

Ijraset Journal For Research in Applied Science and Engineering Technology
Tarjama:The Kashmiri Translator
Authors: Varsha Jawrani , Aman Kachru, Komal Sethiya , Mrs. Lifna C S
DOI Link: https://doi.org/10.22214/ijraset.2023.55059
Certificate: View Certificate
Abstract
The Kashmiri language is spoken by a large population in the Indian subcontinent, particularly in the region of Jammu and Kashmir. However, it is often considered a lesser-known language and has limited resources for language translation, especially when compared to more commonly used languages. The aim of this research is to develop a Kashmiri translator that can accurately translate text from English to Kashmiri and vice versa. The proposed system will be based on machine learning algorithms and will utilize a dataset of parallel corpora for training the model.
Introduction
I. INTRODUCTION
The Kashmiri language is an Indo-Aryan language spoken primarily in the Kashmir Valley, India. It is estimated that there are approximately 5.5 million speakers of Kashmiri worldwide, with the majority residing in India. Despite its widespread use, access to language technology for Kashmiri speakers is limited, which has resulted in a significant barrier to communication, education, and economic development for many in the region.
In this research paper, it proposes a Kashmiri language translator project that aims to bridge the gap in language technology for Kashmiri speakers. This project will leverage modern machine translation techniques to develop a robust and accurate Kashmiri-English translator, with the goal of improving communication and access to information for Kashmiri speakers.
II. BACKGROUND
Machine translation (MT) is a field of natural language processing that focuses on automatically translating text from one language to another. MT has come a long way since its inception, and recent advances in neural machine translation (NMT) have led to significant improvements in translation quality. However, most of the current machine translation systems are designed for high-resource languages like English, Spanish, and French, and are not well suited for low-resource languages like Kashmiri.The Kashmiri language is an important aspect of the cultural identity of the people of Jammu and Kashmir, India. However, it has faced challenges in recent years, including a lack of standardization and limited representation in digital media. These factors have contributed to a decline in the usage and promotion of the language, particularly among the younger generations. The development of a reliable and accurate Kashmiri translator will help to overcome these challenges and preserve the language for future generations.
III. PROBLEM DEFINITION
Translation is a means of providing creative expression in a specific language to a wider audience. The amount of creative literature produced in that language is essential to a language and its existence. In this regard, Kashmir is currently fighting a very hard battle against both local and global challenges. Kashmiri writers writing in Kashmir or artists singing or performing in Kashmir believe that the lack of translations makes the treasure of Kashmiri literature unattainable. The gulf between Kashmir and the rest of India widens considerably.?????? hopes to overcome all the challenges faced by the Kashmiri people today.
IV. LITERATURE SURVEY
The speech synthesis system[1] is entirely based on deep neural networks. The system consists of five main building blocks: a phoneme-graph model, a segmentation model, a phoneme duration model, a fundamental frequency model, and a sound synthesis model. text provided by phoneme-phonemic models or phonemic dictionaries to generate phonemes. Phonemes are provided as input to the duration model of the phoneme and the prediction model F0 to assign a duration to each phoneme, and generates a contour F0. Finally, phonemes, phoneme lengths, and F0 are used as local harmonic input features to the sound synthesis model, which produces the final speech.
TTS[2] uses a phoneme-phoneme transformation model. The text-to-speech (TTS) synthesis process consists of two main stages. The first is text analysis, where the input text is transcribed into a phonetic language or other representation, and the second is speech waveform generation, where the output is generated from phonetic information and this prosperity.
To develop this synthesis [3] TTS, the method used is object-oriented analysis and development. It takes plain text or marked up text e.g. HTML or JSML (Java Synthetic Markup Language) as input, then it does natural language processing on it by performing parsing text and language analysis. The next step is to convert it to a synthetic voice using prosody phonetics.
[4] It is an English to Hindi machine translation system based on recurrent neural network (RNN), LSTM (short-term long-term memory) and attention mechanism. It uses text-to-speech and speech-to-text modules for conversion. The first step in input text processing is performed by performing various NLP techniques on the input text, such as text linearization and normalization. The second is speech-language transformation where the speech waveform for each word and phrase is generated using both phonemes and Prosody.
This [5] includes the operation of speech-to-speech translation systems. The Speech-to-Speech translation system has three main components: automatic speech recognition, machine translation, and text-to-speech (TTS). In this article, the methods and technologies are used to create two independent pieces of software; one was IBM MASTOR and the other Verbmobil was studied. IBM uses audio modeling for speech recognition, speech translation based on NLU/NLG, and TTS system based on IBM TTS shaping technology.
Semi-naturally spoken voice database collected from TV channels in 15 different languages[6]. MFCC is used as spectral characterization. The average language recognition rate across India's 15 languages ??is around 88%.
Features are stored in two ways[7] - Images of features are generated and in other features extracted and a dimension is added, no images are generated and features are stored in JSON data format. The audio files were collected manually. The data they had were audio files and they decided to get the MFCC and Mel spectra from those audio files. Therefore, their final dataset includes images from MFCC and Mel-Spectrogram. Persio-Arabic-Devanagari converter[8] with 90% accuracy. A rule-based approach is used. This is a Persio- Arabic-Devanagari converter. with 90% accuracy.10000 words were used to test the converter.
V. METHODOLOGY PROPOSED
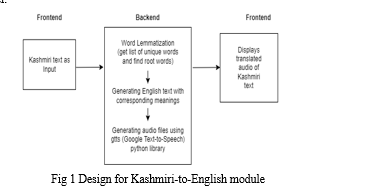
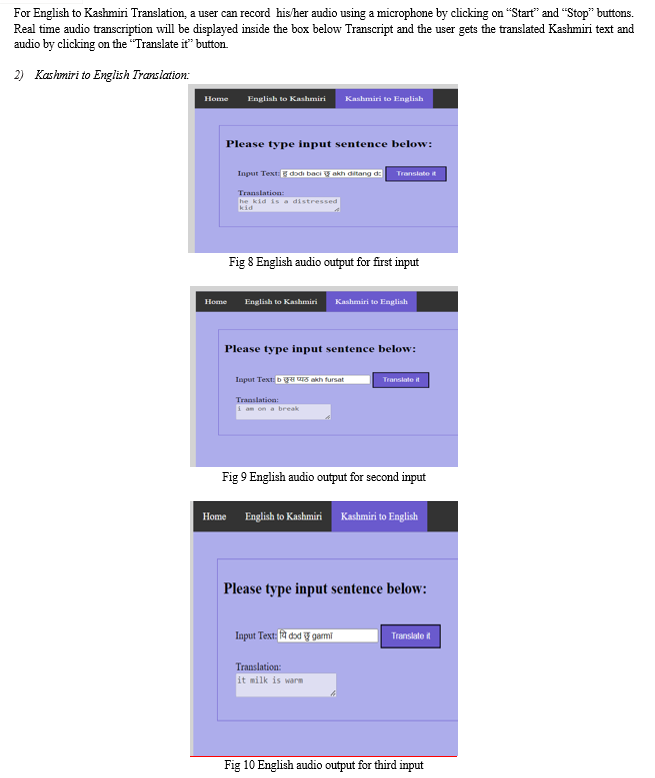
The methodology used in the project is more straightforward. Being the first of its kind, the main task was to collect and prepare the adequate dataset as needed for the project. After the dataset was ready the model was trained on a compare and print-based model. The model just compares the dataset and gives the output.This project can perform two actions, one being to convert from English to Kashmiri and visa-versa. In the first phase the phrase is spoken and recorded by the system. Then the voice is converted into text using python's Speech Recognition library which converts any speech data into text form.After that, the text phrase is converted into a list and that list is taken into consideration.The words in the list are searched for in the dataset and once found are stored in another list of output words.These words are then formed into a meaningful full sentence in the Kashmiri language which is then converted into audio using the dataset and the links that are present in the dataset.
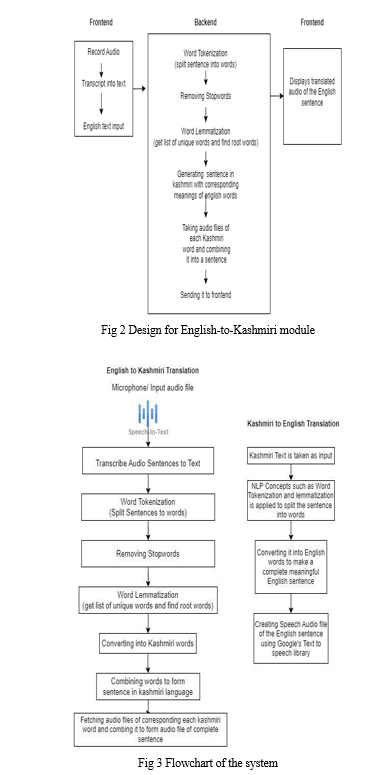
Now for the other part, the Kashmiri phrase is typed out in the system interface and the sentence is split into a list of words keeping “ “ as a delimiter.Later this list is compared in the dataset and words that are generated are put in a list to get an English phrase that holds some meaning.Later using python’s “gtts” library the phrase is spoken by the system so that the user can get the output in the form of audio.To do the voice and text conversion many python libraries are used and apart from this many data handling and NLP tools are used to make this model.

For Kashmiri to English Translation, a user can provide Kashmiri text input inside the input box and he/she gets the translated English text and audio by clicking on the “Translate it” button.
VII. DISCUSSION
The results of this research demonstrate that machine translation can be effectively applied to low-resource languages like Kashmiri, and has the potential to greatly improve communication between speakers of different languages. Our Kashmiri language translator is able to generate quality translations that are fairly accurate and fluent than those generated by existing machine translation systems, and provides a platform for effective communication between speakers of Kashmiri and other languages.
VIII. FUTURE WORK
In the future, the plan is to expand the scope of the project to include other low-resource languages, with the goal of making language technology more accessible and equitable for all. Additionally,there is a plan to explore the use of transfer learning to fine-tune the network for specific domains, such as medical or legal text, which would make it more suitable for use in specific applications.
Overall, the proposed Kashmiri language translator project has the potential to make a significant impact on language technology for low-resource languages and help to improve communication and access to information for communities around the world.
Conclusion
The proposed Kashmiri Translator Project represents an important step towards preserving and promoting the Kashmiri language, which has faced challenges in recent years due to a lack of standardization and limited representation in digital media. By developing an AI-powered translation system, this study aims to address these issues and provide a valuable resource for individuals and organizations looking to promote and preserve the language. Through this project, the authors hope to make a positive impact on the cultural heritage of the people of Jammu and Kashmir and contribute to the field of NLP and machine translation.
References
[1] Ar?k, Sercan Ö., et al. \"Deep voice: Real-time neural text-to-speech.\" International conference on machine learning. PMLR, 2017. [2] Dutoit, Thierry. \"High-quality text-to-speech synthesis: An overview.\" Journal Of Electrical And Electronics Engineering Australia 17.1 (1997): 25-36. [3] Nwakanma, Cosmas & Oluigbo, Ikenna & Izunna, Okpala. (2014). Text – To – Speech Synthesis (TTS). 2. 154-163. [4] Priyanka Padmane, Ayush Pakhale, Sagar Agrel, Ankita Patel,Sarvesh Pimparkar,Prajwal Bagde. Speech-To-Speech Translation. International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 [5] Dureja, Mahak, and Sumanlata Gautam. \"Speech-to-Speech Translation: A Review.\" International Journal of Computer Applications 129.13 (2015): 28-30. [6] Koolagudi, Shashidhar G., Deepika Rastogi, and K. Sreenivasa Rao. \"Identification of language using mel-frequency cepstral coefficients (MFCC).\" Procedia Engineering 38 (2012): 3391-3398. [7] Malla, Shehzen Sidiq. \"Acoustic features based on accent classification of Kashmiri language using deep learning.\" Global Journal of Computer Science and Technology 22.D1 (2022): 39-43. [8] Kak, Aadil Amin, Nazima Mehdi, and Aadil Ahmad Lawaye. \"Building a Cross Script Kashmiri Converter: Issues and Solutions.\" Proceedings of Oriental COCOSDA (The International Committee for the Co-ordination and Standardization of Speech Databases and Assessment Techniques) (2010).
Copyright
Copyright © 2023 Varsha Jawrani , Aman Kachru, Komal Sethiya , Mrs. Lifna C S. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55059
Publish Date : 2023-07-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online