

Ijraset Journal For Research in Applied Science and Engineering Technology
Telugu Data Classification
Authors: Komal Parashar, V. Durga Bhavani, V. Keerthana, R. Narasimha
DOI Link: https://doi.org/10.22214/ijraset.2024.59508
Certificate: View Certificate
Abstract
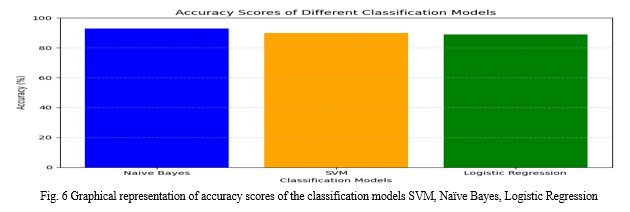
Telugu is considered as the difficult languages which is morphologically rich when it comes to Dravidian languages. There are many Telugu documents available on Internet, it is important to organize the data by automatically by assigning a collection of text with predefined categories. Here the Telugu data is classified into multiple areas like business, sports, entertainment, nation, editorial is the main goal throughout this research work. This research work provides up an efficient model by adopting some ML classifiers such as SVM, Naive Bayes, and Logistic regression to perform some areas of classification on Telugu data. The results obtained by various machine-learning models are compared and an efficient model is discovered, and it is observed that the Naive Bayes model outperformed with reference to accuracy, precision, recall, and F1-score.
Introduction
I. INTRODUCTION
These days, many people use online multimedia platforms such as blogs, online shopping review sites, feedback forums, and social networking sites. Share opinions and views in their native languages on Facebook, Twitter, WhatsApp, Instagram, LinkedIn about a specific topic. Here the text classification helps in the classification of the user opinions or views provided by the users into the domain it falls under and helps in organizing, identification of user preferences, personalized delivery of content, market analysis and facilitates the targeted users. Telugu, a really complex Dravidian language, poses challenges for organizing its abundant online content. To streamline this process, we aim to categorize Telugu documents into predefined topics like business, science, sports, etc. We'll employ modern techniques like Support Vector Machine (SVM); Naive Bayes; and Logistics Regression; backed by Natural Language Processing (NLP) in Machine Learning. By leveraging these methods, we seek to accurately classify Telugu text data and generate meaningful insights.
II. LITERATURE SURVEY
Deepu et al., n.d. [1] proposed a rule-based approach for opinion classification of Malayalam motion picture audits, tending to challenges stemming from client input containing spelling botches. Essentially, Sanjib et al.,[2] created a framework utilizing administered classification methods to classify Odia motion picture audit estimations as positive and negative. In differentiate, S.S. Mukku et al., [3] displayed a system for Telugu opinion investigation utilizing Doc2Vec models prepared with different ML procedures Moreover, J.Sultana et al., [4] compared conventional Profound Learning and ML approaches for opinion expectation on instructive information, finding MLP to abdicate the finest results. At long last, D Naga et al., [5] examined n-gram include selection's effect on news article content classification utilizing semi-supervised learning strategies, highlighting SVM's prevalence. The creators of the current think about propose to analyze Telugu news assumptions utilizing machine learning strategies to address the require for assumption investigation in Telugu news.
Kamal Sarkar et al., [6] and colleagues did some study about feeling analysis using a multinomial Naïve Bayes classifier enhanced with fancy determination characteristics. They focused on looking at feelings in tweets written in Bengali and Hindi, showing how their method can work in different languages. The Multinomial Naïve Bayes thing is great for handling jobs about text figures. The determination chat included deeper feeling analysis, underlining how smart their process is. The work by Sarkar and the gang gives us some good ideas for studying feelings in various languages. This study is super important in the international social media world because looking at feelings helps in knowing what people think across different languages.
Reddy Naidu et al., [7] presented a novel two-phase estimation research approach in their sentiment analysis investigation for Telugu e-News. This technique uses Telugu SentiWordNet, a lexical resource specific to the language, to categorize phrases found in Telugu e-News articles. The authors' use of a two-phase process points to a sophisticated and specialized method for handling the complexities of sentiment analysis in Telugu. Naidu et al. substantially advance sentiment analysis research by concentrating on regional language subtleties and offering a system that works with Telugu e-news information.
Their research contributes to our knowledge of sentiment dynamics in regional languages and may help tailor sentiment analysis techniques to a different type of linguistic circumstances. There is potential for improving sentiment analysis methods through more investigation of their methodology.
Samuel et al., [8] and his colleagues conducted a study that somehow connects to something about Coronavirus Tweets in the field of social media analytics. Their research on the Calculated Relapse and some other fancy Naïve Bayes techniques resulted in good precision, especially when they're dealing with the tiny Tweets. Because Twitter, is about short messages, so being brief is very important. This paper gives a guide for making tweet categorization methods better for the occurrences which happens like right now, you know, the epidemic.
III. EXISTING SYSTEM METHODOLOGY
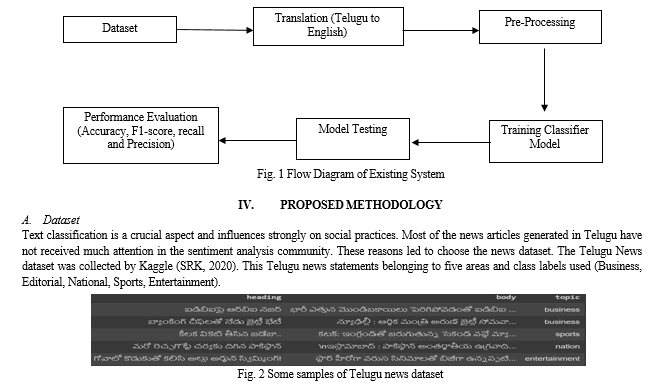
In the existing implementation Telugu news is translated into English using the Google translation library available in Python. Then determined the sentiment scores using various tagging techniques and mark them as - positive/negative. Then, an attempt was made for classifying polarity value of Telugu news statements using several ML classifiers namely Naive Bayes, Random Forest, Passive-Aggressive Classifier, Perceptron, and SVM (Support Vector Machine). Here, the models are created for classification. One is a binary class and the other is a multiclass model. In binary classification, the system categorizes sentiment into positive polarity or negative polarity. Meanwhile, in the multiclass classification task, the system further categorizes the sentiment into business, editorial, entertainment, nation, and sports. Results were implemented using test data against performance parameters.
A. Implementation of Existing System
- Telugu news is translated into English
- Sentiment analysis is performed using different models
- The classifiers SVM, Random Forests and Naïve Bayes used for the multiclass task
- Training the Classifier Models
- Testing the trained classifier models
- Analysis of model performance
B. Pre-Processing
Pre-Processing step is the first crucial step for removing the cleaning the data so that model can understand the effectively to yield a high-performance result. The pre-processing steps includes
- Removes special characters
- Sklearn: It is Label Encoder assigns numbered values to categories.
- Tokenization: Breaking down the text into tokens and creating vocabulary.
C. Feature Extraction
Feature extraction: - Used in converting raw data into computer understandable that is into numerical format. The Feature Extraction includes
- Vectorization: Converting the text into numerical values using TF-IDF (Term Frequency Inverse Document Frequency) and count vectorization.
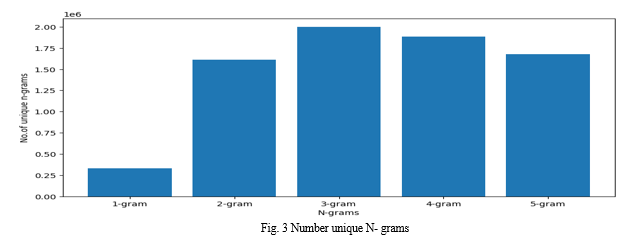
- Divides text into feature matrix using n-grams (uni-grams, bi-grams, tri-grams, 4-grams, 5-grams) which is the sequence of words.
D. Classification Models
In our extend we used mainly three ML classification models those are Naïve Bayes, SVM, and Logistic Regression. A robust methodology which is simple and effective in classifying the Telugu text into different types of categories. Here, Naïve Bayes is very efficient classification technique for the small range of dataset and it calculates the probability for each category base on the input extracted features. Equally, SVM strikes to get the optimal hyperplane separating data points of various categories with the largest margin and efficiently captures the relationships in the high dimensional space. Logistic regression is also called as linear model which measures the probability of the binary output which can be further extended to classify multiple categories.
E. Implementation
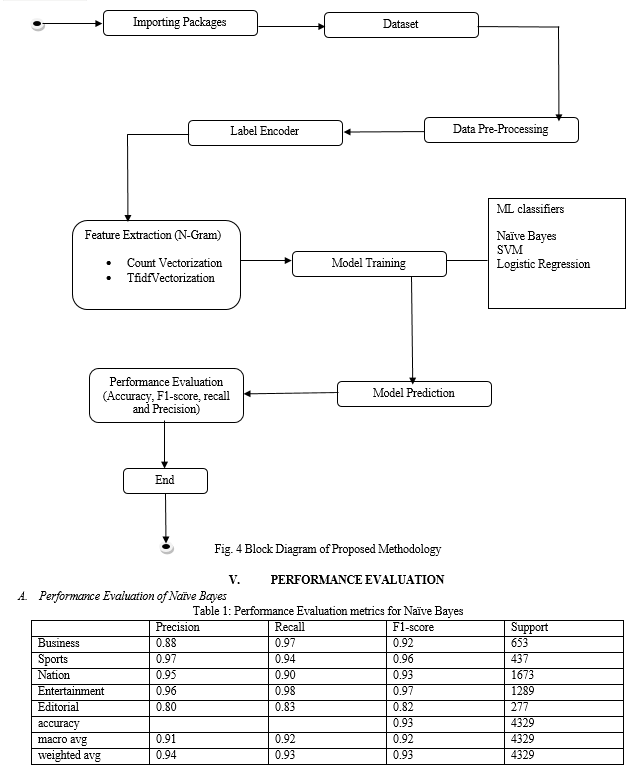
The Flowchart starts with the importing of the packages such as indic-nlp library for the Indian Language understanding. Then, the dataset is extracted from the Kaggle for the Telugu data classification and processing data and giving a numerical value to each topic with the sklearn library- Label Encoder so that the model can understand and yield efficient results. After the Label encoding the feature extraction of N-gram using Count vectorization and TfidVectorization which is used for counting the frequency of occurrence of the n-gram (uni-gram, bigram, tri-gram, 4-gram, 5-gram). The vectors are generated in the feature extraction is kept for training the classification models Naïve bayes, SVM and Logistic Regression. After the models are trained the trained model is used for the prediction and performance of these models are being evaluated. The Evaluation of the trained is provided by the evaluation metrics Accuracy, F1-score, Precision and Recall.

Conclusion
Our research work helps in the classifying the Telugu text into the categories such as Business, sports, nation, Editorial and Entertainment. The Telugu news dataset is used for classification of categories using the ML classification models like Naïve Bayes, Logistic Regression and SVM. The Naïve Bayes performance outperforms Logistic Regression and SVM.
References
[1] Nair, D. S., Jayan, J. P., Rajeev, R. R., & Sherly, E. (2014, September). SentiMa-sentiment extraction for Malayalam. In 2014 International conference on advances in computing, communications and informatics (ICACCI) (pp. 1719-1723). IEEE. [2] Sahu, S. K., Behera, P., Mohapatra, D. P., & Balabantaray, R. C. (2016). Sentiment analysis for Odia language using supervised classifier: an information retrieval in Indian language initiative. CSI transactions on ICT, 4, 111-115. [3] Mukku, S. S., Choudhary, N., & Mamidi, R. (2016). Enhanced Sentiment Classification of Telugu Text using ML Techniques. SAAIP@ IJCAI, 2016, 29-34. [4] Sultana, J., Sadaf, K., & Jilani, A. K. (2021). Classifying Student’s Academic Performance using SVM. Journal of Engineering and Applied Sciences, 8(2), 61-61. [5] Sudha, D. N. (2021). Semi Supervised Multi Text Classifications for Telugu Documents. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 12(12), 644-648. [6] Sarkar, K. (2020). Heterogeneous classifier ensemble for sentiment analysis of Bengali and Hindi tweets. S?dhan?, 45(1), 196. [7] Naidu, R., Bharti, S. K., Babu, K. S., & Mohapatra, R. K. (2017, March). Sentiment analysis using telugu sentiwordnet. In 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET) (pp. 666-670). IEEE. [8] Samuel, J., Ali, G. M. N., Rahman, M. M., Esawi, E., & Samuel, Y. (2020). Covid-19 public sentiment insights and machine learning for tweets classification. Information, 11(6), 314. [9] Mukku, S. S. (2017). Sentiment Analysis for Telugu Language (Doctoral dissertation, PhD thesis, International Institute of Information Technology). [10] Chattu, K., & Sumathi, D. (2023, July). Sentiment Classification of Low Resource Language Tweets Using Machine Learning Algorithms. In 2023 2nd International Conference on Edge Computing and Applications (ICECAA) (pp. 1055-1061). IEEE. [11] Sultana, J., Rani, M. U., Aslam, S. M., & AlMutairi, L. (2021). Predicting indian sentiments of COVID-19 using MLP and adaboost. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 12(10), 706-714.
Copyright
Copyright © 2024 Komal Parashar, V. Durga Bhavani, V. Keerthana, R. Narasimha. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59508
Publish Date : 2024-03-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online