

Ijraset Journal For Research in Applied Science and Engineering Technology
Text Similarity Using Siamese Networks and Transformers
Authors: Bharath Chandra Chikoti, Kushwanth Jeelaga, Aryan Srivatsava Dande, Sunil Kumar
DOI Link: https://doi.org/10.22214/ijraset.2022.44283
Certificate: View Certificate
Abstract
In result-oriented conversational models like message renders and chatbots, finding the similarity between the input and output text result is a big task. In general, the conversational model developers lean to provide a minimal number of utterances per instance, and this makes the classification a difficult task. This problem becomes more difficult when the length of the processed text per action is short and length of the user input is long. Identical sentence pair detection reduces manual effort for users with high reputation. Siamese networks have been one of the best innovative architectures designed in the field of natural language processing. A Siamese network was initially designed for computer vision applications. Later the core concept of this algorithm was designed for NLP ,to identify similarity for two given sentences. Siamese networks are used in this algorithm. It\'s an artificial neural network also known as a twin neural network that works in tandem on two independent input vectors to calculate equivalent output vectors using the same weights. Also there are few commonly addressed drawbacks like word sense disambiguation and memory intolerance of initial inputs for sentences having more than 15-20 words. To tackle these issues, we propose a modified algorithm that integrates the transformer model implicitly with the core part of the siamese network. Transformer model helps to generate each output position based on the semantic analysis of overall sentence and can also deal with homonyms, by extracting its meaning based, which is syntactic based and semantic based on the overall sentence or paragraph or text.
Introduction
I. INTRODUCTION
Natural Language Processing-NLP, is computational linguistics branch of AI, is such a technology which is gaining the interest of many developers, scientific researchers as it got perfect blend of machine learning, language, and also artificial intelligence. Jaccard similarity and Cosine similarity are two methods for calculating syntactic similarity in text. With the enormous amount of textual information generated every day, NLP has piqued the interest of many developers and scientific researchers in the hope of developing methods to process this information in order to make it more efficient, accessible, and comprehensive. To describe by an example, in the domains, like newspaper articles, intellectual property, that involves a lot of textual data and paperwork, it is the task of NLP which will cluster the similar textual data and papers, which simplifies document analyses for the users. This kind service from NLP will increase productivity by reducing the processing time, and also this will also improve the precision with which large patent systems are handled and analyzed. Any document is generally divided into introduction, context, references, and description of pics or graphs. Usually the context and description are considered as the important part of a document, the introduction will summarize the overall technology described in the document. Similarity analysis of a document may include any of the structural parts including introduction, context, references, and others. But, in many cases, it is desirable that the documents with similar context can be clustered together for the analysis.
To find a solution to this problem, one must need insight to define the concept of similarity in a quantitative manner. In general, semantic similarity and syntactic similarity are two major similarity metrics encountered in text similarity analysis. Semantic similarity, on the other hand, is concerned with the interpretation-based similarity and meaning coherence of the two given texts. The idea behind syntactic similarity is that the similarity between two texts is proportional to the total number of identical words in them; however, precautions must be taken to ensure that the chosen method does not become biased towards the given text with a higher word count. While the syntactic similarity value can be calculated by constructing measures based on the word counts of the two inputs, the semantic analysis employs a more advanced method that employs word representations to extract meaning-based values for the two texts.. Before continuing with the analysis, the texts must be pre-processed to remove all unwanted tags, interpretation-based or other predefined characters or animated words. The pre-processed input text is thus reduced to the respective word roots, which are words, and lemmatization is performed on the text to be analyzed.
A significant part of NLP highly relies on the connection in high dimensional vectors. Generally an NLP processing will take any textual data, prepare it to generate a enormous vector or array rendering that text and then make required transformations.
II. RELATED WORK
For cQA, a Siamese Convolutional Neural Network was used. Deep convolutional neural networks are used as twin networks in the SCQA architecture, with a contrastive energy function at the top. Parameter sharing ensures that in the semantic space, the question and any relevant response are closer together, while the query and any irrelevant answer are far apart. For example, "President of the United States" and "Barack Obama" should be closer than "President of the United States" and "Tom Cruise lives in the United States." SCQA, which is frequently difficult to obtain in big quantities, requires similar question pairings. SCQA is made up of two deep convolutional neural networks (CNN) with convolution, max pooling, and rectified linear (ReLU) layers, as well as a fully connected layer at the top. CNN generates a nonlinear projection of the question and answer term vectors in semantic space. The semantic vectors that result are linked to a layer that computes their distance or similarity. The contrastive loss function combines the distance measure and the label. The gradient of the loss function is calculated using back-propagation with respect to the weights and biases shared by the sub-networks. The stochastic gradient descent method is used to update the parameters of the sub-networks.

The task of calculating the similarity between two texts utilizing both direct and indirect relationships is known as measuring semantic textual similarity. Siamese architectures are good for these jobs because it makes logical to use a similar model to handle comparable inputs when the inputs are similar. The networks will then have representation vectors with the same meanings, making it easy to compare phrase pairings. Because the weights are shared across sub networks, there are fewer parameters to train, resulting in less training data and a lower risk of overfitting. Given the amount of human-labour necessary to create STS datasets, Siamese neural networks may be the best option for the STS challenge.
III. PROPOSED SYSTEM
Information retrieval, text categorization, file clustering, topic detection, subject matter tracking, questions technology, query responding, essay scoring, rapid answer scoring, gadget translation, textual content summary, and others all use textual-content similarity measures. Finding word similarity is an important element of text similarity, which is subsequently utilized as a starting point for sentence, paragraph, and record similarity. In terms of lexical and semantic techniques, phrases can be comparable. If two words share the same character sequence, they are lexically related. Words are semantically comparable if they have the same component, have different meanings or semantics, are employed in the same way, and are used in the same context.
Multi-head interest is an attention mechanism module that runs through the mode of an attention mechanism many times in parallel. The independent interest outputs are then stacked horizontally or vertically, and the anticipated dimension is linearly converted. Multiple attention heads, intuitively, allow access to elements of the collection in a different way (e.g. longer-time period dependencies versus shorter-term dependencies).

IV. IMPLEMENTATION
A. Data Set Collection
The target of this undertaking part is to find out which of the feasible pairs of input sentences contain the inputs with the same which means. The labeling is the set of labels which have been manually detailed. The main truth labels are inherently detailed, as the genuine which means of inputs can by no means be identified with actuality. Manual labeling is likewise a 'noisy' manner, also affordable human beings will never accept. Hence end result, the ground reality outputs in the data is be considered to be 'knowledgeable' however not a hundred% precise, and can encompass false output labeling. We accept as true with the output labels, the whole part, to symbolize a meaningful consensus, but this will no longer be real in a case by means of case basis for man or woman gadgets with in the dataset. Textual content summarizing is a design to condense the big quantity of facts right into a reasonable shape by means of the technique of selection of critical data and removing irrelevant and redundant data. With this quantity of human language interpretable records which are inside the international wide area of textual content summarizable process is emerging to be very important.

B. Importing NLTK and Tokenizing Sentences
NLTK is a word tokenizer library which also has many other functions built in it. First one chooses the best question pairs that are duplicate to train the version of the original one. We construct two batches as input for the Siamese community and we count on that query q1i (query i inside the first batch) is a duplicate of q2i (question i inside the second batch), however all other questions in the second batch aren't duplicates in qli. The check set makes use of the authentic pairs of questions and the fame describing if the questions are duplicates.
C. Converting Tokens into a Tensor
This technique may be carried out in three steps ;
- Word mapping of textual content (token) to an index
- Creation of unique tokens for stop-of-sentence, padding and out-of-vocabulary symbols
- Conversion of phrases in the dictionary into tensors
The vocabulary will organize our facts in key: value pairs where the important thing will be the time period and the key indices
can be an integer index related to that time period. There may be unique tokens so one can have those traits
__PAD__: suggests the padding symbol. This work can be very useful because it will provide a template for the creation of the
input for our records generator in an smooth and efficient way.

D. Designing a Data Generator
Maximum of the time in Natural Language Processing, and AI in standard we use batches while education our statistics units. If stochastic gradient descent is used with one example at a time, it's going to take forever to build a model. In this case, it suggests tips on how to construct a information generator that takes in Q1 and Q2 and returns a batch of length batch_size inside the following format ([q11,q12,q13,...], [q21,q22,q23,...]). The tuple includes two arrays and each array has batch_size questions. again, q1i and q2i are duplicates, but they are no longer duplicates with every other factors within the batch.
The command next (data_generator) returns the next batch. This iterator returns the statistics in a layout that you may at once use for your model whilst computing the feed-forward of your algorithm. This iterator returns a couple of arrays of questions.
The generator must return shuffled batches of information of inputs from databases or memory. To acquire this without editing the real query lists, a list containing the indexes of the questions is created. This list can be shuffled and used to get random batches every time and whenever the index is reset.
E. Designing a Normalization Function
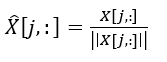
One needs to perform Scaling to unit duration shrinks/direction a vector (a column of facts can be considered as a N-dimensional vector form) to a single tensor. It is used on the entire data set, the converted statistics can be represented as a gaggle of one dimensional vectors with specific instructions towards the N-dimensional unit sphere.
Now, Generalizing/normalizing is certainly a large time period and every one of them will have execs and cons! I’ll most effective attention on improvisation in this text in any other case this article will go manner too long.
F. Designing a Siamese Model
A Siamese model is a network designed which uses the weights as same as before on the equal time as running in parallel
on two precise entry vectors to process same dimensional output vectors.
The question embedding is produced, run it via an LSTM layer, normalize v1 and v2, and ultimately use a triplet loss (defined under) to get the corresponding cosine similarity for each pair of questions. As conventional, it's miles started out by using importing the statistics set. The triplet loss uses a base (anchor) input vector that is now compared to a powerful (ground) entry and a irrelevant input. Gap due to the base (anchor) input vector to the extremely similar (ground) input is minimized, and the gap due to the base(anchor) input to the terrible enter is maximized. In math equations, the under proper hand expression must be maximized.
L(Anchor,Positive,Negative)=maxium(?f(Anchor)−f(Positive)?2−?f(Anchor)−f(Negative)?2+α(alpha),zero)
Here A is the anchor input, as an example q11, P the reproduction input, for example, q21, and N the bad input (the non-reproduction question), as an instance q22. α is a margin; you could reflect on consideration on it as a safety net, or with the aid of how masses you need to push the duplicates from the non-duplicates
G. Creating a Loss Function Using Mean , Closest Factors
One term makes use of the mean of all of the non-duplicates, the second makes use of the closest terrible. Our loss expression is then:
Loss1(A,P,N)=max(−cos(A,P)+mean_neg+α,0)
Loss2(A,P,N)=max(−cos(A,P)+closestneg+α,0)(three)Loss(A,P,N)=imply(Loss1+Loss2)

H. Training the Model and Loading the Parameters
Feature that takes for your model and trains it. To train your version you have to decide how usually you need to iterate over the entire records set; every generation is defined as an epoch. For every epoch, you need to pass over all the statistics, the usage of your training iterator.
? labeled_data=generator
? metrics=[tripletloss()],
? loss_layer=tripletloss()
? optimizer=trax.optimizers.adam ( with mastering fee of 0.01 )
? lr_schedule=lr_schedule,
? output_dir=output_dirGoogletrax standard training and eval task functions :
I. Importing the Trained Parameters of the Model
Import the parameters from the model that is built in the earlier stage.

J. Importing the Text Summarizer
Textual content filtering is a process to filter out the huge content of facts into a precise form by way of the system of finding and choosing of crucial statistics and removing useless and repetitive information facts. Along the quantity of this language data which is inside the global internet the region of textual content summarization is turning into very crucial. The excerpt summarization is the only in which the same sentences present inside the report are used as results.
The excerpt summarization is easier and is the overall exercise most of the automated text filtration experts at the existing time. Excerpt filtration method entails giving rankings to inputs the use of a few approach after which the use of the sentences that gain top scores as filtered short length outputs. As the exact sentence present inside the file is used the text component can be absented which ends up in technology of low observation in depth filtration method. That form is typically unsupervised also language independent too. Also the fact that this sort of summarized part does its work in transmitting the crucial sequence it could not be always easy or fluent. On this occasion there can be no connection among contiguous sentences inside the accurate resulting in the copy lost in readability.
K. Generating the Summarized Sentences
T5 is a brand new transformer version from Google this is educated in an give up-to-stop way with textual content as input and changed textual content as output. It achieves some effects on a couple of NLP responsibilities like summarization, question answering, device translation, more the usage of a text-to-textual content transformer skilled on a massive text corpus. Transformers is used as a version from libraries to summarize any given text. T5 is an abbreviative summarization algorithm. It manner that it's going to rewrite sentences whilst important than just choosing up sentences immediately from the authentic text.

The paragraphs will be summarized using the imported text summarizer and then after purely preprocessing the summarized output sentences , Siamese model will be given these sentences and input and similarity will be obtained in a scale of 0-1 . The more the result is closer to 1,the more the similarity
VI. ACKNOWLEDGEMENT
We convey our sincere thanks to all the faculties of ECM department, Sreenidhi Institute of Science and Technology, for their continuous help, co-operation, and support to complete this project.
We are very thankful to Dr. D. Mohan, Head of ECM Department, Sreenidhi Institute of Science and Technology, Ghatkesar for providing an initiative to this project and giving valuable timely suggestions over our project and for their kind cooperation in the completion of the project.
We convey our sincere thanks to Dr.T.Ch. Siva Reddy, Principal, and Chakkalakal Tommy, Executive Director, Sreenidhi Institute of Science and Technology, Ghatkesar for providing resources to complete this project. Finally, we extend our sense of gratitude to almighty, our parents, all our friends, teaching and non- teaching staff, who directly or indirectly helped us in this endeavor
Conclusion
However there are algorithms and other software applications that determine the similarity between two texts but this algorithm makes use of Siamese Networks and transformer summarizer together to deal with lengthy paragraphs and also this can be fatherly extended and integrated with many other projects like chat auto-prototype answer generation and optimization for named entity recognition as mentioned earlier
References
[1] Lev V. Utkin, Maxim S. Kovalev, and Ernest M. Kasimovc . An explanation method for Siamese neural networks . July 2017. [2] Wael-Gomaa, Aly-Fahmy . A Survey of Text Similarity Approaches . April 2013. [3] Xingping Dong and Jianbing Shen . Triplet Loss in Siamese Network for Object Tracking . 2017. [4] Ming Zhong ,Pengfei Liu , Yiran Chen, Danqing Wang, XipengQiu , Xuanjing Huang . Excerptive Summarization as Text Matching . 19 Apr 2020. [5] Jianpeng Cheng, Li Dong and Mirella Lapata .Long Short-Term Memory-Networks for Machine Reading . 20 Sep 2016. [6] Ashish Vaswani, Noam Shazeer, Niki Parmar and Aidan N. Gomez . Attention Is All You Need . 2018. [7] Paul Neculoiu, Maarten Versteegh and Mihai Rotaru. Learning Text Similarity with Siamese Recurrent Networks. August 2016. [8] Arpita Das, Harish Yenala, Manoj Chinnakotla, and Manish Shrivastava. Together We Stand: Siamese Networks for Similar Question Retrieval. August 2016. [9] Tharindu Ranasinghe, Constantin Or?asan and Ruslan Mitkov. Semantic Textual Similarity with Siamese Neural Networks.September 2019.
Copyright
Copyright © 2022 Bharath Chandra Chikoti, Kushwanth Jeelaga, Aryan Srivatsava Dande, Sunil Kumar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET44283
Publish Date : 2022-06-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online