

Ijraset Journal For Research in Applied Science and Engineering Technology
Transformers in Natural Language Processing: A Comprehensive Review
Authors: Mohd Arsalan, Syed Azeem Raza, Er. Aayush Pratap Singh
DOI Link: https://doi.org/10.22214/ijraset.2024.62863
Certificate: View Certificate
Abstract
This research paper provides a comprehensive review of transformers, a groundbreaking architecture in Natural Language Processing (NLP), and their impact on the field. We delve into the unique ability of transformers, with their attention mechanisms, to capture complex linguistic dependencies and process sequences effectively. This enables them to grasp contextual nuances, syntactic structures, and semantic intricacies inherent in human language, outperforming traditional models. This review explores the transformer architecture, various pre-trained language models based on it, and their diverse applications in multilingual NLP. We further discuss fine-tuning and transfer learning techniques for adapting transformers to specific tasks, recent developments, challenges, open problems, and future directions. This comprehensive analysis aims to contribute to a deeper understanding of how transformers have revolutionized NLP, offering insights into their potential for shaping the future of language understanding and generation.
Introduction
I. INTRODUCTION
A. Overview
Transformers represent a revolutionary approach in Natural Language Processing (NLP), strategically designed to tackle intricate linguistic challenges. Unlike traditional models, transformers introduce a paradigm shift by relying on attention mechanisms, enabling them to capture long-range dependencies and contextual relationships within language. This innovative architecture excels in processing sequences, making it particularly adept at handling the complexity of human language. By embracing self-attention mechanisms, transformers can consider all positions in a sequence simultaneously, allowing for a more holistic understanding of context. This not only enhances the accuracy of linguistic analysis but also empowers models to grasp subtle nuances, syntactic structures, and semantic intricacies, marking a transformative leap in addressing the inherent complexities of linguistic variation.
B. Importance
Transformers hold profound importance in linguistic review papers on Natural Language Processing (NLP), revolutionizing language understanding. Their attention mechanisms enable a holistic grasp of linguistic nuances, addressing challenges posed by variations, dialects, and cultural diversity. By capturing intricate dependencies, transformers enhance accuracy and contextual relevance, making them pivotal in applications like sentiment analysis and machine translation. As linguistic models evolve, transformers emerge as a transformative force, fostering inclusivity and cultural intelligence in NLP systems, thereby reshaping the landscape of linguistic research and understanding.
Transformers have revolutionized NLP research and applications due to their ability to effectively capture complex linguistic dependencies. This capability significantly improves performance in various tasks, including:
- Sentiment Analysis: Transformers excel at capturing nuances in sentiment across languages, enabling more accurate analysis of user opinions and emotions.
- Machine Translation: By understanding the context and relationships between words, transformers facilitate more accurate and fluent translations between languages.
- Question Answering: Transformers can effectively process both questions and large amounts of text to identify the most relevant and accurate answers.
- Text Summarization: Transformers can identify the most important information in lengthy texts and generate concise and coherent summaries.
C. Scope And Objectives
The scope of this linguistic review paper on transformers in Natural Language Processing (NLP) encompasses an in-depth exploration of how transformers address linguistic challenges. It delves into the architecture, applications, and advancements of transformers, focusing on their role in understanding and generating diverse languages, dialects, and cultural nuances. The objectives are to elucidate the transformative impact of transformers on linguistic modeling, examine their proficiency in handling linguistic variations, and highlight their contributions to more culturally aware and inclusive NLP systems. This research paper provides a comprehensive review of transformers in NLP, covering their architecture, applications, recent developments, challenges, and future directions. The objectives are:
- To provide a detailed understanding of the transformer architecture and its underlying mechanisms.
- To explore various pre-trained language models based on transformers and their applications in different NLP tasks.
- To discuss the techniques and challenges associated with fine-tuning and transfer learning for adapting transformers to specific tasks.
- To highlight recent developments and emerging trends in transformer-based NLP research.
- To identify challenges and open problems in the field and suggest potential future directions.
II. TRANSFORMER ARCHITECTURE
Transformer architecture in NLP
A. Input Embedding
- Represents words or tokens as vectors.
- Adds positional encoding to convey word positions in a sequence.
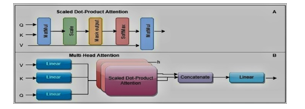
B. Multi-Head Self-Attention
- Divides the input into multiple heads, allowing the model to attend to different parts of the input simultaneously.
- Captures dependencies between words regardless of their relative distance.
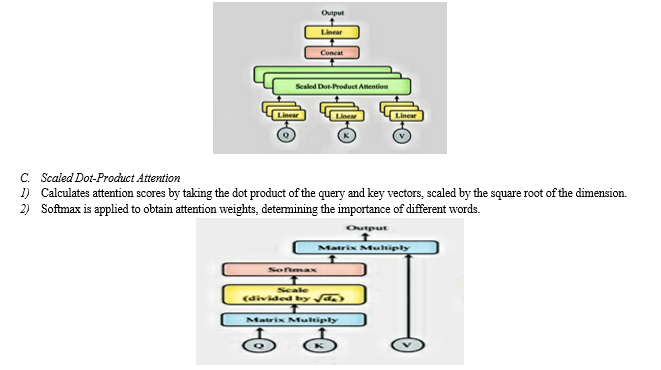
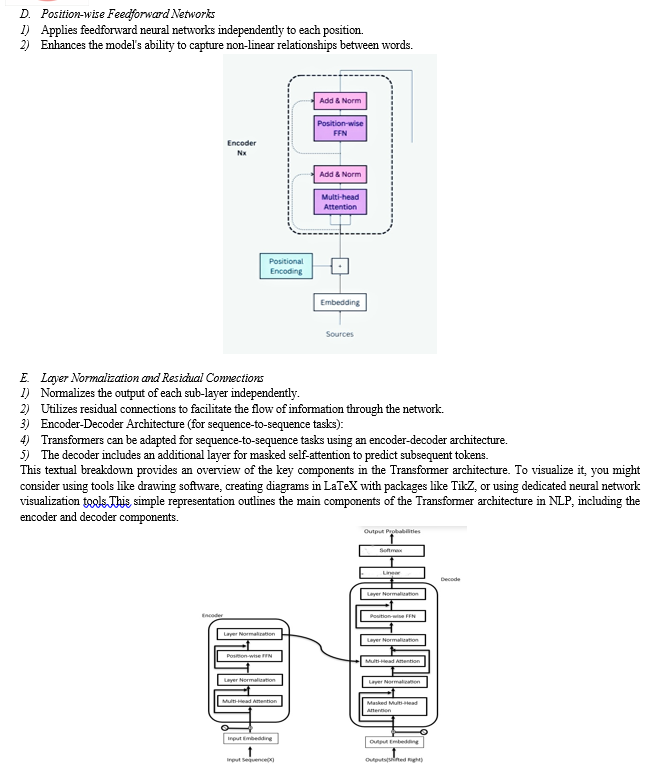
III. PRE-TRAINED LANGUAGE MODELS
The advent of transformers has given rise to a new era in NLP, marked by the development of powerful pre-trained language models. These models, often trained on vast corpora of text, have demonstrated remarkable capabilities in capturing contextual information and linguistic nuances. Notable among them are:
- BERT (Bidirectional Encoder Representations from Transformers): Introduced by Google, BERT revolutionized NLP by capturing bidirectional context during training. Its pre-training tasks involve masked language modeling, allowing the model to understand context by predicting missing words.
- GPT (Generative Pre-trained Transformer) Series: Developed by OpenAI, the GPT series, including GPT-2 and GPT-3, focuses on generative tasks. GPT-3, with a staggering 175 billion parameters, holds the distinction of being one of the largest language models, showcasing unprecedented language generation capabilities.
- XLNet: An amalgamation of autoregressive and autoencoding approaches, XLNet, proposed by Google, addresses limitations of traditional pre-training methods. It leverages permutation language modeling to capture bidirectional context while maintaining a generative model.
- RoBERTa (Robustly optimized BERT approach): Developed by Facebook AI Research, RoBERTa optimizes BERT's training objectives and hyperparameters for improved performance. It excludes the next sentence prediction task and significantly scales up training data.
- T5 (Text-to-Text Transfer Transformer): Introduced by Google Research, T5 adopts a unified text-to-text framework for various NLP tasks. Its versatility lies in framing all tasks as converting input text to target text, offering a consistent and flexible approach.
The review of pre-trained language models explores the architecture, training strategies, and impact of transfer learning on downstream NLP tasks. These models, trained on extensive datasets, have demonstrated remarkable performance across a spectrum of applications, from sentiment analysis to machine translation, marking a paradigm shift in NLP methodologies. Their exploration sets the stage for understanding the advancements and challenges in harnessing pre-trained language models within the broader context of transformer-based NLP research.
IV. APPLICATIONS IN MULTILINGUAL NLP
Transformers have proven to be highly effective in Multilingual NLP, demonstrating versatility in addressing linguistic diversity. The applications span various domains, underscoring the transformative impact of these models.
A. Sentiment Analysis
- Transformers excel in sentiment analysis across multiple languages, capturing the nuances of positive, negative, or neutral sentiments with high accuracy.
- Multilingual sentiment analysis is particularly valuable for understanding user opinions in a globalized context.
B. Named Entity Recognition (NER)
- NLP models based on transformers are adept at identifying named entities in diverse languages.
- Their contextual understanding enables precise recognition of entities such as names, locations, and organizations across various linguistic variations.
C. Machine Translation
- Transformers have significantly advanced machine translation, facilitating seamless communication across language barriers.
- Models like MarianMT and mBART leverage transformer architectures to achieve state-of-the-art results in multilingual translation tasks.
D. Cross-Lingual Information Retrieval
- Transformers contribute to improved cross-lingual information retrieval, enabling users to access relevant information in their preferred language.
- Multilingual models enhance search experiences by understanding and retrieving content in various languages.
E. Question-Answering Systems
- Multilingual transformers demonstrate prowess in question-answering tasks, providing accurate and contextually relevant responses across different languages.
- Models like mBERT and XLM-R leverage pre-training on multilingual data for enhanced performance.
F. Document Classification
- Transformers are applied to multilingual document classification tasks, where they categorize documents into predefined classes.
- Their ability to capture contextual information contributes to improved accuracy in understanding the content of documents across languages.
G. Semantic Similarity and Paraphrase Detection
- Multilingual transformers enhance semantic similarity and paraphrase detection tasks, aiding in applications like duplicate content identification and document matching.
- These models excel in capturing semantic relationships between sentences in different languages.
H. Speech Recognition and Language Understanding
- Transformers are employed in multilingual speech recognition systems, enabling accurate transcription and understanding of spoken language.
- Their capacity to handle diverse linguistic features contributes to improved performance in speech-related applications.
Exploring these applications underscores the efficacy of transformers in Multilingual NLP, offering a comprehensive understanding of their impact on various tasks and showcasing their potential for fostering global linguistic inclusivity.
V. FINE-TUNING AND TRANSFER LEARNING
Fine-tuning and transfer learning strategies play a pivotal role in optimizing the performance of transformer models for specific Natural Language Processing (NLP) tasks. This section delves into the techniques and challenges associated with adapting pre-trained transformer models to target applications.
A. Transfer Learning Paradigm
The concept of Transfer Learning (TL) is defined by Matt as the reuse of pre-existing models to address current challenges, emphasizing the utilization of prior training data to enhance ongoing tasks without starting from scratch. Daipanja aligns with this definition, comparing it to traditional Machine Learning where each task was developed independently, highlighting TL's focus on leveraging previous knowledge for enhanced performance.
Yoshua et al. further elaborate TL as training current models using pre-trained models from similar tasks, reflecting a consensus on the broader understanding of the technique. Additionally, Jason characterizes TL as an optimization tool elevating the performance of modeling for the second task.
Transfer Learning offers several advantages, notably improved efficiency and the ability to handle data scarcity. By leveraging pre-existing models and knowledge, TL allows for more efficient training processes, reducing the need for extensive new data. This proves particularly beneficial in scenarios where data availability is limited, enabling models to generalize and adapt effectively to new tasks.
The diverse perspectives presented by these authors collectively underscore the significance of Transfer Learning in optimizing model performance and addressing challenges in contemporary machine learning applications.
VI. RECENT DEVELOPMENTS AND FUTURE DIRECTIONS
The Transformer architecture has demonstrated superior effectiveness compared to its predecessors, such as CNN/RNN-based solutions. Initially designed to address sequence-to-sequence problems, the primary motivation behind the Transformer was to introduce parallelization and enable the encoding of long-range dependencies in sequences. By reducing the number of sequential operations to a constant O(1) for relating symbols in input/output sequences, the Transformer sparked a paradigm shift in sequence processing approaches, establishing itself as a predominant trend in research.
While the Transformer's initial applications focused on enhancing NLP tasks like language translation, recent years have witnessed its expansion into the realm of computer vision. This paper explores the latest advancements in Transformer-based architectures for computer vision applications. Notably, it highlights the significance of the minimized presence of non-learned inductive bias in Transformers, emphasizing its importance in achieving remarkable performance in computer vision tasks.
Source: [Exploring Recent Advancements of Transformer Based Architectures in Computer Vision]
(https://www.researchgate.net/publication/360066821_Exploring_Recent_Advancements_of_Transformer_Based_Architectures_in_Computer_Vision)
VII. CHALLENGES AND OPEN PROBLEMS IN TRANSFORMER MODELS
Critically examining challenges encountered by transformer models, reflecting on their implications and suggesting potential avenues for improvement. Key challenges include:
- Computational Demands: Discusses the resource-intensive nature of transformer models, emphasizing the high computational demands during training and inference. Explores strategies to enhance efficiency and reduce computational costs, ensuring broader accessibility.
- Interpretability: Addresses the inherent complexity of transformer models, often considered as "black-box" systems. Discusses the challenge of interpretability and the need for transparent model architectures to enhance trust and understanding.
- Ethical Considerations: Explores ethical concerns associated with transformer models, including biases in training data and potential societal impacts. Discusses the importance of responsible AI practices and the development of frameworks to mitigate ethical risks. Open problems in the field that require further investigation include:
- Handling Long-Term Dependencies: Explores methods to improve the handling of long-term dependencies in transformer models. Discusses advancements in attention mechanisms and memory-augmented models for more effective context capture.
- Cross-Modal Learning: Highlights the challenge of integrating information from multiple modalities, such as text and images, in a cohesive manner. Encourages research into cross-modal transformer architectures for a more holistic understanding of multimodal data.
- Robustness to Adversarial Attacks: Addresses the vulnerability of transformer models to adversarial attacks. Encourages research into robust architectures and training methodologies to enhance model security.
Conclusion
In conclusion, this review consolidates key findings on the transformative impact of transformers in Natural Language Processing (NLP). From their inception as a solution to parallelize sequence-to-sequence problems and handle long-range dependencies, transformers have revolutionized NLP, surpassing the efficacy of previous CNN/RNN-based solutions. The minimized presence of non-learned inductive bias in transformers has not only enhanced sequence transduction tasks but has also propelled their application into computer vision. Despite their successes, challenges persist, including computational demands, interpretability issues, and ethical considerations. As transformers continue to dominate NLP, future research avenues should address challenges and explore opportunities for improvement. This includes efficient handling of long-term dependencies, cross-modal learning for multimodal applications, and robustness against adversarial attacks. The impact of transformers extends beyond performance improvements; it reshapes the landscape of natural language understanding. This review underscores the importance of ongoing research and development to harness the full potential of transformers, ensuring their continued transformative role in NLP. As the field evolves, the journey of transformers in NLP promises to be a beacon of innovation, guiding future breakthroughs and advancements.
References
[1] Author: Renu Khandelwal Link:https://towardsdatascience.com/simple-explanation-of-transformers-in-nlp-da1adfc5d64f [2] Author: Mohammad Ali Humayun, Hayati Yassin, Junaid Shuja, Abdullah Alourani & Pg Emeroy lariffion Abas Link:https://link.springer.com/article/10.1007/s00521-022-07944-5 [3] Author: Micha? Chromiak Link:https://www.researchgate.net/publication/360066821_Exploring_Recent_Advancements_of_Transformer_Based_Architectures_in_Computer_Vision [4] Author: Jacky Casas, Elena Mugellini, Omar Abou Khaled Link:https://www.researchgate.net/publication/346111006_Overview_of_the_Transformer-based_Models_for_NLP_Tasks [5] Author: Ilia Sucholutsky, Apurva Narayan Link:https://www.researchgate.net/publication/335126813_Pay_attention_and_you_won%27t_lose_it_a_deep_learning_approach_to_sequence_imputation [6] Author: Narendra Patwardhan, Stefano Marrone, Carlo Sansone Link: https://www.mdpi.com/2078-2489/14/4/242 [7] Author: Abdul Ahad, Mir Sajjad Hussain Talpur, Awais Khan Jumani Link:https://www.researchgate.net/publication/363732809_Natural_Language_Processing_Challenges_and_Issues_A_Literature_Review [8] Author: Haifeng Wang, Hua Wu, Eduard Hovy , Yu Sun Link:https://www.sciencedirect.com/science/article/pii/S2095809922006324 [9] Author: Jiajia Duan, Hui Zhao, Qian Zhou, Meiqin Lui Link:https://www.researchgate.net/publication/347211036_A_Study_of_Pretrained_Language_Models_in_Natural_Language_Processing [10] Author: Ashish Vaswani, Illia Polosukhin, Noam Shazeer, ?ukasz Kaiser Link:http://papers.nips.cc/paper/7181-attention-is-all-you-need [11] Author: Alec Radford, Dario Amodei, Ilya Sutskever, Jeffrey Wu Link:https://www.ceid.upatras.gr/webpages/faculty/zaro/teaching/alg-ds/PRESENTATIONS/PAPERS/2019-Radford-et-al_Language-Models-Are-Unsupervised-Multitask-%20Learners.pdf [12] Author: Jacob Devlin, Kenton Lee, Kristina Toutanova, Ming-Wei Chang Link: https://arxiv.org/abs/1810.04805
Copyright
Copyright © 2024 Mohd Arsalan, Syed Azeem Raza, Er. Aayush Pratap Singh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62863
Publish Date : 2024-05-28
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online