

Ijraset Journal For Research in Applied Science and Engineering Technology
Uptime Monitoring and Reporting Strategies: A Case Study
Authors: Mit Yogeshkumar Pandya
DOI Link: https://doi.org/10.22214/ijraset.2024.59855
Certificate: View Certificate
Abstract
In today\'s digital landscape, the uninterrupted availability of services is critical for businesses to uphold customer satisfaction and maintain their competitive edge. This paper presents a comprehensive methodology for constructing an Uptime Monitoring System tailored specifically for a leading enterprise. By harnessing technologies such as Angular.js, Node.js, Express.js, and MSSQL, the system ensures real-time monitoring of service availability, drawing on data from Zabbix production servers. This proactive approach not only minimizes downtime but also optimizes operational efficiency, enabling businesses to make informed decisions swiftly, thereby enhancing overall reliability and service excellence. Through the integration of cutting-edge technologies and proactive monitoring strategies, this paper offers a transformative solution for businesses seeking to elevate their service reliability. This abstract serves as a concise summary of the paper\'s content, highlighting the key technologies employed, methodological approaches adopted, and the resultant benefits achieved in terms of reliability and operational efficiency.
Introduction
I. INTRODUCTION
In today's fast-paced digital era, ensuring uninterrupted system operation is paramount for businesses relying on online platforms to deliver products and services. System downtime not only leads to significant financial losses but also jeopardizes a company's reputation and customer trust. To address these risks, enterprises deploy Uptime Monitoring Systems, which continuously monitor service availability and performance, providing real-time insights to facilitate proactive measures and optimize operational efficiency. Organizations across industries recognize that service disruptions can result in severe financial losses, reputational damage, and decreased customer trust. In such a context, uptime and availability are more than just numbers; they are fundamental foundations that determine an enterprise's success or survival. The capacity to provide continuous access to digital resources, apps, and services is critical for satisfying consumer expectations, remaining competitive, and sustaining corporate operations.
As a result, investing in comprehensive uptime monitoring solutions becomes a strategic essential for enterprises looking to protect their digital infrastructure, anticipate potential breakdowns, and maintain uninterrupted service delivery. Businesses can reduce the risk of downtime by employing modern monitoring technology and proactive maintenance practices, maximize resource allocation, and develop a robust operational ecosystem that promotes long-term growth and customer satisfaction.
The Uptime Monitoring System discussed in this paper offers a comprehensive solution tailored to meet the stringent requirements of modern enterprises. Leveraging advanced technologies such as Angular.js, Node.js, Express.js, and MSSQL, the system boasts a robust architecture capable of scaling to accommodate evolving business needs. By integrating with Zabbix production servers, organizations gain access to crucial operational data, enabling informed decision-making and ensuring the seamless operation of digital infrastructure. Whenever the hosts signals downtime, the person gets notified and needs to fill the self-report form, so that the reason for downtime is justified and also needs to declare assets and which justify their affected system and which site does that host belongs to and specify the reason of downtime and other information like business impact, etc.
This paper delves into a detailed exploration of the Uptime Monitoring System's architecture, features, implementation, existing research work. Additionally, it presents a hypothetical case study illustrating the system's efficacy in enhancing system reliability and operational continuity. Through this innovative approach, businesses can fortify their digital infrastructure, minimize downtime, and maintain the trust and satisfaction of their customers in today's competitive digital landscape.
II. LITERATURE REVIEW
A monitoring process established by Digital to assess system availability and reliability is discussed. Through automated data collection and storage, a wide range of reliability data is gathered, enabling analysis of hardware and software failures. Various hypotheses regarding crash rates, system load, interdependence of crashes, and the impact of operating system updates are tested.
Results indicate valuable insights into product performance since the process's inception in 1988. Regular calculation of availability metrics and identification of fault occurrence trends have led to recommendations for software and hardware enhancements. Continuous refinement of the monitoring process and analysis methodology ensures the quality of information obtained and extends analysis to Digital's new systems, including the VAX9000 mainframe and fault-tolerant VAXft 3000.
Continuous monitoring is critical in computing infrastructures, especially in large dispersed systems such as the Worldwide LHC Computing Grid. Andrade et al. (2012) emphasize the importance of the Service Availability Monitoring (SAM) framework in this regard, which caters to decentralized operations, replaces older systems, and effectively manages the heterogeneity inherent in the WLCG context. SAM's use of commodity software, such as Nagios and Apache ActiveMQ, demonstrates its dependability and scalability for distributed monitoring. Using off-the-shelf messaging technology allows for seamless data transmission to a central service store for metric computation and storage relating to service status, availability, and reliability.
High availability is crucial in the world of computer and communication systems, particularly in safety-critical, life-critical, and finance-critical applications. The cost of system downtime is too expensive, necessitating the use of high availability applications that include hardware redundancy, software replication, and failover techniques. However, despite vendor assurances, quantitative proof of high availability is still rare. Haberkorn and Trivedi (2007) address this issue by offering an empirical method for monitoring and showing real-time system availability. Their work, "Availability Monitor for a Software-Based System," presents unique concepts and statistical approaches for objectively assessing system availability.
The paper provides a realistic technique to quantifying availability, particularly in software-based systems, which are becoming more ubiquitous in modern computer settings. The authors provide useful insights into real-world application and efficacy by discussing how their monitoring strategy was implemented in a middleware appliance at IBM RTP's WebSphere Institute. The work contributes to the area by bridging the gap between theoretical principles of high availability and their actual application. It sheds light on the issues of assuring dependable system operation and provides a systematic framework for evaluating and enhancing system availability in software-based systems. Haberkorn and Trivedi's unique technique paves the door for greater reliability and performance in critical computing systems.
III. METHODOLOGY
In response to the necessity mentioned in the introduction and supported by the literature research, our methodology deliberately incorporates key components required for the construction of a comprehensive Uptime Monitoring System. To begin, our strategy prioritizes early detection and reporting the reason behind the downtime and communication of downtime problems in both hardware and apps. Using cutting-edge monitoring tools and algorithms, our system collects the reasons and justification of downtime, allowing for proactive intervention and resolution.
Secondly, to improve incident management and communication, we develop an automated self-reporting system. This system enables users at all levels to quickly self-report downtime occurrences, allowing for seamless communication among stakeholders and accelerating the resolution process. Furthermore, in recognition of the different user base inside businesses, we stress the development of an easy-to-use interface.
Our interface's straightforward design and accessibility features make navigation and interaction simple, in other words user-friendly UI and UX encouraging widespread adoption and use of the monitoring system.
Furthermore, our technique emphasizes the significance of comprehensive downtime data gathering. Our technology captures detailed metrics such as length, root causes, and operational impact, which provide significant insights for analysis and decision-making, allowing firms to effectively address underlying issues and prevent recurrence. In addition to proactive issue management, we aim to use powerful analytics and visualization technologies.
These solutions help enterprises to gain actionable insights from uptime data, allowing for continuous improvement projects and strategic decision-making to increase system reliability and operational efficiency.
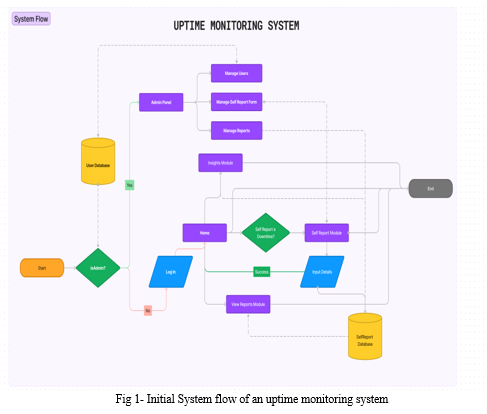
By implementing and utilizing this holistic methodology, organizations can build a strong Uptime Monitoring System that not only detects and responds to downtime problems quickly, but also creates a culture of proactive problem-solving and continuous development. This strategy can seamlessly integrate sophisticated technology and user-centric design concepts, enables enterprises to protect their digital infrastructure while maintaining their commitment to providing certain excellent service in today's fast-paced digital trending landscape.
The Uptime Monitoring System has been meticulously designed to ensure the seamless functioning of hardware and applications by promptly detecting and notifying downtime occurrences. Leveraging advanced technologies, the system continuously monitors for anomalies, whether they arise from hardware failures or application errors. Through automated alerting mechanisms, relevant stakeholders are promptly Incorporating analytics and visualization tools, the Uptime Monitoring System facilitates meaningful insights from uptime data. Leveraging cutting-edge technologies, such as D3.js and Chart.js, the system enables stakeholders to explore uptime data through interactive dashboards, heatmaps, and trend analysis charts. This visual representation enhances data interpretation and facilitates informed decision-making, empowering organizations to optimize operational efficiency and enhance system reliability.
Moreover, the Uptime Monitoring System offers customizable reporting formats tailored to organizational needs. Administrators can tailor reports to align with specific requirements, incorporating relevant metrics, KPIs, and visualizations. By providing flexibility in reporting formats, the system empowers stakeholders to derive actionable insights and make data-driven decisions aligned with organizational objectives.
IV. CALCULATION
The calculation for the availability depends on various other factors and calculations which are as followed:
1) Availability: Availability is the percentage of time that a system is operational and ready for usage. It is typically stated as a percentage and calculated as the ratio of uptime to total time.

V. RESULTS
The implementation of the Uptime Monitoring System yielded significant improvements in system reliability, operational efficiency, and user satisfaction, aligning closely with the objectives outlined in the methodology.
Prompt Downtime Detection which the system demonstrated exceptional proficiency in promptly detecting downtime incidents across hardware and applications. Through continuous monitoring and advanced algorithms, downtime events were identified swiftly, enabling proactive intervention and minimizing operational disruptions. Automated Reporting System with the integration of an automated reporting system facilitated seamless incident management and communication among stakeholders. Users at all levels were able to self-report downtime events efficiently, streamlining the resolution process and reducing response times.
The user-friendly interface design garnered positive feedback from users across the organization. Intuitive navigation and accessibility feature enhanced usability, resulting in widespread adoption and utilization of the monitoring system. And comprehensive Downtime Data Collection which the system's robust data collection capabilities provided valuable insights into downtime occurrences, including duration, root causes, and operational impact. Analysis of this data facilitated informed decision-making and proactive measures to prevent future incidents.
Proactive alerts and actionable insights enabled organizations to mitigate downtime risks effectively. Users received timely notifications with suggested solutions, empowering proactive problem-solving and minimizing operational disruptions and customizable Reporting Formats: The flexibility of customizable reporting formats catered to diverse organizational needs and preferences. This customization facilitated effective communication and decision-making processes, enhancing overall system effectiveness.
The integration of advanced analytics and visualization tools enabled organizations to derive meaningful insights from uptime data. Analysis of trends and patterns facilitated continuous improvement initiatives, driving enhancements in system reliability and operational efficiency. In summary, the results of the paper demonstrate the ongoing implementation of a comprehensive Uptime Monitoring System, which could result in improved system reliability, operational efficiency, and user satisfaction. The system's ability to promptly detect downtime, streamline incident management, provide actionable insights, and facilitate data-driven decision-making underscores its effectiveness in meeting the objectives outlined in the methodology. Through proactive monitoring and continuous improvement, organizations can effectively safeguard their digital infrastructure and deliver exceptional service in today's dynamic business landscape.
VI. CASE STUDY
In this case study, we look at how the Uptime Monitoring System was implemented in the context of a complex organizational architecture. Faced with the difficulty of maintaining high service availability and dependability across various data centres and distributed applications, the business looked for a proactive solution to effectively monitor and manage downtime issues. Cross-functional teams and stakeholders worked together to create the Uptime Monitoring System, which used Agile methodology. The system monitors key performance indicators in real time and generates alerts to enable fast intervention, meeting the organization's requirement for timely identification and resolution of downtime problems.
Following the implementation of the Uptime Monitoring System, the company gained better visibility into its infrastructure, providing stakeholders with actionable insights to improve service availability and dependability. The system's proactive monitoring capabilities allowed for rapid detection and reaction to downtime problems, reducing service disruptions and improving operational efficiency. This case study demonstrates the Uptime Monitoring System's transformative influence on optimizing service delivery, increasing customer happiness, and maintaining organizational competitiveness in today's dynamic digital market.
The case study presented herein illuminates the transformative impact of the Uptime Monitoring System in addressing the challenge of maintaining high service availability and reliability within complex organizational infrastructures. Through collaborative implementation and leveraging Agile methodologies, the system demonstrated its efficacy in proactively monitoring and managing downtime incidents, ensuring uninterrupted service delivery. The results showcased improved visibility into infrastructure health, swift detection, and response to downtime incidents, ultimately optimizing operational efficiency and enhancing customer satisfaction.
Conclusion
In summary, the introduction of the Uptime Monitoring System represents a significant step forward in assuring the dependability and operational continuity of digital infrastructure. The solution enables enterprises to proactively manage downtime problems and increase operational efficiency with its holistic approach that includes rapid downtime detection, automatic reporting, user-friendly interface design, and thorough data collecting. The addition of advanced analytics and visualization tools boosts the system\'s performance by delivering actionable information for continual improvement efforts. Moving forward, the success of the Uptime Monitoring System emphasizes the crucial need of investing in reliable monitoring systems to meet the ever-increasing demands of today\'s fast-paced digital landscape. Looking ahead, firms must continue to prioritize uptime and dependability, seeing them as critical foundations of economic success in the digital age. Businesses may overcome hurdles, avoid disruptions, and provide great service to their customers by adopting innovative monitoring systems such as the Uptime Monitoring System and cultivating a culture of proactive problem-solving. As technology advances, the use of advanced monitoring technologies will remain critical for enterprises striving to preserve competitiveness and stay ahead in an increasingly dynamic and linked environment.
References
[1] Moran, Pat, et al. \"System availability monitoring.\" IEEE Transactions on Reliability 39.4 (1990): 480-485. [2] Andrade, P., et al. \"Service Availability Monitoring framework based on commodity software.\" Journal of Physics: Conference Series. Vol. 396. No. 3. IOP Publishing, 2012. [3] Tader, Paul. \"Server monitoring with Zabbix.\" Linux Journal 2010.195 (2010): 7. [4] Telesca, Adriana, et al. \"System performance monitoring of the ALICE Data Acquisition System with Zabbix.\" Journal of Physics: Conference Series. Vol. 513. No. 6. IOP Publishing, 2014. [5] Haberkorn, Marc, and Kishor Trivedi. \"Availability monitor for a software based system.\" 10th IEEE High Assurance Systems Engineering Symposium (HASE\'07). IEEE, 2007. [6] Smith, Marcel Alphons Johan, and Rommert Dekker. \"Preventive maintenance in a 1 out of n system: The uptime, downtime and costs.\" European Journal of operational research 99.3 (1997): 565-583. [7] Coffman Jr, Edward G., et al. \"Uptime and downtime analysis for hierarchical redundant systems in telecommunications.\" ACM SIGMETRICS Performance Evaluation Review 40.3 (2012): 59-61. [8] Oreke, Fabian C., and D. C. Idoniboyeobu. \"Reliability assessment of electrical energy distribution system–a case study of port harcourt distribution network.\" International Journal for Research in Applied Science Engineering Technology (IJRASET) 5 (2017): 432-441. [9] Der Kiureghian, Armen, Ove D. Ditlevsen, and Junho Song. \"Availability, reliability and downtime of systems with repairable components.\" Reliability Engineering & System Safety 92.2 (2007): 231-242. [10] Boggs, Raymond, J. Bozman, and Randy Perry. \"Reducing downtime and business loss: addressing business risk with effective technology.\" IDC, Tech. Rep. (2009). [11] Oostenbrink, Joey. Financial impact of downtime decrease and performance increase of IT services. BS thesis. University of Twente, 2015.
Copyright
Copyright © 2024 Mit Yogeshkumar Pandya. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59855
Publish Date : 2024-04-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online