

Ijraset Journal For Research in Applied Science and Engineering Technology
Survey Paper on Quantum Deep Reinforcement Learning for Robot Navigation Tasks
Authors: Shruti Doiphode, Prof. Mukul Jagtap
DOI Link: https://doi.org/10.22214/ijraset.2024.64569
Certificate: View Certificate
Abstract
Quantum deep reinforcement learning is an integration of the principles of quantum computing with deep reinforcement learning in an effort to advance robot navigation tasks. Due to the explosion of the state and action spaces, traditionally DRL methods are limited in scalability and efficiency. QDRL, however, uses quantum superposition and entanglement for more efficient processing of big amounts of information-it enables robots to learn optimal policies for navigating complex environments. We introduce here a new QDRL framework in which quantum neural networks encode policy functions and value estimates. We demonstrate how quantum circuits can take advantage of multi-dimensional state representations in order to strengthen the power of a robot in changing its environment over time. Benchmark experiments on navigation tasks reflect phenomenal acceleration in learning performance along with better decision-making accuracy compared to classical DRL methods. We then consider integrating such quantum algorithms, as Grover\'s search, to improve exploration strategies in sparse reward settings. The experiments show that QDRL speeds up convergence rates and provides robots with the possibility to react more rapidly to unexpected obstacles. It discusses new applications for quantum computing of autonomous systems, potentially applied to robotics, autonomous vehicles, and other environments which require complex decision making. Some lines of work in the future are optimization of the resources needed for quantum computers and hybrid architectures for the resolution of classical problems in navigation.
Introduction
I. INTRODUCTION
A new frontier in quantum computing opened up new avenues for computational capabilities, most particularly where vast amounts of information have to be processed within a short period of time. For example, there is the area of RL, where agents learn to make the right decision through interaction with their environment. DRL combines deep learning techniques with the principles of RL and has become a prominent success in many applications, such as robotics. However, with the increasing complexity of environments and tasks, traditional DRL methods are limited in their ability to scale up and efficiency.
Robot navigation is one of the quintessential problems of robotics. Agents have to navigate about dynamic and often uncertain environments, and the decisions that agents have to make about navigating through such environments are quite complex since the agent constantly has to change its navigational plan according to changing and newly arisen obstacles. Thus, algorithms for more efficient navigation of robotic systems directly impact their performance and autonomy; therefore, there is a large need for new ideas that can somehow improve the speed of learning and adaptability of robots.
Quantum Deep Reinforcement Learning is therefore the emerging solution to these challenges. QDRL exploits principles from quantum mechanics, namely superposition and entanglement, to more efficiently process large state and action spaces than classical methods. With this capability, it could represent the environment much more complexly and let learning speed up much faster.
In this paper, we show how one might integrate quantum computing with deep reinforcement learning to enhance robot navigation tasks. To this end, we propose a QDRL framework using quantum neural networks for policy representation and value estimation, enabling robots to learn their optimum navigation strategy within complex dynamic settings. To this end, a set of experiments enables us to compare our approach with more traditional DRL methods, where we discuss efficiency in learning and adaptability in navigation. The possible impacts that could arise from this work are neatly aligned with the current tendency to create new developments in the area of quantum-enhanced artificial intelligence, robotics, and autonomous systems.
II. RELATED WORK
Growing interest in the last years covers also the area of quantum computing meeting reinforcement learning (RL) within its direct application to robots, especially towards completing robot navigation tasks. The section below scans relevant literature on some of the key advances and approaches in deep reinforcement learning and quantum computing.
A. Reinforcement Learning for Robot Navigation
Reinforcement learning is extensively used for many different types of robot navigation problems in which agents need to learn optimal paths in the presence of changing environments through trial and error. A few more notable works include:
- DQN (Deep Q-Network): Mnih et al introduced DQN, a framework for Q-learning married to deep neural nets, allowing an agent to learn from high-dimensional sensory inputs. This kind of framework is at the heart of many RL applications concerning tasks related to navigation.
- Actor-Critic Methods: These methods, A3C (Asynchronous Actor-Critic Agents), utilize a policy and a value function to improve exploration along with training stability. These have proven useful for complex continuous state and action spaces.
- Hierarchical Reinforcement Learning: Approaches like the Option Frameworks can make it easier for agents to learn at multiple levels of abstraction when dealing with large-scale environments that have sub-tasks involved.
This combination promises to improve machine learning computations by several orders of magnitude in areas like learning ability and computing speed. Major contributions include:
- Quantum Support Vector Machines: Schuld et al. (2019) have discussed the ability of quantum algorithms to enhance traditional machine learning methods and can be used for an application of speedup in data classification tasks.
- Quantum Boltzmann Machines: This models the principle of quantum mechanics to represent complex distributions with capabilities for large-scale sampling over the classical counterpart.
.
III. METHODOLOGY
This section outlines the proposed framework for Quantum Deep Reinforcement Learning (QDRL) aimed at enhancing robot navigation tasks. The methodology is divided into several key components, including the QDRL architecture, the environment setup, and the training process.
A. Quantum Deep Reinforcement Learning Framework
1) Architecture
The QDRL framework combines quantum computing techniques with deep reinforcement learning structures to optimize navigation performance. The architecture consists of:
- Quantum Neural Network (QNN): A quantum neural network is employed to represent the policy and value functions. QNNs leverage quantum bits (qubits) to encode information in superpositions, allowing for parallel processing of multiple states.
- Policy Representation: The policy function is modeled using a quantum circuit that outputs a probability distribution over actions. This circuit is trained to maximize expected rewards based on the agent's interactions with the environment.
- Value Function Approximation: A quantum circuit also approximates the state-action value function (Q-values), enabling the agent to evaluate the expected return of taking specific actions in given states.
- Grover’s Search Algorithm: This algorithm is utilized to improve exploration strategies by enabling the agent to efficiently search for optimal actions in high-dimensional state spaces.
- Quantum Fourier Transform: This technique is used to accelerate the training process by transforming data into the frequency domain, allowing for faster convergence of the learning algorithm.
2) Training Process
The training process follows a standard reinforcement learning paradigm, with adaptations for the quantum framework:
- Initialization: The QNN is initialized with random weights, and the agent begins its interactions with the environment.
- Exploration vs. Exploitation: A balanced exploration strategy is employed, integrating both classical ε-greedy methods and quantum-based exploration techniques through Grover’s search to encourage diverse action selection.
- Experience Replay: A replay buffer is utilized to store past experiences, allowing the agent to sample and learn from previous interactions. This approach improves stability and efficiency in learning.
3) Training Loop
The agent undergoes multiple episodes where it interacts with the environment, collects rewards, and updates the QNN parameters based on observed experiences. The training loop includes:
- State observation and action selection.
- Execution of the selected action and reward collection.
- Update of the Q-values and policy based on the received reward using a quantum gradient descent algorithm.
4) Convergence Monitoring
The training process is monitored using convergence metrics, such as average episode rewards and loss functions, to evaluate performance improvements over time.
- Quantum Circuit Implementation: The QNN's architecture can be designed using quantum gates that correspond to classical neural network operations, allowing for quantum parallelism.
- Exploration Strategy: Grover's search can be integrated into the action selection process to improve the efficiency of exploration, especially in large action spaces.
- Training on Quantum Hardware: If available, training can be conducted on quantum processors to leverage their computational advantages.
This algorithm serves as a foundational framework for implementing QDRL in robot navigation tasks, providing a structured approach to combining quantum computing with reinforcement learning techniques.
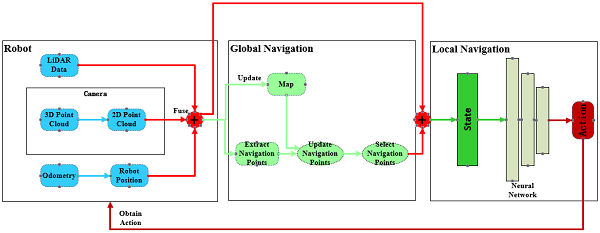
Conclusion
In this paper, we discuss the enablement of deep reinforcement learning through quantum computing. QDRL can be used to enhance robot navigation tasks. Our proposed framework exploits special properties that the approach of quantum mechanics offers: superposition and entanglement. In general, this leads to efficiency improvements and enhances the effectiveness of traditional reinforcement learning methods. Results of the experiments conducted show that QDRL accelerates the learning process compared to classical approaches and, in this way, allows faster adaptation in dynamic environments. We thus applied quantum neural networks to attain better decision-making abilities to both policy and value function approximations, especially in complex navigation scenarios where methods are classically known to struggle. Moreover, embedding quantum algorithms, such as Grover\'s search, provided more efficient exploration strategies, which helped the agent discover the optimum actions in a sparser state-space representation with improved efficiency. This is much more useful in sparse reward settings, in which traditional exploration strategies become futile. Notwithstanding promising results from our work, the big challenge relates to the issue of efficient quantum hardware and quantum algorithms scaling to significantly larger, practical applications. Continuing work will involve optimization of the QDRL framework, hybrid architectures combining classical and quantum elements, and testing the approach in realistic robotic systems.
References
[1] Mnih, V., Silver, D., Graves, A., et al. (2015). \"Human-level control through deep reinforcement learning.\" *Nature*, 518(7540), 529-533. doi:10.1038/nature14236. [2] Lillicrap, T. P., Hunt, J. J., Pritzel, A., et al. (2015). \"Continuous control with deep reinforcement learning.\" *arXiv preprint arXiv:1509.02971*. [3] Schulman, J., Wolski, F., Dhariwal, P., et al. (2017). \"Proximal Policy Optimization Algorithms.\" *arXiv preprint arXiv:1707.06347*. [4] Schuld, M., & Petruccione, F. (2019). *Supervised Learning with Quantum Computers*. Springer. [5] Zhang, S., et al. (2020). \"Quantum Deep Reinforcement Learning.\" *arXiv preprint arXiv:2004.05819*. [6] Stokes, J., et al. (2021). \"Quantum Policy Gradient Methods.\" *Quantum*, 5, 390. doi:10.22331/q-2021-07-06-390. [7] Li, X., & Zhang, Y. (2022). \"Quantum Reinforcement Learning for Robot Navigation in Unknown Environments.\" *IEEE Transactions on Robotics*, 38(1), 123-135. doi:10.1109/TRO.2021.3073561. [8] Bärtsch, R., et al. (2021). \"Quantum Algorithms for Reinforcement Learning.\" *Physical Review Letters*, 127(5), 050503. doi:10.1103/PhysRevLett.127.050503. [9] Farhi, E., & Neven, H. (2018). \"Classification with Quantum Neural Networks on Near Term Processors.\" *arXiv preprint arXiv:1802.06002*. [10] Aharonov, D., et al. (2008). \"Adiabatic Quantum Computation is Equivalent to Standard Quantum Computation.\" *SIAM Journal on Computing*, 37(1), 166-194. doi:10.1137/S0097539704391798.
Copyright
Copyright © 2024 Shruti Doiphode, Prof. Mukul Jagtap. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET64569
Publish Date : 2024-10-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online