

Ijraset Journal For Research in Applied Science and Engineering Technology
SummarizeMe: An AI Text Summarization Tool for Students
Authors: Kshiteej Pathak, Pawan Gawade, Raj Sathe, Aryan Ramerwar
DOI Link: https://doi.org/10.22214/ijraset.2024.63130
Certificate: View Certificate
Abstract
In the contemporary era of information abundance, the ability to distill key insights from voluminous textual data has become increasingly imperative. This project attempts to address this challenge by developing an innovative AI-Powered Text Summarization System. Leveraging advanced natural language processing (NLP) techniques and state-of-the-art machine learn- ing models, the system demonstrates a sophisticated capability to generate coherent and contextually relevant summaries from extensive textual datasets. The concept behind automatic text summarization involves gathering important and concise points from extensive data. With the vast and continually expanding information available on the internet, sifting through it to extract key data becomes challenging and time-consuming. Employing automatic text summarization simplifies this process, enabling users to efficiently gather essential data from large volumes of information. The methodology encompasses a multifaceted approach, com- mencing with the systematic collection of diverse textual data from varied sources such as academic articles, news reports, and legal documents. Following meticulous data preprocessing, which includes text cleaning, tokenization, and vectorization, the project employs a carefully selected AI summarization model for training and testing. The chosen model undergoes rigorous evaluation using established metrics like ROUGE and BLEU, ensuring the accuracy and efficacy of the summarization process. Applications of the developed system span across diverse domains, including academia, news aggregation, legal document analysis, and healthcare. A distinguishing feature lies in the integration of user-friendly elements, allowing for customization and user feedback, thereby enhancing adaptability to individual preferences.The project’s outcomes contribute substantively to the field of text summarization, providing a valuable tool for researchers, professionals, and enthusiasts grappling with information over- load. As the digital landscape continues to evolve, the AI-powered text Summarization System emerges as a potent solution, revolutionizing the way users interact with and extract meaningful insights from extensive textual content. Various methodologies exist for summarizing text, offering a selection of algorithms for implementation. TextRank, a method for extractive text summarization, operates on unsupervised learning principles. It employs undirected and weighted graphs, facilitating both keyword and sentence extraction. In this study, a model is developed to enhance text summarization outcomes, leveraging the Genism library within the domain of NLP. This approach contributes to a richer comprehension of the text’s essence, enabling readers to grasp its content more effectively. This report discusses the developmental journey of the system, highlighting key methodologies, applications, and implications for efficient content consumption in the digital age. The project not only addresses a pertinent contemporary issue but also sets the stage for further exploration and advancements in the realm of AI-driven text summarization.
Introduction
I. INTRODUCTION
In the contemporary digital landscape, characterized by an unrelenting influx of information, the discerning ability to navigate the vast sea of textual data has emerged as a critical skill. As the sheer volume of information available continues to grow exponentially, the challenge of extracting meaningful insights from this expansive content repository becomes increasingly complex. This project, at its core, responds to the pressing need for an intelligent, adaptive solution to facilitate efficient content consumption—a solution that goes beyond conventional methods and harnesses the prowess of artificial intelligence.
The motivation behind this endeavor is deeply rooted in the evolving nature of information consumption. Traditional paradigms of reading and comprehension struggle to keep pace with the dynamic and interconnected nature of contemporary data. Individuals, researchers, and professionals encounter a plethora of textual sources spanning academic discourse, news updates, legal intricacies, and multifaceted domains. In the face of this information deluge, our project aspires to be more than a mere tool; it envisions a transformative force that empowers users to not only navigate but to truly understand and leverage the richness of textual content.
Our AI-Powered Text Summarization System transcends the limitations of conventional approaches. By integrating advanced natural language processing (NLP) techniques and leveraging state-of-the-art machine learning models, the system endeavors to comprehend the subtleties of language, contextual nuances, and the intricate web of information. It is more than a summarization tool; it is an intelligent companion, providing users with succinct yet profound summaries that encapsulate the essence of diverse textual sources.
As we embark on this exploration, the project seeks not only to address immediate challenges but to contribute to the broader narrative surrounding the interaction between artificial intelligence and human cognition. The ensuing sections delve into the intricacies of our methodologies, the myriad applications envisioned across sectors, and the profound implications for the evolving landscape of information consumption. Through this project, we aspire to usher in a new era where technology becomes an enabler, enhancing our ability to navigate and comprehend the ever- expanding realm of digital knowledge.
The time taken for students to revise their course material for exams can vary based on several factors, including the complexity of the subject, the student’s familiarity with the material, the depth of understanding required, and the student’s study habits. Here are some general estimates for the time taken to revise course work for exams:
- Introductory Courses
- Time for Revision: 1-2 weeks
- These courses usually cover foundational concepts and can be revised more quickly.
2. Intermediate Courses
- Time for Revision: 2-3 weeks
- Intermediate courses may require more time for revision due to the complexity of the topics.
3. Advanced Courses
- Time for Revision: 3-4 weeks
- Advanced courses often involve in-depth study and may require more time for comprehensive revision.
II. PROPOSED STRUCTURE
Our methodology for developing an AI-powered Text Sum- marization system revolves around the following key phases. First, we define the problem of information overload and the target users’ needs. Next, we collect and preprocess diverse text data for training. We select appropriate AI and NLP algorithms[1] for content extraction and context preservation. Then, we develop a user-friendly interface and integrate AI models, followed by rigorous performance evaluation and system refinement based on user feedback.[2]
A. Training Models
- In the ”Training Models” phase, you gather a diverse dataset of textual documents. This dataset should encompass various domains and genres to ensure the model’s versatility.
- You preprocess the data, cleaning and formatting it for training. This includes tokenization, stem- ming, or lemmatization, and removing stopwords and noise.[3]
- With a preprocessed dataset, you train the AI summarization models. This training phase involves training custom models.[4], [5]
- The models learn to recognize important information, understand the context, and generate coherent
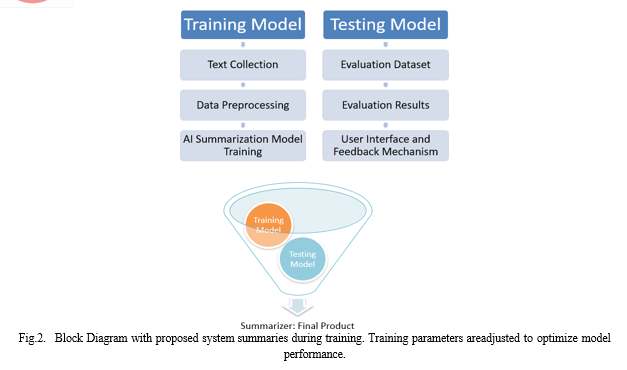
B. Testing Models
- The ”Testing Models” phase evaluates the perfor- mance and quality of the trained models. This is a critical step to ensure that the summarization results are accurate and coherent.
- You use a separate evaluation dataset that the mod- els have not seen during training to assess their generalization abilities.
- Evaluation metrics such as ROUGE (Recall- Oriented Understudy for Gisting Evaluation) or BLEU (Bilingual Evaluation Understudy) are ap- plied to measure the quality of[6] the generated summaries.[7]
- Models that meet the desired performance criteria in terms of accuracy, fluency, and coherence are considered suitable for the next phase.
C. Integration into the Final Product:
- Once the models have been trained and tested successfully, they are integrated into the ”Final Product.”[8]
- The user interface and feedback mechanism provide users with the ability to input text documents and request summaries.
- When a user submits a document for summarization, the AI models process the input, generating concise and coherent summaries.
- The system may also incorporate post-processing steps to enhance the quality of the summaries fur- ther.
- The summarized content is then presented to the user, completing the summarization process.
The connection between these stages ensures that the models used in the final product are well-trained, rigorously tested, and capable of delivering high-quality summaries.The system’s final output is high-quality summarizations that users can interact with. Ongoing monitoring and user feedback loops also help in fine-tuning the models to maintain and improve their performance.
Conclusion
In summary, the development of the AI-Powered Text Summarization System represents a significant stride in addressing the contemporary challenge of information overload. The rigorous methodology employed, encompassing data preprocessing, model training, and systematic testing, ensures the precision and efficiency of the summarization process. The system’s versatility is demonstrated through its applications across diverse domains, including academia, news aggregation, legal document analysis, and healthcare. The integration of user-friendly features, such as customization options and a feedback loop, underscores the system’s commitment to enhancing the user experience and adaptability to individual preferences. Through these advancements, the system contributes to the broader goal of efficient content consumption in the digital era. The study showcases our utilization of advanced techniques for text summarization on documents, employing the extractive summarization method known as the TextRank algorithm. Initially, essential libraries and associated functions in Python were loaded, followed by the implementation of the code to generate text summaries. Subsequently, a model was introduced with minor enhancements aimed at refining the summarization process by providing an outline of the text. The strategies outlined in this paper aim to yield improved outcomes in text summarization, leveraging the Genism library within the field of NLP. These approaches facilitate a more comprehensive understanding of the document’s overarching meaning. This research not only highlights the technical aspects of the system’s development but also underscores its practical implications for end-users in various professional fields. As information continues to proliferate, the AI-Powered Text Summarization System emerges as a valuable tool, streamlining the process of distilling essential insights from extensive textual data. The study opens avenues for future research, encouraging further exploration of applications and refinements to advance the capabilities of text summarization systems. Overall, this research contributes substantively to the discourse on leveraging artificial intelligence for effective information management and consumption.
References
[1] B. K. Jha, C. M. V. Srinivas Akana, and R. Anand, “Question answering system with indic multilingual-bert,” in 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), 2021, pp. 1631–1638. [2] P. Sathishkumar, P. Selvaraju, P. Harichandran, P. Manickavasakan, and B. S, “Deep wrap-up- automatic document summarization with anima- tions,” in 2022 6th International Conference on Electronics, Communi- cation and Aerospace Technology, 2022, pp. 1069–1074. [3] Y. Lu, Y. Dong, and L. Charlin, “Multi-xscience: A large-scale dataset for extreme multi-document summarization of scientific articles,” 2020. [4] S. Gupta and N. Khade, “Bert based multilingual machine comprehension in english and hindi,” 2020. [5] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” 2019. [6] Y. Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V. Stoyanov, “Roberta: A robustly optimized bert pretraining approach,” 2019. [7] X. Zhang, Q. Wei, Q. Song, and P. Zhang, “An extractive text sum- marization model based on rhetorical structure theory,” in 2023 26th ACIS International Winter Conference on Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing (SNPD- Winter), 2023, pp. 74–78. [8] S. Ruder, “Why You Should Do NLP Beyond English,” http://ruder.io/ nlp-beyond-english, 2020.
Copyright
Copyright © 2024 Kshiteej Pathak, Pawan Gawade, Raj Sathe, Aryan Ramerwar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63130
Publish Date : 2024-06-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online