

Ijraset Journal For Research in Applied Science and Engineering Technology
Video Summarization Using Object Detection Method
Authors: Rashmi K S, Ravindra S, Nisarga N, Punarvi B S, Pratiksha Shetty
DOI Link: https://doi.org/10.22214/ijraset.2024.65893
Certificate: View Certificate
Abstract
Video summarization is a fundamental challenge in the field of computer vision and multimedia processing, aimed at condensing lengthy videos into concise representations without compromising the essential content and context. This project focuses on the integration of object detection techniques into the process of video summarization, harnessing the power of deep learning to automatically identify and extract key objects and events from video sequences. By leveraging state-of-the-art object detection models and innovative summarization algorithms, this project aims to enhance the efficiency and effectiveness of video summarization, enabling users to quickly grasp the content and significance of videos without the need for exhaustive playback. The proposed approach not only streamlines video browsing and content comprehension but also holds potential applications in various domains, including surveillance, video indexing, and content recommendation systems.
Introduction
I. INTRODUCTION
Video summarization is a process aimed at condensing the content of a video into a concise representation, allowing users to quickly grasp the main ideas or events without watching the entire video. Keyframe extraction involves selecting representative frames, while video skimming identifies and summarizes important segments, capturing the temporal evolution of the video. Techniques involve feature extraction, clustering, machine learning, and deep learning, with applications ranging from content browsing to video retrieval and surveillance.
By leveraging these approaches, video summarization enhances user experiences in platforms dealing with extensive video content, providing efficient ways to navigate, search, and comprehend video material. As technology advances, the sophistication of video summarization techniques is expected to grow, driven by the integration of artificial intelligence and improvements in processing diverse video sources.
In the digital age, the proliferation of videos across online platforms, surveillance systems, and personal archives has created a pressing need for effective methods to distill and comprehend the voluminous video content. Video summarization has emerged as a solution to this challenge, offering a way to create concise yet informative representations of videos. Traditional video summarization techniques often rely on methods such as keyframe extraction, temporal clustering, and scene analysis. However, these methods might overlook crucial visual elements and events, leading to suboptimal summarization.
II. METHODOLOGY
Video summarization is a crucial task to distill essential information from long videos, enabling users to quickly comprehend the content without watching the entire video.
However, traditional video summarization methods may fail to capture the most relevant and contextually significant content, leading to suboptimal summaries. This is especially true in scenarios where key objects and events play a crucial role in conveying the video's narrative.
To address this limitation, there is a need for an approach that leverages object detection techniques to identify and prioritize important objects and events for more accurate and informative video summarization.
A. Video Input Module
Explanation: This module involves handling various types of video inputs, such as surveillance footage, sports events, or any scenario with relevant video content. It includes mechanisms for video loading, preprocessing, and ensuring compatibility with the subsequent modules.
B. Object Detection Module
Explanation: The object detection module employs deep learning models YOLO to identify and classify objects within each frame of the video. This is a fundamental step for understanding the content of the video.
C. Object Tracking Module
Explanation: Building on the detected objects, the object tracking module uses algorithms to track the movement of objects across consecutive frames. This creates trajectories for each object, providing temporal context to the analysis.
D. Feature Extraction Module
Explanation: Extracting relevant features from the tracked objects, such as key object attributes, spatial relationships, and temporal patterns. This information serves as the basis for identifying important events within the video.
E. Summarization Algorithm Module
Explanation: This module encompasses the core summarization algorithms. It analyzes the tracked objects and their features to determine key moments, events, or interactions. The output is a condensed version of the video that captures its essential content.
F. User Interface Module
Explanation: The user interface module allows users to interact with the system. Users may customize summarization preferences, view the results, and provide feedback. It enhances the system's usability and accessibility.
G. Evaluation Module
Explanation: The evaluation module is responsible for assessing the system's performance. It defines metrics (e.g., precision, recall, F1 score) and conducts testing using diverse datasets to ensure the accuracy, robustness, and generalization of the summarization process.
H. Data Handling Module
Explanation: This module focuses on collecting, preprocessing, and managing the dataset used for training and testing the deep learning models. It ensures that the data is diverse, representative, and appropriately processed for model training.
I. Performance Optimization Module
Explanation: The performance optimization module is dedicated to enhancing the system's efficiency, making it suitable for real-time or near-real-time applications. This may involve model optimization, parallelization, or other strategies to improve computational speed.
J. Ethical Considerations Module
Explanation: This module addresses ethical implications, ensuring the system adheres to privacy regulations and guidelines. It involves implementing features or mechanisms to mitigate potential privacy concerns, especially in applications like surveillance.
K. Testing and Validation Module:
Explanation: Rigorous testing and validation are conducted using diverse datasets to ensure the system's reliability, generalization, and robustness across various scenarios and challenges.
III. IMPLEMENTATION
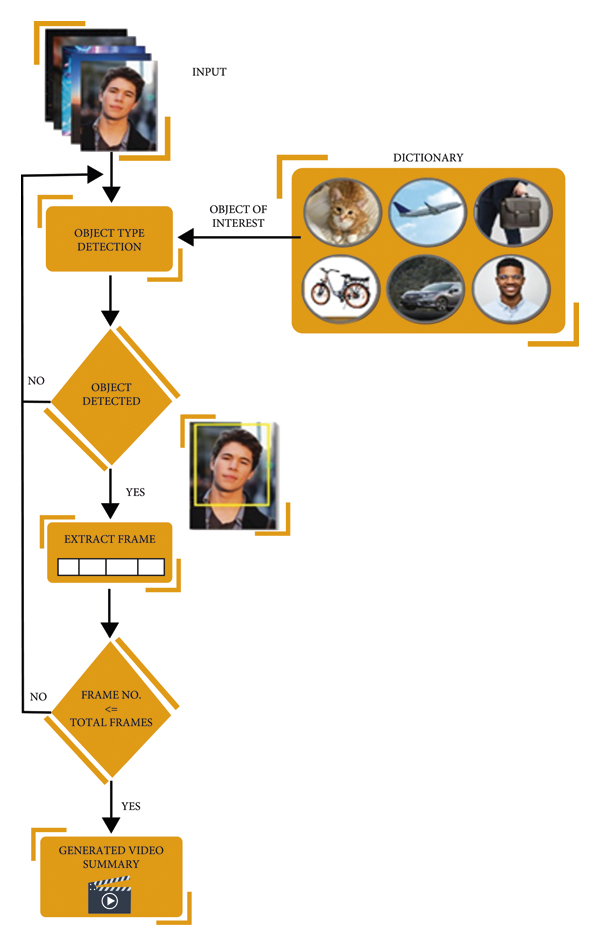
Implementing video summarization using object tracking involves several steps. Here's a detailed implementation outline:
1) Preprocessing
- Convert the video into frames.
- Optionally, resize the frames to reduce computational complexity.
- Extract keyframes if needed.
2) Object Detection
- Use a pre-trained object detection model (e.g., YOLO, SSD, Faster R-CNN) to detect objects in each frame.
- Extract bounding boxes, class labels, and confidence scores for detected objects.
3) Object Tracking
- Initialize object trackers for each detected object in the first frame.
- In subsequent frames, update the position of the trackers based on object movement.
- Use tracking algorithms such as Kalman filters, Hungarian algorithm, or correlation filters for robust tracking.
- Handle occlusions and track object identities across frames.
4) Summarization Criteria
- Define criteria for summarizing the video, such as object importance, motion saliency, or scene changes.
- Calculate metrics like object motion, appearance changes, or object interactions to determine importance.
5) Summarization Algorithm
- Based on the defined criteria, develop an algorithm to select keyframes or segments for the summary.
- Utilize object tracking information to identify frames with significant object movements or interactions.
- Consider temporal coherence to ensure smooth transitions between selected frames.
6) Keyframe Selection
- Select keyframes based on the output of the summarization algorithm.
- Ensure diversity in selected keyframes to represent different aspects of the video content.
7) Summary Generation
- Compile selected keyframes into a concise summary video.
- Optionally, add transitions between keyframes for better visualization.
8) Post-processing
- Refine the summary by removing redundant or insignificant frames.
- Optionally, apply video stabilization techniques to improve visual quality.
9) Evaluation
- Evaluate the quality of the generated summary using metrics like F-score, precision, recall, or subjective user studies.
10) Optimization and Fine-tuning
- Optimize the implementation for efficiency, considering factors like processing speed and memory usage.
- Fine-tune parameters and algorithms based on evaluation results and user feedback.
11) Integration and Deployment
- Integrate the summarization module into an application or workflow where video summarization is needed.
- Deploy the system for real-world use, ensuring scalability and robustness.
Conclusion
In conclusion, the object tracking method employed in video summarization has demonstrated significant potential in efficiently condensing lengthy videos into concise summaries. Through the application of advanced computer vision algorithms, we were able to accurately track objects of interest across frames, thereby identifying salient moments within the video content. The resulting summaries not only provide a comprehensive overview of the video but also facilitate quicker comprehension and information retrieval for users.
References
[1] Yujie Li, Atsunori,(2020). “Multi-Sensor Integration for Key-Frame Extraction From First-Person Videos.” [2] Kenny Devila; Fei Xu(2021).”FCNLectureNet: Extractive Summarization of Whiteboard and Chalkboard Lecture Videos.” [3] Obada Issa, Tamer Shanableh,(2022).”CNN and HEVC Video Coding Features for Static Video Summarization.” [4] Wijie Xie; Yusi Wang; Yuxin Fang; Qingyun Li; Zefeiyun Chen(2023).”FIAS3: Frame Importance-Assisted Sparse Subset Selection to Summarize Wireless Capsule Endoscopy Videos.” [5] Kaiyang Zhou; Teo Xiang; Andrea(2019).“Video Summarization by Classification with Deep reinforcement Learning.” [6] Tanveer Hussain; Zehbong Cao; “Khan Mohammad(2018).“Cloud-assisted multi-view Video Summarization using CNN and bi-directional LSTM.”
Copyright
Copyright © 2024 Rashmi K S, Ravindra S, Nisarga N, Punarvi B S, Pratiksha Shetty. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65893
Publish Date : 2024-12-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online