, known as PGGAN-MSR, designed specifically for reconstructing multispectral remote sensing images. The model was trained by incrementally scaling up generators and discriminators, aiming to enhance image quality and texture depiction.
Texture characteristics were obtained from the reconstructed images by employing the Grey-Level Co- occurrence Matrix (GLCM) technique in order to improve classification precision. These attributes, such as average, spread, uniformity, difference, etc., were employed to enhance spatial data for improved classification outcomes.
Texture features were incorporated to classify images reconstructed with super-resolution technology using SVM and RF classifiers. The inclusion of texture characteristics greatly enhanced classification precision, especially in agricultural regions, by offering additional spatial detail data. findings of the study showed that suggested method performed better than directly classifying the original images, showing its potential for real-world use in analysing remote sensing images. Additional studies are recommended to investigate the effects of various SRR models, confirm classification in broader regions and varied landscapes, and fine-tune parameters such as the sliding window size for texture feature extraction.
Conclusion:-
References
[1] Fröhlich, B., Bach, E., Walde, I., Hese, S., Schmullius, C., & Denzler, J. (2013, May 16). ISPRS-Annals - LAND COVER CLASSIFICATION OF SATELLITE IMAGES USING CONTEXTUAL INFORMATION. ISPRS-Annals - LAND COVER CLASSIFICATION OF SATELLITE IMAGES USING CONTEXTUAL INFORMATION. https://doi.org/10.5194/isprsannals-II-3-W1-1-2013 [2] More Diverse Means Better: Multimodal Deep Learning Meets Remote-Sensing Imagery Classification. (2021, May 1). IEEE Journals & Magazine | IEEE Xplore. https://ieeexplore.ieee.org/document/9174822 [3] Active Learning Methods for Remote Sensing Image Classification. (2009, July 1). IEEE Journals & Magazine | IEEE Xplore. https://ieeexplore.ieee.org/document/4812037 [4] Md. Palash Uddin, Md. Al Mamun & Md. Ali Hossain (2021) PCA-based Feature Reduction for Hyperspectral Remote Sensing Image Classification, IETE Technical Review, 38:4, 377-396, DOI: https://doi.org/10.1080/02564602.2020.1740615 [5] Cheng, X., Li, B., Deng, Y., Tang, J., Shi, Y., & Zhao, J. (2024, March 7). MMDL-Net: Multi-Band Multi-Label Remote Sensing Image Classification Model. MDPI. https://doi.org/10.3390/app14062226 [6] Universal Domain Adaptation without Source Data for Remote Sensing Image Scene Classification. (2022, July 17). IEEE Conference Publication | IEEE Xplore. https://ieeexplore.ieee.org/document/9884889 [7] Nwojo Agwu;Boukar Nzurumike Obianuju;Nnanna Lynda, M. M. (2022, January 1). Remote Sensing Image Classification for Land Cover Mapping in Developing Countries: A Novel Deep Learning Approach -International Journal of Computer Science & Network Security | Korea Science. Remote Sensing Image Classification for Land Cover Mapping in Developing Countries: A Novel Deep Learning Approach -International Journal of Computer Science & Network Security | Korea Science. https://doi.org/10.22937/IJCSNS.2020.22.2.28 [8] Zhang, G., Roslan, S. N. A., Wang, C., & Quan, L. (2023, September 28). Research on land cover classification of multi-source remote sensing data based on improved U-net network. Scientific Reports. https://doi.org/10.1038/s41598-023-43317-1 [9] Li, H., Dou, X., Tao, C., Wu, Z., Chen, J., Peng, J., Deng, M., & Zhao, L. (2020). RSI-CB: A Large- Scale Remote Sensing Image Classification Benchmark Using Crowdsourced Data. Sensors (Basel, Switzerland), 20(6), 1594. https://doi.org/10.3390/s20061594 [10] Remote Sensing Image Classification Based on Multi-Spectral Cross-Sensor Super-Resolution Combined With Texture Features: A Case Study in the Liaohe Planting Area. (2024). IEEE Journals & Magazine | IEEE Xplore. https://ieeexplore.ieee.org/document/10414975 [11] S. C. Park, M. K. Park, and M. G. Kang, ‘‘Super-resolution image reconstruction: A technical overview,’’IEEE Signal Process. Mag., vol. 20, no. 3, pp. 21–36, May 2003, doi: 10.1109/MSP.2003.1203207
Copyright
Copyright © 2024 Vaishnavi Deulkar, Shashwat Kale, Yashsingh Thakur, Prof. Anirudh Bhagwat. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60424
Publish Date : 2024-04-16
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online