

Ijraset Journal For Research in Applied Science and Engineering Technology
Unmasking Disinformation: Advanced Techniques for Fake News Detection and Mitigation
Authors: Saurabh Srivastava, Nitasha , Akansha , Mudit Surana, Hardik Singh, Harsh Sangtani
DOI Link: https://doi.org/10.22214/ijraset.2023.56974
Certificate: View Certificate
Abstract
With the current increase in social media usage, everyone is very concerned about the spread of misleading information. Misinformation has been employed to sway public opinion, impact the 2016 US Presidential Election, and disseminate animosity and turmoil, such the genocide against the Rohingya people. A 2018 MIT study found that on Twitter, bogus news spreads six times faster than real news. In addition, there is now a problem in the news media\'s reliability and credibility. It is getting harder and harder to tell the difference between the morphed and true news, and for the evaluation of this study, a combination of various machine learning techniques, methods along with the natural language processing (NLP), LSTM, and passive aggressive classifier (PAC), to distinguish between bogus and authentic news and these two have shown to be the most successful machine learning models, despite the availability of many others.
Introduction
I. INTRODUCTION
The world is evolving quickly. Without a question, living in a digital age has many benefits, but there are drawbacks as well. The purpose of spreading fake news is to damage someone's or an organization's reputation. It might be disinformation against an individual, group, or political party. One can disseminate false information on a variety of internet venues. This applies to Twitter, Facebook, and so on, the other things that comes into importance is machine learning which is also known as branch branch of the artificial intelligence is responsible for creating computers with the ability to learn and execute various tasks. There are numerous machine learning algorithms accessible, such as reinforcement learning, unsupervised learning, and supervised learning algorithms. All the algorithms must be trained in this process and after training, these algorithms can be used for a wide range of tasks. Many sectors are using machine learning for a range of activities. Online platforms benefit users since they make it easy for them to obtain news. But this is a problem since it gives hackers access to these platforms to spread misleading information . The primary components of the current false news detection method's operation are message contents, distribution patterns, and user characteristics used to train the binary classifier, also SVM,RF and a lot of techniques are examples of frequently used classifiers. Additionally, the identification process incorporates additional information such as user comments, time series structures, and emotional attitudes. However, the primary technique used in these systems is feature:
- Morphism: The purposeful absence of information, which usually only comes from one source, is known as "morphed news”, in this case the person who sends the message known as source does not know that the thing is real or not.
- Hoax: More sophisticated deception strategies are used in this type of reporting to mislead the public. Numerous sources spread false information and some individuals group believe it to be true without verifying.
- Satire: fake news that the provider presents as amusing. When you distribute satire to those who don't know where the material came from.
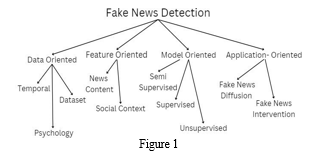
The following are the conclusions of a study on the identification of false news, which was carried out by some researchers using a variety of methodologies: -
a. Information-based: An article's claims are accurately valued in light of mitigating circumstances through the application of information-based approaches, such as truth-checking information evaluations with the aid of additional resources.
b. Design-based: Design-based methods use the writing style to identify bogus news. Generally speaking, style- based approaches fall into two primary categories: deception-oriented and objectivity-oriented for future.
c. Situation-based: This technique uses readers' opinions from all related as well as old contents to confirm that the news reports are authentic.
II. RELATED WORK
The majority of fake news publishers would use a particular writing style and disseminate false material in an effort to appeal to and influence a broad audience, which would not likely way it would in actual news. Thus, behavior-based identification approach is an effort to identify the precise manipulator of the composition style. Lately, the complex rhetorical structure and parsing of misleading information are recognised using an advanced natural language processing model. One software of conduct-based totally faux information detection is the identity of faux news vendors' writing styles by herbal language processing (NLP). the use of a dataset of actual information, herbal language processing (NLP) fashions may be trained to pick out the diffused variations in writing patterns between actual and faux information. After being taught, the NLP model can be used to recognise the writing style of fresh fake news items.Utilising social media research to pinpoint the actions of fake news providers and their supporters is an additional method for putting behavior-based fake news detection into practise.
A. Detection According to News Content
The proposed fake news detection system by Lin, C.Delta- G, improves accuracy by extracting diffusion structure and growth rate information using graph convolutional networks andlong- shortterm memory networks.The study examines traits, traits, taxonomy, and detection algorithms for identifying false information. The study uses probabilistic latent semantic analysis to identify fake news.(1). Models mostly based on switch research were analysed and developed to improve predictions of bogus information in a paper proposed by Tahseen Dhannoon and this task uses deep learning and pre-educated models to anticipate false information in both Arabic and English, a mixed network that combines MLP, BiGRU, and CNN models is advised against. Similarly, an enhanced random forest variant is built using the pre-skilled BERT model and speaker-based features, so that to identify bogus news, Asif Ali and colleagues [3] described linguistic characteristics and a bi-lstm. With over 2.7 billion active Facebook users globally, social media usage has significantly expanded. On the Fake News dataset, a suggested model including linguistic characteristics and bidirectional long short- term memory had an accuracy of 98.52%. On multi-clas datasets,however, the proposed technique might not produce sufficient results. According toAura "epulionyt"user behavior on the Internet offers useful insights and is essential forcommunication and information exchange.The goal of the paper is to lessen the negative effects of poisonous, hostile, insulting, and malicious information in social media by proposing a multilayered preprocessing strategy to identify and classifyhazardous social network messages.[4]EFND was described by Muhammad Nadeem and colleagues in 2022. Methods that are social context-aware and context-aware in context are frequently employed to identify fake news. To recognize fake news stories, the suggested model incorporates textual, contextual, social, and visual elements. On the FakeNewsNet dataset, the model obtains good accuracy.[5] The paradigm is substantially more effective when content-based approaches and social context are combined. Because fake information on social media and other study platforms can have negative social and national effects, it is important to understand how to deal with it, so our suggested model uses tools like Python Scikit-Learn and Natural Language Processing (NLP) for textual analysis, including function extraction and vectorization, fake news is becoming more and more of a problem on the internet and social media since individuals frequently share false information without question. Both society and individuals[7] may suffer as a result. In an effort to sway public opinion, some websites publish fake material on purpose under the pretext of being factual news. A new area of research receiving interest internationally is that of Arvinder Bali told all colleagues investigated that Gradient Boostingfared better than other classifiers, with an calculated F1- Score of 0.91 and an accuracy of 88%, so for the purpose of studying the intricate media landscape[8].The characteristics and patterns of false newshave been uncovered through research, and certain models have proved successful in telling the difference between the two. [9] These models, which are based on certain traits designed for spotting particular kinds of fake news, let us assess digital information and draw defensible judgments.
According to System' by Sunil Mamidi[10] recent technological developments in online social networks have increased the transmission of misleading information and fake news. Rapidly identifying bogus news can make the general population feel less anxious and confused. In this article, the authors suggest a methodology for evaluating the accuracy of COVID-19 data that is disseminated on social media. They use three transformer models of bogus news to recognise fake news., after that news verification is a significant topic in library and information science, according to Niall Conroy and colleagues in their article "Automatic deception detection". The article offers a typology of ways for determining authenticity, includingnetwork analysis approaches and language cue approaches.[11] In categorization challenges, linguistic and network-based techniques have demonstrated great accuracy
B. Social Background-based Detection
In research, deep learning is used to address the issue of identifying false news, that gave the results with an accuracy of 94.21% on test data, the authors [12] present an integrated neural network that is 2.5% more accurate than earlier models in predicting the relationship between names and tags, also the Fake news detection is necessary, as evidenced by the sharp rise in its production by the honorable authors Deshpande, GC; Hiramath, Chaitra K.13] a strategy, was developed that classifies different types of information from the Internet and social media in order to identify fake news, but public may become confused by fake news, and political leaders may suffer as a result. For the purpose of identifying bogus news, the system contrasts various machine learning methods. False information detection is frequently approached as a binary classification problem. To minimize the such problem a large size of dataset is used. Large volumes of data are categorized by some firms using deep learning techniques on databases that contain both fake and real information articles, after that on the various platforms on internet as well as on social media, detection of the false news is a rising and with a negative problem because people frequently distribute false information without thinking. Both society and individuals may suffer as a result. In an effort to sway public opinion, some websites publish fake material on purpose under the pretext of being factual news. [14] To solve this problem, preventative actions must be taken. Algorithms powered by artificial intelligence can identify and expose phony news. Most fake news detection systems use linguistic features to identify fake news. Our system proposes a new matching technique that combines article abstraction, entity matching, and BiMPM to improve fake news detection, after that the researchers were attempting to detect and validate fake news because false information has grown to be a significant problem in society because our system utilizes a deep learning model, BiMPM, but also overcomes its limitations by incorporating[15] article abstraction and entity matching. This new system improves overall performance in detecting fake news.
III. DATASET DESCRIPTION
A key component of this research project is the dataset that was used to build the Fake News Detection System. The aforementioned dataset was carefully selected and obtained from Kaggle, a well-known website that is well-known for having a large library of open-source datasets and data science resources with the number one awareness of the dataset is the crucial undertaking of differentiating between authentic, actual news and the unsettling spread of fake information, a hassle that is extremely critical to society inside the current era of information. Through their persistent labour, the guardians of this precious dataset, Traore I, Ahemd H, and Saad S, have shown an intense commitment to advance the discipline of misinformation detection. Their work has established the groundwork for the validation of false news identification systems through empirical investigation of theirefficiency.
Table 2
|
Title |
Title |
Category |
Date |
|
As the US budget battle approaches, Republicans rewrite their fiscal blueprint |
The leader of the US Congress's hardline Republican group, who cast a ballot... |
ElectionsNe ws |
December 31, 2017 |
|
On Monday, the US military will begin accepting transgender recruits: Dimitry |
For the first time, transgender individuals will be able to enrol in the US military. |
ElectionsNe ws |
December 29, 2017 |
Table 1
|
Title |
Title |
Category |
Date |
|
Donald Trump Issues Stupid New Year's Eve Message: This Is Worrying for all the public of the United States |
Donald Trump was unable to wish a happy New Year to everyone in the United States. |
ElectionsNews |
December 31, 2017 |
|
Trump Staffer Who Started Russian Collusion Investigation While Drunk and Bragging |
Devin Nunes, the chairman of the House Intelligence Committee, is not going to have a good day. |
ElectionsNews |
December 31, 2017 |
Table 1 describing the dataset of fake news and true news or the real news respectively from the given CSV data file.

Table 2 contains some samples of false information identification from the English dataset, in this we present the most frequent word cloud of the true and false information points after removing the forestall words from Figures 2(a) and 2(b)also in that certain terms that are frequently found in the phoney articles—words like "vote," "obama," "congress," "attempting," "Monday," and "12 months," for example—but are infrequently found in the actual classified record points can be seen in separation (a) among the actual classified data points. Some of those specific terms are "Russia," "human beings," "stated," "country," "White House," and "Donald Trump," among others so these frequently occurring terms within the text can offer crucial information that helps separate fact from fiction and solve.
IV. METHODOLOGY
The procedure used to create the false News Detection System was painstakingly designed with the goal of reaching the highest level of accuracy and dependability in recognising false news. The procedure starts with a comprehensive data preprocessing step that includes word embedding, tokenization, and text data cleaning to transform textual data into numerical representation. The next stage, feature extraction, improves the model's semantic and contextual comprehension. The selection of deep learning and machine learning models is crucial. Various models, including logistic regression, support vector machines, CNNs, and RNNs, are assessed based on how well they categorise fake news. Cross-validation and repeated model improvement are made possible by the essential procedures of training and validation.
A. Data Pre-processing
The vital first step in creating the Fake News Detection System is data preparation, which guarantees the consistency and quality of the dataset. Comprehensive text cleaning processes are the first step in this approach. All text is converted to lowercase to prevent case-related errors; punctuation is removed to decrease noise; and stop words, including "the" and "is," are removed to reduce dimensionality and highlight more important keywords. Tokenization is used to divide the text into individual words or subword units after text cleaning. This crucial stage divides the textual data into digestible chunks so that additional analysis and numerical representation can be applied. Text is transformed into tokens, which enables us to lay a systematic framework for the methodology's later phases.Word embeddings are used in feature extraction, a crucial step in data preprocessing. Applying methods such as Word2Vec, GloVe, or FastText allows for the tokenized text data to be transformed into dense vector representations. The model is able to comprehend the meaning and relationships between terms inside the text since these embeddings contain semantic information and word context. By doing this step, the model becomes more adept at spotting minute linguistic patterns that point to false news.To put it simply, data preparation is the first step towards useful analysis when it comes to detecting fake news,it provides structure and refinement to the unstructured textual facts, allowing system learning and deep learning algorithms to be used, also creates a strong foundation for the later stages of the methodology.
B. Evaluation Metrics
Regarding the Fake News Detection System, the assessment metrics are essential for measuring the effectiveness and dependability of the system. Our models' effectiveness is assessed using a range of carefully chosen evaluation measures. These metrics function as the benchmarks used to evaluate the system's capacity to distinguish between authentic and fraudulent news. Together, these assessment criteria help us optimize the Fake News Detection System to minimise false positives while catching as many instances of fake news as possible, improving the accuracy and dependability of the system.



Conclusion
In operation to stop the spread of false information, news detection technologies are crucial. Fake news is a significant issue in today\'s society. We have examined a range of fake news detection techniques in this review study, including hybrid, deep learning, and machine learning models.It has been shown all The numerous trained models can analyze news with reasonable degree of accuracy; however, they may be prone to overfitting and may not adapt well to new data. Although deep learning models have demonstrated encouraging results in the identification of fake news, training and using them can be computationally costly. The best of both worlds may be achieved by hybrid models, which mix deep learning and machine learning methods to provide high accuracy and generalisation capabilities.
References
[1] Chen, J., Jia, C., Li, Q., Zheng, H., Zhao, W., Yan, M. and Lin, C. (2022) Research on Fake News Detection Based on Diffusion Growth Rate, Wireless Communications and Mobile Computing. [2] N. Smitha and R. Bharath, \"Performance Comparison of Machine Learning Classifiers for Fake News Detection,\" 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2020 pp. 696-700, doi: 10.1109/ICIRCA48905.2020.9183072. [3] Mishra, S., Shukla, P. and Agarwal, R. (2022) Analyzing Machine Learning Enabled Fake News Detection Techniques for Diversified Datasets, Wireless Communications and Mobile Computing. [4] C. K. Hiramath and G. C. Deshpande, \"Fake News Detection Using Deep Learning Techniques,\" 2019 1st International Conference on Advances in Information Technology (ICAIT), Chikmagalur, India, 2019, pp. 411-415, doi: 10.1109/ICAIT47043.2019.8987258. [5] Wotaifi, T. A. and Dhannoon, B. N. (2023) Developed Models Based on Transfer Learning for Improving Fake News Predictions, JUCS. Journal of Universal Computer Science. [6] Zhao, J., Zhao, Z., Shi, L., Kuang, Z. and Liu, Y. (2023) Collaborative Mixture-of-Experts Model for Multi- Domain Fake News Detection, MDPI. Multidisciplinary Digital Publishing Institute. [7] Ali, A. A., Latif, S., Ghauri, S. A., Song, O.-Y., Abbasi, A. A. and Malik, A. J. (2023) Linguistic Features and Bi-LSTM for Identification of Fake News, MDPI. ?epulionyt?, A., Toldinas, J. and Lozinskis, B. (2023) A Multilayered Preprocessing Approach for Recognition and Classification of Malicious Social Network Messages, MDPI. Multidisciplinary Digital Publishing Institute. [8] Salini, Y. and Harikiran, J. Fusion Model for Detecting (2023) Multiplicative Vector Deepfake News in Social Media, MDPI. Multidisciplinary Digital Publishing Institute. [9] Nadeem, M. I., Ahmed, K., Li, D., Zheng, Z., Alkahtani, H. K., Mostafa, S. M., Mamyrbayev, O. and Abdel Hameed, H. (2022) EFND: A Semantic, Visual, and Socially Augmented Deep Framework for Extreme Fake News Detection, MDPI. Multidisciplinary Digital Publishing Institute. [10] Khanam, Z., Alwasel, B. N., Sirafi, H. and Rashid, M. (2021) IOP Conference Series: Materials Science and Engineering, 1099(1), p. 012040. doi: 10.1088/1757- 899x/1099/1/012040. [11] Thota, A., Tilak, P., Ahluwalia, S. and Lohia, N. (2018) Fake News Detection: A Deep Learning Approach, SMU Scholar. [12] Conroy, N. K., Rubin, V. L. and Chen, Y. (2015) Proceedings of the Association for Information Science and Technology, 52(1), pp. 1–4. [13] Bernhard Scholkopf and Alexander J Smola. Learning with kernels: sup- port vector machines, regularization, optimization, and beyond. Adaptive Computation and Machine Learning series, 2018. [14] A Novel Approach for Selecting Hybrid Features from Online News Textual Metadata for Fak News Detection3PGCIC2019 [15] Reis, J. C., Correia, A., Murai, F., Veloso, A. and Benevenuto, F. (2019) Proceedings of the 10th ACM Conference on Web Science. doi: 10.1145/3292522.3326027. [16] K. Nagi, \"New Social Media and Impact of Fake News on Society\", ICSSM Proc., pp. 77-96, 2018. [17] Jain, A. Shakya, H. Khatter and A. K. Gupta, \"A smart System for Fake News Detection Using Machine Learning,\" 2019 International Conference on Issues and Challenges .
Copyright
Copyright © 2023 Saurabh Srivastava, Nitasha , Akansha , Mudit Surana, Hardik Singh, Harsh Sangtani. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET56974
Publish Date : 2023-11-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online